Einleitung
- Persönliche Einführung in das Thema und Relevanz der Ausreißer-Erkennung.
- Kurze Definition von Ausreißern und deren Auswirkungen auf Modelle.
- Überblick über Forecasting und dessen Stellenwert im Machine Learning.
- Die Herausforderung von Ausreißern im Kontext von Prognosemodellen.
- Warum Ausreißer-Erkennung entscheidend für die Modellleistung ist.
- Vorschau auf die Struktur des Artikels und die zu diskutierenden Themen.
Als jemand, der sich tief mit der Welt des Machine Learning und insbesondere mit der Vorhersage zukünftiger Trends und Muster beschäftigt hat, weiß ich, dass die Genauigkeit von Prognosen nicht nur auf der Raffinesse der verwendeten Algorithmen beruht, sondern auch auf der Qualität der Daten, die ihnen zugeführt werden. Ein kritischer Aspekt dieser Datenqualität ist die Erkennung und Behandlung von Ausreißern, jenen Datenpunkten, die von den üblichen Mustern abweichen. In diesem Blog-Artikel möchte ich die Relevanz der Ausreißer-Erkennung im Kontext des Forecasting mittels Machine Learning beleuchten.
Ausreißer sind Beobachtungen, die so weit von anderen Beobachtungen entfernt sind, dass der Verdacht besteht, sie entstammen einem anderen Mechanismus. In einer Welt, in der Daten oft als das neue Öl bezeichnet werden, können Ausreißer mit Verunreinigungen verglichen werden, die den Motor eines ansonsten gut geölten Prognosemodells beschädigen können. Sie können das Ergebnis von Fehlern in den Daten sein, aber auch echte Anomalien darstellen, die wertvolle Einsichten bieten. Die Kunst besteht darin, zwischen diesen beiden Möglichkeiten zu unterscheiden und entsprechend zu handeln.
Forecasting, das Erstellen von Vorhersagen über zukünftige Ereignisse basierend auf historischen Daten, ist ein zentrales Element des Machine Learnings. Es ist unerlässlich in Bereichen wie Finanzmarktanalysen, Wettervorhersage, Energieverbrauchsschätzungen und vielen anderen. Der Stellenwert von Prognosen im Machine Learning kann kaum überbewertet werden; sie informieren Entscheidungen in fast jedem Sektor der Wirtschaft und Wissenschaft.
Ausreißer können in Prognosemodellen eine besondere Herausforderung darstellen. Sie können die Parameter von Vorhersagemodellen verzerren und zu überoptimistischen oder pessimistischen Prognosen führen. Die Fähigkeit, Ausreißer zu erkennen und korrekt zu behandeln, ist daher entscheidend für die Leistung eines jeden Forecasting-Modells. Wenn Ausreißer unerkannt bleiben, können sie die Modellleistung erheblich beeinträchtigen, indem sie die Modellannahmen stören und die Prognosegenauigkeit reduzieren.
In diesem Artikel werde ich zunächst die verschiedenen Arten von Ausreißern und die Methoden zu ihrer Erkennung vorstellen. Danach werde ich detailliert auf die verschiedenen Forecasting-Methoden im Machine Learning eingehen und aufzeigen, wie die Ausreißererkennung in diesen Kontext passt. Es folgt ein Vergleich der Methoden in einer Matrix, der die Stärken und Schwächen jeder Methode hervorhebt. Schließlich werde ich meine persönliche Einschätzung darüber abgeben, welche Methoden am besten geeignet sind, um die Qualität von Prognosemodellen zu sichern und zu verbessern. Mit diesem Artikel möchte ich ein tieferes Verständnis für die Bedeutung der Ausreißer-Erkennung im Forecasting-Prozess schaffen und die Leser mit dem notwendigen Wissen ausstatten, um ihre eigenen Modelle zu verfeinern.
Grundlagen der Ausreißer-Erkennung
- Definition und Arten von Ausreißern (Punkt-, Kontext- und kollektive Ausreißer).
- Ursachen für Ausreißer (Datenfehler, natürliche Variabilität, etc.).
- Die Auswirkung von Ausreißern auf statistische Analysen.
- Verschiedene Ansätze zur Ausreißer-Erkennung (statistische Tests, Distanz- und Dichtemethoden, usw.).
- Vor- und Nachteile von Modell-basierten vs. datenbasierten Ausreißer-Erkennungsmethoden.
Im Herzen der Datenwissenschaft liegt das Verständnis dafür, dass nicht alle Daten gleich geschaffen sind. Manche Datenpunkte tanzen aus der Reihe – wir nennen sie Ausreißer. Doch bevor wir tiefer in die Materie eintauchen, lassen Sie mich die Grundlagen dieser ungewöhnlichen Beobachtungen erklären.
Ausreißer sind einzelne Datenpunkte, die sich deutlich von der Mehrheit der Daten in einem Datensatz unterscheiden. Sie fallen in drei Hauptkategorien: Punkt-Ausreißer, Kontext-Ausreißer und kollektive Ausreißer. Punkt-Ausreißer sind einzelne Datenpunkte, die weit abseits liegen. Kontext-Ausreißer sind Datenpunkte, die in einem bestimmten Kontext – vielleicht in einer bestimmten Zeit oder unter bestimmten Bedingungen – ungewöhnlich sind. Kollektive Ausreißer sind Gruppen von Datenpunkten, die im Vergleich zum gesamten Datensatz ungewöhnlich erscheinen, obwohl die einzelnen Punkte für sich genommen nicht ungewöhnlich sein müssen.
Die Ursachen für Ausreißer sind vielfältig. Sie können das Ergebnis eines Messfehlers sein, wie etwa eines Tippfehlers bei der Dateneingabe oder eines Fehlers im Messgerät. Sie können aber auch echte Phänomene widerspiegeln, wie etwa eine plötzliche Marktveränderung oder eine ungewöhnliche Wetterbedingung. Die Unterscheidung zwischen diesen Ursachen kann herausfordernd sein, ist aber für die korrekte Behandlung von Ausreißern entscheidend.
Ausreißer können statistische Analysen beeinträchtigen, da viele statistische Methoden von der Annahme ausgehen, dass die Daten einer bestimmten Verteilung folgen. Ausreißer können Mittelwerte verzerren, die Varianz aufblähen und Korrelationen verfälschen, was zu irreführenden Schlussfolgerungen führen kann.
Es gibt verschiedene Ansätze zur Ausreißer-Erkennung. Statistische Tests, wie Grubbs‘ Test oder der Dixon’s Q-Test, suchen nach extremen Werten. Distanzbasierte Methoden, wie das k-nearest neighbors (k-NN), identifizieren Ausreißer, indem sie die Distanz eines Punktes zu seinen Nachbarn betrachten. Dichtebasierte Methoden, wie der DBSCAN-Algorithmus, suchen nach Bereichen geringer Datendichte. Dann gibt es noch modellbasierte Ansätze, die annehmen, dass die Daten einer bestimmten Verteilung folgen, und Punkte identifizieren, die nicht zu diesem Modell passen.
Jede Methode hat ihre Vor- und Nachteile. Modellbasierte Ansätze sind leistungsstark, wenn die Modellannahmen korrekt sind, können aber bei falschen Annahmen irreführend sein. Datenbasierte Methoden sind flexibler, da sie keine strikten Annahmen über die Daten machen, können aber durch die Wahl von Parametern, wie die Anzahl der Nachbarn in k-NN, beeinflusst werden.
Das Verständnis dieser Grundlagen ist der erste Schritt, um die subtilen Nuancen der Ausreißer-Erkennung zu meistern. Im nächsten Abschnitt werden wir uns darauf konzentrieren, wie diese Konzepte in die Praxis umgesetzt werden, um robuste Forecasting-Modelle im Machine Learning zu erstellen.
Forecasting mit Machine Learning
- Einführung in Machine Learning-Modelle für das Forecasting.
- Die Bedeutung von Datenvorbereitung und -bereinigung.
- Wie Ausreißer Forecasting-Modelle beeinflussen können.
- Beispiele für Prognosemodelle (Zeitreihenanalyse, neuronale Netze, usw.).
- Anpassung von Modellen an saubere vs. unreine Daten.
Forecasting, oder die Kunst der Vorhersage, ist eine Domäne, in der Machine Learning (ML) eine entscheidende Rolle spielt. ML-Modelle, die für Prognosen entwickelt wurden, sind darauf ausgerichtet, Muster und Trends in historischen Daten zu erkennen und diese Erkenntnisse zu nutzen, um zukünftige Ereignisse vorherzusagen. Diese Modelle reichen von einfachen linearen Regressionen bis hin zu komplexen neuronalen Netzen und können in einer Vielzahl von Anwendungen eingesetzt werden, von der Vorhersage von Aktienkursen bis hin zur Wettervorhersage.
Die Datenvorbereitung ist ein entscheidender Schritt auf dem Weg zu einem effektiven Forecasting-Modell. Saubere Daten verbessern nicht nur die Genauigkeit der Vorhersagen, sondern sorgen auch dafür, dass die daraus resultierenden Einsichten valide sind. Datenbereinigung umfasst das Entfernen oder Korrigieren von fehlerhaften Datenpunkten, das Füllen von Lücken in Datensätzen und das Glätten von Rauschen, um die wahren Signale in den Daten hervorzuheben.
Ausreißer können Forecasting-Modelle auf mehrere Arten beeinflussen. Sie können zu übertrainierten Modellen führen, die auf das Rauschen statt auf das Signal reagieren, oder zu untertrainierten Modellen, die wichtige Informationen übersehen. In beiden Fällen leidet die Vorhersagegenauigkeit. Die Identifikation und angemessene Behandlung von Ausreißern ist daher ein zentrales Anliegen bei der Vorbereitung von Daten für das Forecasting.
Lassen Sie uns einige der Prognosemodelle betrachten, die in der Praxis verwendet werden. Zeitreihenanalysen, wie das ARIMA-Modell (AutoRegressive Integrated Moving Average), sind klassische Beispiele, die speziell für Daten entwickelt wurden, die über einen Zeitverlauf gesammelt wurden. Neuronale Netze, einschließlich tiefer Lernmodelle wie das Long Short-Term Memory (LSTM), sind besonders gut in der Verarbeitung und Vorhersage von Mustern in komplexen Datensätzen, die für traditionelle statistische Methoden zu schwierig sind.
Die Anpassung von Modellen an saubere Daten gegenüber unreinen Daten ist eine Herausforderung. Modelle, die auf sauberen Daten trainiert wurden, tendieren dazu, besser zu generalisieren und zuverlässigere Vorhersagen zu liefern. Unreine Daten können zu einer Vielzahl von Problemen führen, darunter die Überanpassung an die Ausreißer und die Vernachlässigung der eigentlichen Trends und Muster, die für präzise Vorhersagen notwendig sind.
Zusammenfassend lässt sich sagen, dass die sorgfältige Vorbereitung und Bereinigung von Daten vor der Anwendung von Machine Learning-Modellen für das Forecasting von entscheidender Bedeutung ist. Die Wahl des richtigen Modells, das Verständnis seiner Stärken und Schwächen und die Kenntnis darüber, wie Ausreißer behandelt werden können, sind Schlüsselfaktoren für den Erfolg in der Welt der Vorhersagen. Im nächsten Kapitel werden wir uns ansehen, wie verschiedene Methoden der Ausreißererkennung diese Herausforderungen meistern können.
Methoden der Ausreißer-Erkennung im Machine Learning
- Detaillierte Darstellung verschiedener Methoden (z.B. Boxplot, Z-Score, IQR, Isolation Forest).
- Vorstellung von Machine Learning-Methoden speziell für Ausreißer-Erkennung (z.B. Autoencoder).
- Diskussion der Effektivität dieser Methoden in Bezug auf unterschiedliche Datentypen.
- Herausforderungen bei der Ausreißer-Erkennung in großen Datensätzen.
Detaillierte Darstellung verschiedener Methoden
In der Ausreißererkennung kommen unterschiedliche Methoden zum Einsatz, die sich in ihrer Herangehensweise und Komplexität unterscheiden. Jede Methode hat spezifische Stärken und Anwendungsbereiche, und die Wahl der passenden Methode hängt oft von der Natur der Daten und dem Kontext der Analyse ab. Lassen Sie uns einen detaillierten Blick auf einige der gängigsten Methoden werfen:
(A) Basierend auf Standardabweichung
Die Standardabweichungsmethode und die Z-Score-Methode hängen eng miteinander zusammen, da beide auf der Verwendung der Standardabweichung beruhen, um Ausreißer zu identifizieren.
Standardabweichungsmethode
- Definition und Anwendung: Der Z-Score ist eine statistische Metrik, die misst, wie viele Standardabweichungen ein Datenpunkt vom Mittelwert entfernt ist. Ein hoher Z-Score (typischerweise über 3 oder unter -3) deutet auf einen potenziellen Ausreißer hin.
- Stärken: Einfach zu berechnen; basiert auf soliden statistischen Prinzipien; gut für Daten, die annähernd normalverteilt sind.
- Schwächen: Kann bei nicht normalverteilten Daten in die Irre führen; empfindlich gegenüber Stichprobengröße.
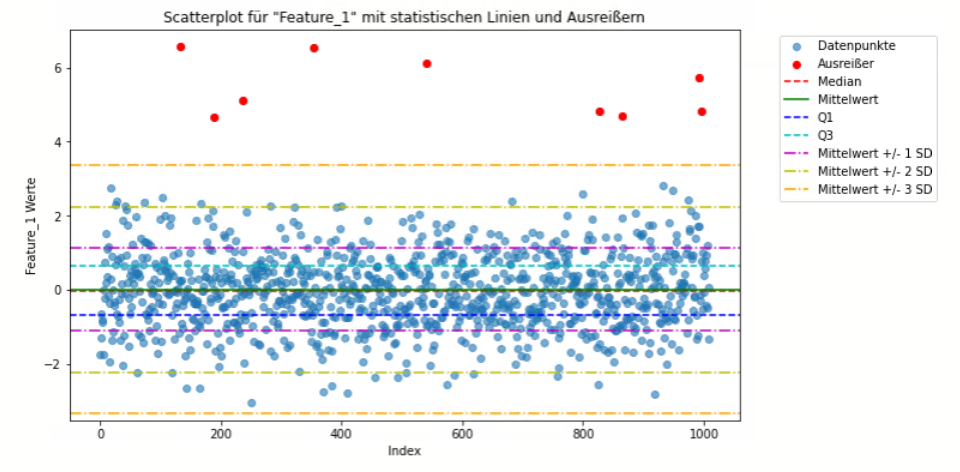
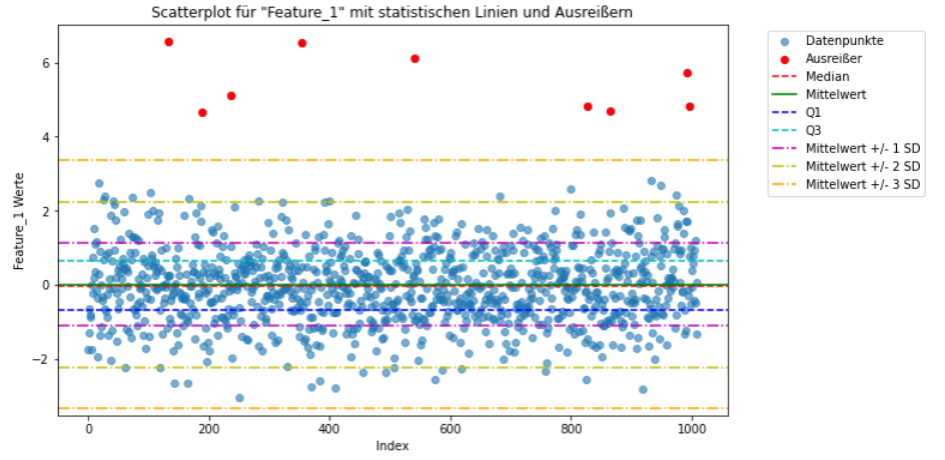
Z-Score-Methode
- Definition und Anwendung: Diese Methode verwendet die Standardabweichung, ein Maß für die Streuung der Daten, um Ausreißer zu identifizieren. Ein Datenpunkt wird als Ausreißer betrachtet, wenn er eine bestimmte Anzahl von Standardabweichungen vom Mittelwert entfernt ist. Häufig werden Schwellenwerte von 2 oder 3 Standardabweichungen verwendet.
- Stärken: Einfach zu implementieren und zu verstehen; basiert auf statistischen Grundlagen.
- Schwächen: Nicht robust gegenüber Ausreißern, da diese die Berechnung von Mittelwert und Standardabweichung beeinflussen können; setzt eine annähernde Normalverteilung der Daten voraus
Vergleich der Standardabweichungsmethode und Z-Score-Methode
Die Hauptunterschiede und Verbindungen beider Methoden sieht folgedermaßen aus:
- Z-Score-Methode:
- Der Z-Score eines Datenpunkts ist definiert als die Anzahl der Standardabweichungen, die der Wert vom Mittelwert der Daten entfernt ist.
- Ein Z-Score wird berechnet, indem die Differenz zwischen dem Datenpunkt und dem Mittelwert durch die Standardabweichung der Daten geteilt wird.
- Ausreißer können identifiziert werden, indem man nach Datenpunkten sucht, deren Z-Score einen bestimmten Schwellenwert überschreitet (oft werden Werte von 2 oder 3 verwendet).
- Standardabweichungsmethode:
- Diese Methode betrachtet Datenpunkte als Ausreißer, wenn sie eine bestimmte Anzahl von Standardabweichungen vom Mittelwert der Daten entfernt sind.
- Im Gegensatz zur Z-Score-Methode, die eine standardisierte Maßeinheit verwendet, kann die Standardabweichungsmethode direkt auf die Daten angewendet werden, ohne diese zu standardisieren.
Beide Methoden sind insofern ähnlich, als dass sie die Standardabweichung als Maß für die Variabilität der Daten nutzen. Der Z-Score ist jedoch eine standardisierte Maßeinheit, die es ermöglicht, die Position eines Datenpunkts im Verhältnis zum Mittelwert unabhängig von der Einheit der Messung oder der Skalierung der Daten zu verstehen. Dadurch ist der Z-Score besonders nützlich, wenn man Ausreißer über verschiedene Datensätze oder Features hinweg vergleichen möchte, die unterschiedliche Maßstäbe und Verteilungen haben. Die Standardabweichungsmethode ist einfacher und direkter, erfordert aber, dass die Daten ungefähr normalverteilt sind, um effektiv zu sein.
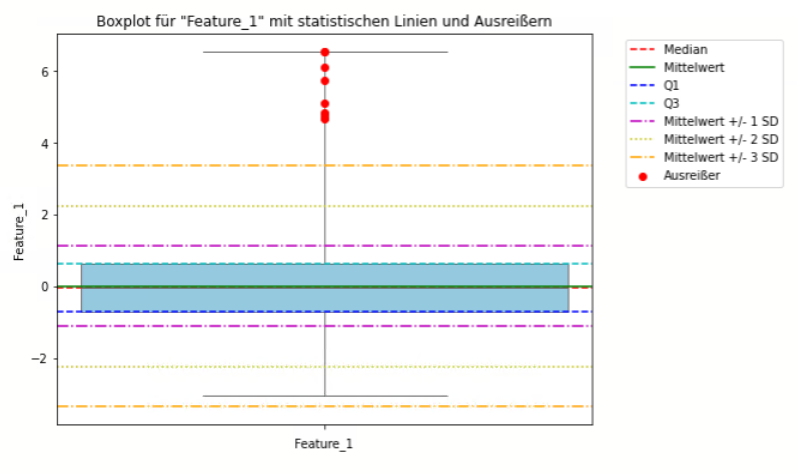
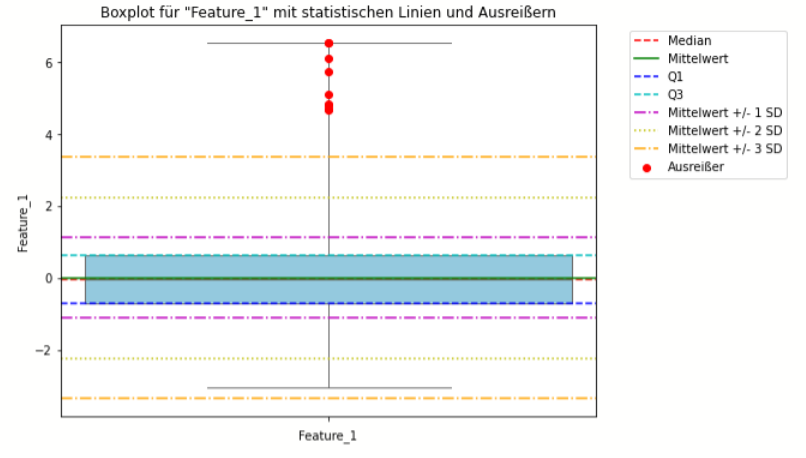
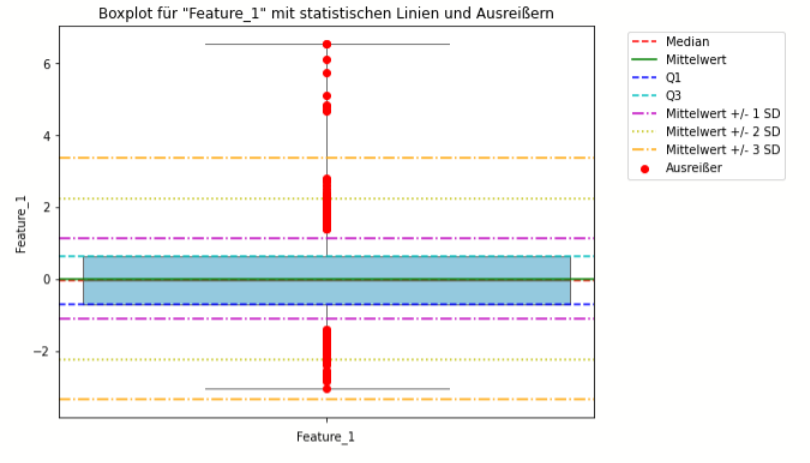
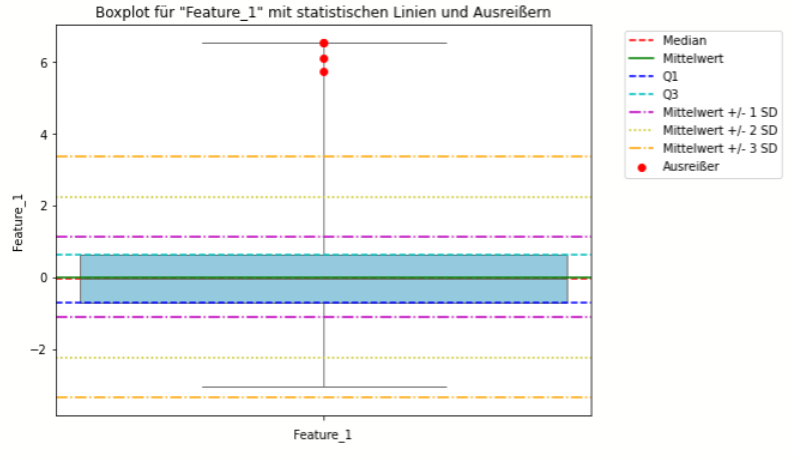
(B) Boxplot und Interquartilbereich
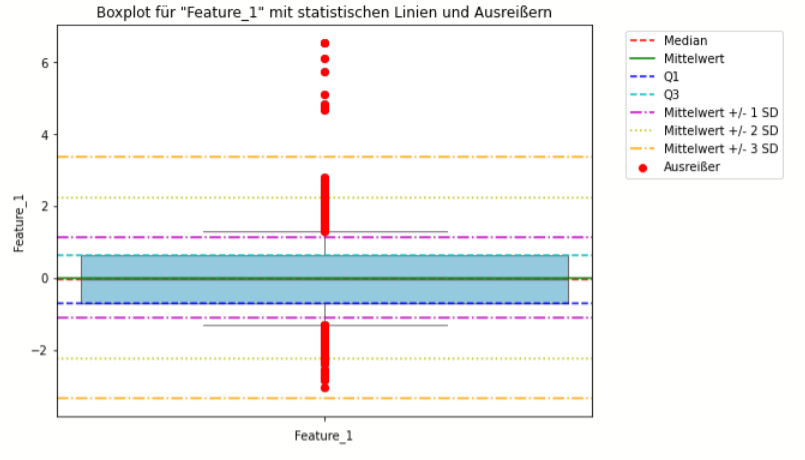
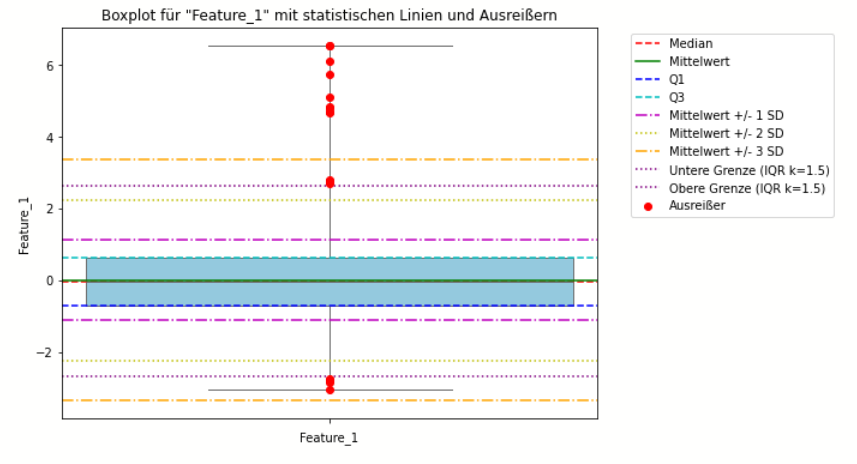
Boxplot-Methode
- Definition und Anwendung: Der Boxplot, auch bekannt als Box-Whisker-Plot, ist eine grafische Darstellung, die auf dem Konzept der Quartile basiert. Er visualisiert den Median, die Quartile und die Schwankungsbreite der Daten und ist besonders effektiv bei der Identifikation von Punkt-Ausreißern.
- Stärken: Einfach zu erstellen und zu interpretieren; benötigt keine komplexen Berechnungen; gut für explorative Datenanalyse.
- Schwächen: Nicht ideal für hochdimensionale Daten; Kontext-Ausreißer und kollektive Ausreißer können übersehen werden.
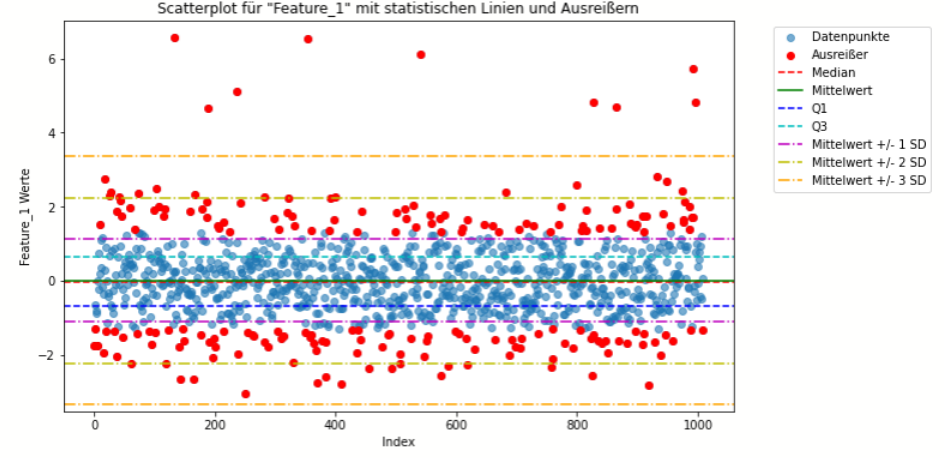
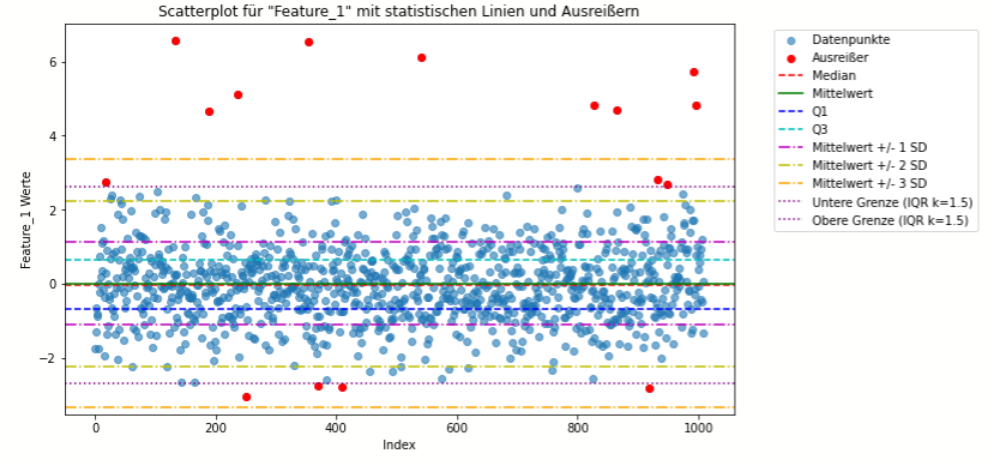
Interquartilbereich (IQR)
- Definition und Anwendung: Der Interquartilbereich ist die Spannweite zwischen dem ersten (25%) und dem dritten Quartil (75%) der Daten. Datenpunkte, die 1,5 (oder ein anderes, gewähltes Vielfaches) IQRs über dem dritten Quartil oder unter dem ersten Quartil liegen, werden als Ausreißer betrachtet.
- Stärken: Robust gegenüber nicht normalverteilten Daten; einfach zu berechnen und zu interpretieren.
- Schwächen: Kann in multimodalen Verteilungen zu Fehlinterpretationen führen; nicht geeignet für hohe Dimensionalität.
Unterschiede und Gemeinsamkeiten von Boxplot und IQR
Der Boxplot und der Interquartilbereich (IQR) sind eng miteinander verbunden, da der Boxplot den IQR visuell darstellt, aber sie sind nicht identisch. Hier sind die Unterschiede:
- Interquartilbereich (IQR):
- Der IQR ist ein numerisches Maß, das die Streubreite der mittleren 50% der Daten beschreibt.
- Er wird berechnet als die Differenz zwischen dem dritten Quartil (Q3, 75. Perzentil) und dem ersten Quartil (Q1, 25. Perzentil), also IQR = Q3 – Q1
- Der IQR wird oft verwendet, um die Streuung innerhalb eines Datensatzes zu messen und kann dabei helfen, Ausreißer zu identifizieren, indem er feststellt, ob Werte zu weit von diesem zentralen Bereich entfernt liegen.
- Boxplot:
- Ein Boxplot ist eine grafische Darstellung des IQR sowie weiterer wichtiger Statistiken wie des Medians, der Minima und Maxima (oft repräsentiert durch die „Whisker“ des Boxplots), und manchmal auch der Ausreißer.
- Die „Box“ im Boxplot repräsentiert den IQR, wo das untere Ende der Box dem ersten Quartil (Q1) und das obere Ende dem dritten Quartil (Q3) entspricht.
- Der Median (das zweite Quartil, Q2) wird oft als Linie innerhalb der Box dargestellt.
- Die „Whisker“ des Boxplots erstrecken sich typischerweise bis zum letzten Datenpunkt innerhalb eines Bereichs, der ein Vielfaches des IQR über dem Q3 oder unter dem Q1 liegt (häufig 1,5 * IQR).
- Datenpunkte, die außerhalb der Whisker liegen, können als Ausreißer dargestellt werden, wodurch der Boxplot ein hilfreiches Werkzeug zur visuellen Ausreißererkennung ist.
Zusammenfassend ist der IQR ein berechneter Wert, der die Variabilität eines Datensatzes quantifiziert, während der Boxplot eine grafische Methode ist, die den IQR zusammen mit anderen statistischen Kennzahlen darstellt und visuell interpretiert.
Isolation Forest
- Definition und Anwendung: Der Isolation Forest ist ein auf Machine Learning basierendes Verfahren, das speziell für die Anomalieerkennung entwickelt wurde. Es isoliert Ausreißer, indem es rekursiv Zufallsteilungen in den Daten durchführt und beobachtet, wie schnell einzelne Punkte isoliert werden können.
- Stärken: Effektiv bei großen Datensätzen; erfordert keine Verteilungsannahme; gut für hohe Dimensionalität.
- Schwächen: Parameterwahl kann die Ergebnisse beeinflussen; weniger intuitiv als einfache statistische Methoden.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Definition und Anwendung: DBSCAN ist ein Clustering-Algorithmus, der Regionen hoher Dichte identifiziert und die Punkte in niedrigdichten Bereichen, die von diesen Clustern getrennt sind, als Ausreißer klassifiziert.
- Stärken: Keine Notwendigkeit, die Anzahl der Cluster im Voraus zu definieren; kann Ausreißer in einem beliebigen Dichtekontext identifizieren; gut für Daten mit Clustern unterschiedlicher Form und Größe.
- Schwächen: Die Wahl der Parameter (Mindestanzahl von Punkten und der Radius der Nachbarschaft) kann herausfordernd sein und die Ergebnisse stark beeinflussen; nicht gut für Datensätze mit variierender Dichte.
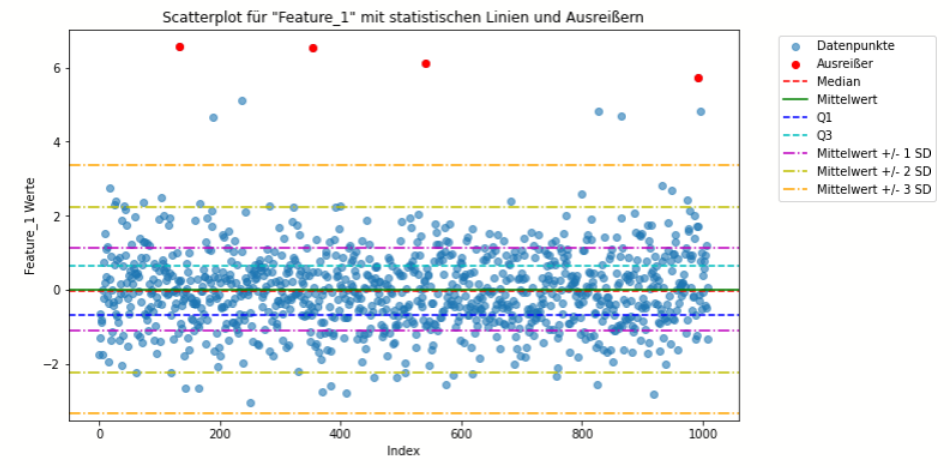
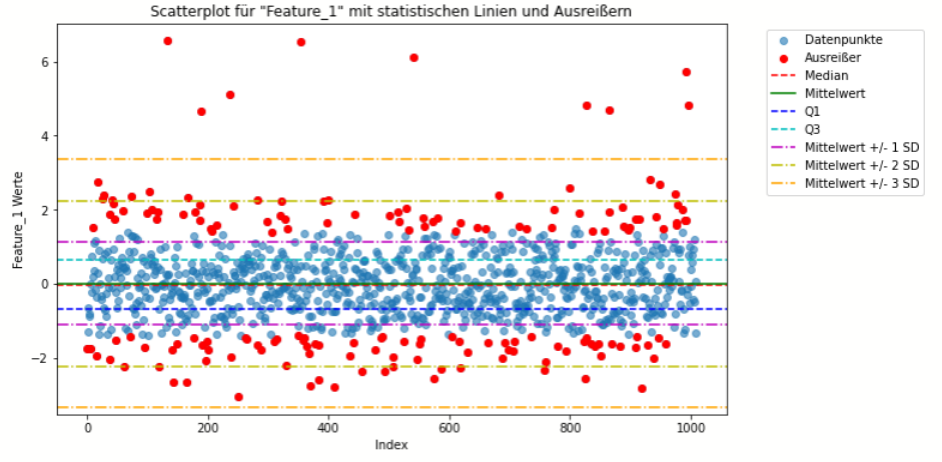
Visualisierungstechniken
- Definition und Anwendung: Neben Boxplots können Histogramme, Scatterplots und andere grafische Techniken eingesetzt werden, um Ausreißer zu identifizieren. Diese Techniken ermöglichen es dem Analysten, Anomalien visuell zu erfassen und Hypothesen über ihre Natur zu bilden.
- Stärken: Intuitive und zugängliche Art, Daten zu explorieren und Ausreißer zu erkennen; gut für die Kommunikation mit Stakeholdern.
- Schwächen: Die Effektivität hängt von der Fähigkeit des Analysten ab, visuelle Muster zu erkennen; weniger wirksam bei hohen Datenmengen oder komplexen multidimensionalen Daten.
Arten der Visualisierung wären:
- Histogramm
- Boxplot (Box-Whisker-Plot)
- Violin-Plot
- Dichteschätzung (Kernel Density Estimate, KDE)
- Q-Q-Plot (Quantile-Quantile-Plot)
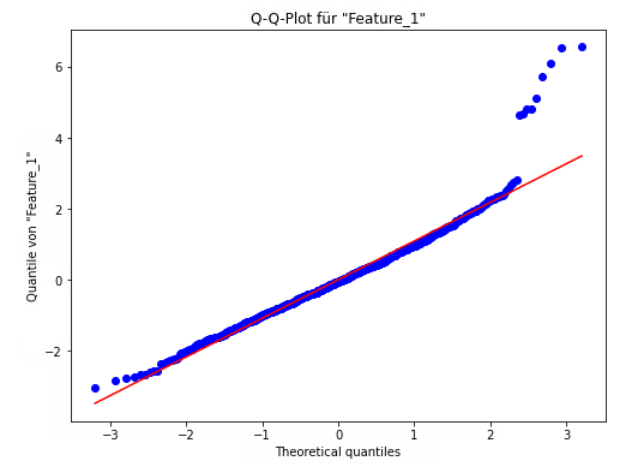
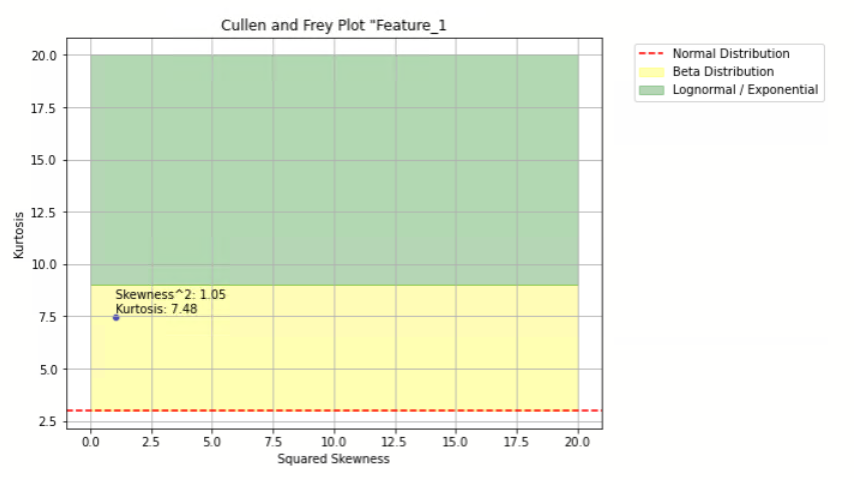
- Cullen und Frey Plot
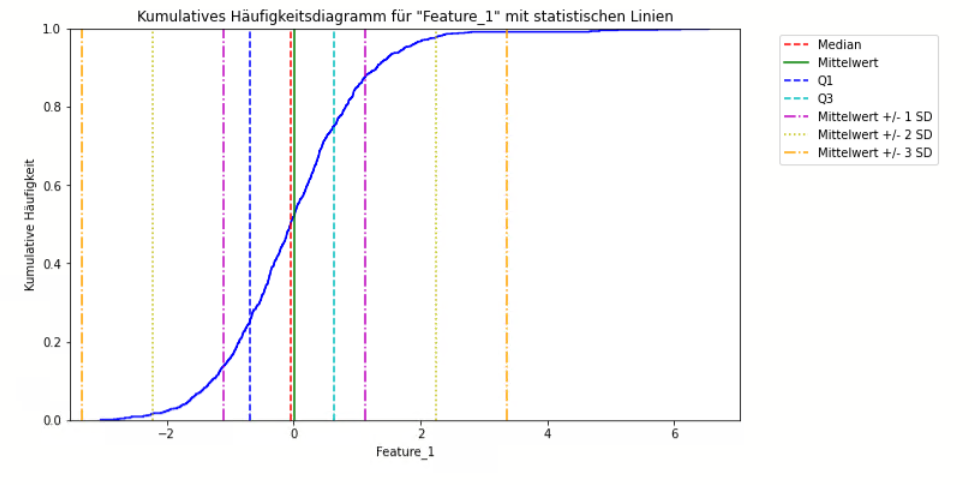
- Cumulative Frequency Plot
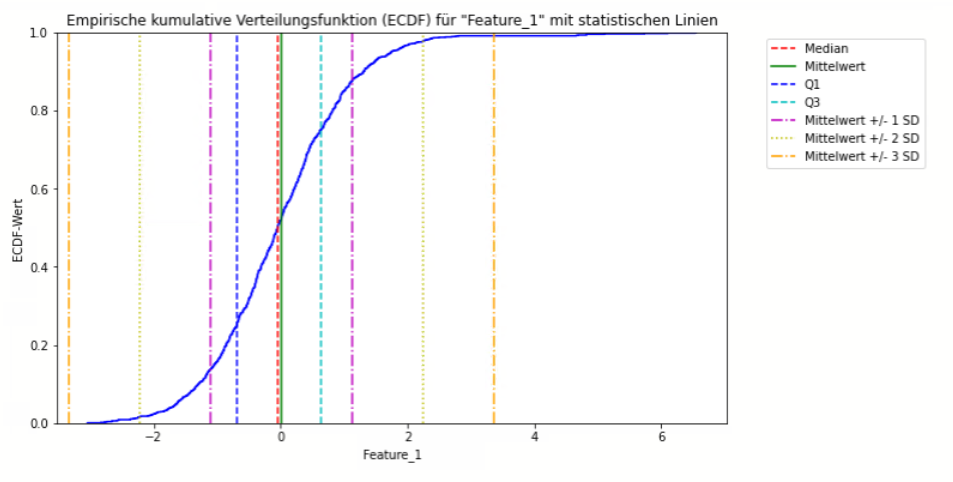
- Empirical Cumulative Distribution Function (ECDF)
- Scatterplot-Matrix (Pair Plot)
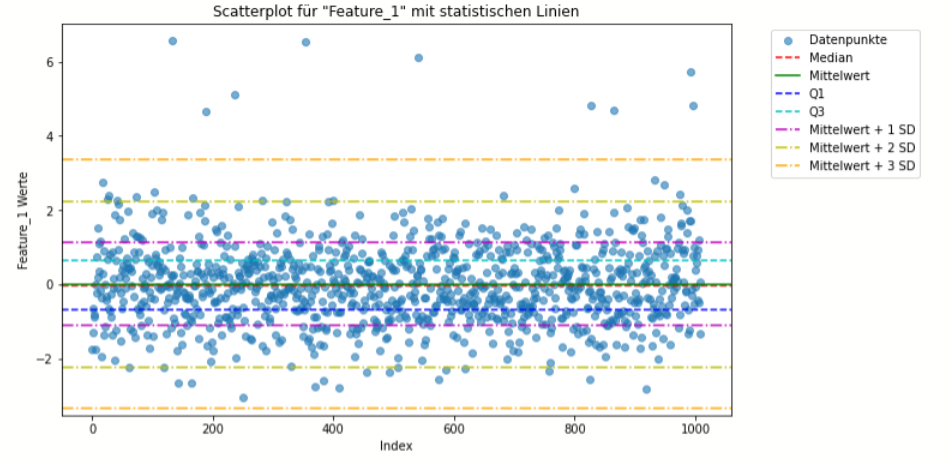
- Stem-and-Leaf Plot
Machine Learning-Methoden speziell für Ausreißer-Erkennung
Die Erkennung von Ausreißern ist ein kritischer Prozess in der Datenanalyse und im maschinellen Lernen, da sie signifikante Auswirkungen auf die Modellleistung haben kann. Diverse Methoden wurden entwickelt, um Ausreißer zuverlässig zu identifizieren. In diesem Kapitel werde ich einige der fortgeschrittenen Machine-Learning-Methoden vorstellen, die speziell für die Ausreißererkennung entwickelt wurden, und diskutieren, wie sie funktionieren, sowie ihre Stärken und Schwächen.
Autoencoder
- Konzept: Ein Autoencoder ist ein neuronales Netzwerk, das darauf abzielt, seine Eingabe auf eine kompakte Repräsentation zu reduzieren und dann die Eingabe von dieser kompakten Repräsentation aus zu rekonstruieren.
- Anwendung: In der Ausreißererkennung wird ein Autoencoder in der Regel so trainiert, dass er nur mit „normalen“ Daten arbeitet. Wenn er dann auf einen Ausreißer stößt, führt dies zu einem hohen Rekonstruktionsfehler.
- Stärken:
- Kann komplexe nicht-lineare Beziehungen in den Daten lernen.
- Wirksam in unüberwachten Lernszenarien.
- Anpassungsfähig an verschiedene Datentypen.
- Schwächen:
- Kann übermäßig komplexe Modelle erzeugen, die schwer zu interpretieren sind.
- Übertraining kann dazu führen, dass das Modell auch Ausreißer akzeptiert.
One-Class SVM
- Konzept: One-Class SVM ist eine Erweiterung der Support Vector Machine, die für unüberwachtes Lernen konzipiert ist. Sie identifiziert die kleinste Region, in der die Trainingsdaten liegen, und betrachtet Punkte außerhalb dieser Region als Ausreißer.
- Anwendung: Besonders geeignet für die Anomalieerkennung in Datensätzen mit einer klar definierten „normalen“ Region.
- Stärken:
- Kann in hochdimensionalen Räumen gut funktionieren.
- Nicht auf eine spezifische Verteilung der Daten beschränkt.
- Schwächen:
- Rechenintensiv, besonders bei großen Datensätzen.
- Wahl der Kernel-Funktion und Hyperparameter kann herausfordernd sein.
Random Cut Forest (RCF)
- Konzept: RCF ist ein Ensemble-Lernmodell, das viele Entscheidungsbäume verwendet, um Datenpfade für Datenpunkte zu erstellen. Punkte, die schneller isoliert werden, gelten als Ausreißer.
- Anwendung: Wirksam für die Ausreißererkennung in Online-Datenströmen und bei der Verarbeitung von großen Datensätzen.
- Stärken:
- Gute Leistung bei der Erkennung von Ausreißern in Echtzeit.
- Skalierbar und effektiv bei unterschiedlichen Datentypen.
- Schwächen:
- Ergebnisse können variieren, da die Methode auf Zufälligkeit beruht.
- Die Interpretation der Ergebnisse kann ohne geeignete Visualisierung schwierig sein.
Robust Random Cut Forest
- Konzept: Eine Variante des RCF, die widerstandsfähiger gegenüber Ausreißern in den Trainingsdaten ist.
- Anwendung: Geeignet für Szenarien, in denen die Trainingsdaten bereits Ausreißer enthalten können.
- Stärken:
- Bietet eine verbesserte Erkennung von Ausreißern unter schwierigen Bedingungen.
- Behält die Vorteile des RCF bei, einschließlich Skalierbarkeit und Effektivität bei Echtzeitanwendungen.
- Schwächen:
- Kann immer noch empfindlich auf die Wahl der Hyperparameter reagieren.
Local Outlier Factor (LOF)
- Konzept: LOF ist ein Algorithmus, der auf einer lokalen Dichteschätzung basiert. Er misst, wie isoliert ein Objekt im Vergleich zu seiner Umgebung ist.
- Anwendung: Ideal für Datensätze, in denen die Ausreißer eine deutlich niedrigere Dichte als die übrigen Daten aufweisen.
- Stärken:
- Effektiv bei Datensätzen mit mehreren Subpopulationen oder Clustern.
- Kann lokale Ausreißer erkennen, die in der globalen Sicht möglicherweise nicht auffällig sind.
- Schwächen:
- Leistung kann in hochdimensionalen Datensätzen abnehmen.
- Die Wahl des Skalierungsparameters ist entscheidend.
K-Means Clustering
- Konzept: K-Means ist ein Clustering-Algorithmus, der Datenpunkte anhand ihrer Nähe zu den Clusterzentren gruppiert.
- Anwendung: Ausreißer können als die Punkte identifiziert werden, die weit von jedem Clusterzentrum entfernt liegen.
- Stärken:
- Einfach und schnell zu implementieren.
- Intuitiv und leicht zu verstehen.
- Schwächen:
- Anfällig für die Initialisierung der Clusterzentren.
- Kann bei Datensätzen mit komplexen Clustern oder stark variierender Dichte versagen.
Ensemble-Ansätze
- Konzept: Ensemble-Methoden kombinieren die Vorhersagen von mehreren verschiedenen Modellen, um die Genauigkeit zu verbessern.
- Anwendung: Verschiedene Ausreißererkennungsalgorithmen können zu einem Ensemble zusammengefasst werden, um die jeweiligen Stärken zu nutzen und Schwächen auszugleichen.
- Stärken:
- Reduziert das Risiko von Modellverzerrungen und Überanpassung.
- Oft höhere Vorhersagegenauigkeit.
- Schwächen:
- Komplex in der Implementierung und Validierung.
- Höherer Berechnungsaufwand.
Deep Learning Ansätze
- Konzept: Tiefes Lernen verwendet komplexe neuronale Netzwerkarchitekturen, die fähig sind, tiefe Datenstrukturen zu erfassen.
- Anwendung: Kann für unüberwachte, halbüberwachte und überwachte Ausreißererkennung eingesetzt werden, abhängig von der Datenverfügbarkeit und dem spezifischen Anwendungsfall.
- Stärken:
- Fähigkeit, komplexe und abstrakte Muster in den Daten zu erkennen.
- Besonders wirksam bei großen und komplexen Datensätzen.
- Schwächen:
- Benötigt umfangreiche Trainingsdaten.
- Modelle können sehr komplex und schwer zu interpretieren sein.
Diese Methoden repräsentieren die Spitze der technologischen Entwicklungen im Bereich des maschinellen Lernens für die Ausreißererkennung. Jede Methode hat ihre eigenen Besonderheiten und Anwendungsbereiche. Bei der Wahl der richtigen Methode müssen verschiedene Faktoren wie die Art der Daten, die Verfügbarkeit von Markierungen, die gewünschte Interpretierbarkeit der Ergebnisse und die rechnerischen Ressourcen berücksichtigt werden. Durch den Einsatz dieser fortschrittlichen Techniken können Datenwissenschaftler und Analysten die Genauigkeit ihrer Modelle verbessern und tiefere Einsichten in ihre Daten gewinnen.
Diskussion
Die Effektivität von Ausreißer-Erkennungsmethoden variiert stark je nach Datentyp und Umfang der Datensätze. Einzelne Methoden wie Autoencoder und Deep Learning-Ansätze eignen sich hervorragend für komplexe Datentypen wie Bilder oder sequenzielle Daten, weil sie in der Lage sind, nicht-lineare Muster und Zusammenhänge zu lernen. Autoencoder, insbesondere, sind effektiv bei der Detektion von Anomalien in Bildern, da sie lernen können, die normalen Merkmale zu rekonstruieren und Abweichungen deutlich als hohe Rekonstruktionsfehler zu kennzeichnen. Deep Learning-Ansätze profitieren von ihrer Fähigkeit, multiple Ebenen der Abstraktion zu erlernen, was sie ideal für große und komplexe Datensätze macht, die eine reichhaltige interne Struktur aufweisen.
Im Gegensatz dazu sind Methoden wie One-Class SVM und LOF besser für numerische und weniger komplexe Datentypen geeignet. One-Class SVM kann effektiv eingesetzt werden, wenn ein klar definierter „normaler“ Datenbereich vorhanden ist, während LOF ideal für Datensätze ist, die in Bezug auf die lokale Nachbarschaftsdichte variieren. Clustering-basierte Methoden wie K-Means sind nützlich für gut separierte Datencluster, können jedoch bei komplexeren Strukturen oder Datensätzen mit variierender Dichte an ihre Grenzen stoßen.
Ensemble-Ansätze und zufällige Schnittwaldmethoden wie Random Cut Forest und dessen robustere Varianten bieten Vorteile bei der Handhabung großer Datenmengen und können in verschiedenen Kontexten eingesetzt werden, indem sie die Stärken einzelner Methoden kombinieren, um eine umfassende Lösung zu bieten.
Die Herausforderungen bei der Ausreißer-Erkennung in großen Datensätzen sind vielschichtig. Zum einen steigt mit der Größe des Datensatzes die Komplexität der Datenverarbeitung, was rechnerisch teuer und zeitaufwendig sein kann. Methoden wie Deep Learning und Autoencoder benötigen beispielsweise erhebliche Rechenleistung und Speicher, um effektiv zu sein. Zum anderen kann die schiere Anzahl von Datenpunkten die Identifizierung von Ausreißern erschweren, da die Grenze zwischen „normalen“ Daten und Anomalien verschwimmen kann. Dies erfordert Methoden, die robust gegenüber der Variabilität in großen Datensätzen sind und gleichzeitig sensibel genug, um subtile Anomalien zu erkennen.
Ein weiteres Problem ist die Dimensionalität: Mit zunehmender Anzahl von Features in einem Datensatz kann es schwieriger werden, Ausreißer zu identifizieren, ein Phänomen, das als „Fluch der Dimensionalität“ bekannt ist. Methoden wie PCA-basierte Autoencoder oder dimensionality reduction techniques können dazu beitragen, dieses Problem zu mildern, indem sie die Daten auf ihre wesentlichen Merkmale reduzieren.
Schließlich ist die Qualität der Daten selbst eine Herausforderung. Große Datensätze enthalten oft fehlende Werte, Rauschen und andere Artefakte, die die Ausreißererkennung beeinträchtigen können. Eine sorgfältige Vorverarbeitung und Reinigung der Daten ist daher entscheidend, um die Genauigkeit der Ausreißererkennung zu gewährleisten. Methoden müssen auch in der Lage sein, zwischen echten Anomalien und zufälligen Datenunregelmäßigkeiten zu unterscheiden, um Fehlalarme zu vermeiden.
Insgesamt erfordert die Ausreißer-Erkennung in großen Datensätzen eine sorgfältige Auswahl der Methoden, eine angemessene Datenbereinigung und Vorverarbeitung sowie die Fähigkeit, Modelle angemessen zu validieren und zu kalibrieren. Die Wahl der richtigen Technik ist abhängig von den spezifischen Eigenschaften der Daten und dem Kontext, in dem die Ausreißererkennung stattfindet.
Vergleich der Methoden in einer Matrix
- Erstellung einer Vergleichsmatrix mit Kriterien wie Genauigkeit, Komplexität, Skalierbarkeit, usw.
- Bewertung jeder Methode anhand der Vergleichskriterien.
- Diskussion von Fallstudien oder Beispielen, wo diese Methoden angewandt wurden.
- Vor- und Nachteile jeder Methode im Kontext von Forecasting.
Anwendung der Ausreißer-Erkennung in der Praxis
- Schrittweise Anleitung zur Implementierung einer Ausreißer-Erkennung.
- Fallbeispiele, bei denen Ausreißer-Erkennung zu verbesserten Forecasting-Ergebnissen führte.
- Tipps zur Auswahl der richtigen Methode für spezifische Forecasting-Probleme.
- Diskussion der Wartung und kontinuierlichen Verbesserung von Prognosemodellen.
Die Anwendung der Ausreißer-Erkennung in praktischen Szenarien ist ein mehrstufiger Prozess, der nicht nur die Auswahl und Implementierung von Algorithmen umfasst, sondern auch die Vor- und Nachbereitung der Daten sowie die kontinuierliche Überwachung und Verbesserung der Modelle. In diesem Kapitel werde ich eine umfassende Anleitung zur Implementierung von Ausreißer-Erkennungstechniken bereitstellen, praktische Fallbeispiele hervorheben, bei denen diese Methoden zu verbesserten Prognoseergebnissen geführt haben, Ratschläge zur Methodenauswahl geben und schließlich die Wichtigkeit der Wartung und stetigen Verbesserung von Prognosemodellen diskutieren.
Schrittweise Anleitung zur Implementierung einer Ausreißer-Erkennung
- Datenvorbereitung: Der erste Schritt ist immer, die Daten zu bereinigen und vorzubereiten. Dies umfasst das Entfernen von Duplikaten, das Behandeln von fehlenden Werten und das Normalisieren oder Standardisieren der Features.
- Explorative Datenanalyse (EDA): Bevor man sich auf komplexe Algorithmen stürzt, sollte man die Daten visuell untersuchen, um ein Gefühl für mögliche Ausreißer zu bekommen. Boxplots, Scatterplots und Histogramme sind hierbei nützliche Werkzeuge.
- Auswahl des Algorithmus: Basierend auf der EDA und dem Verständnis der Daten sollte ein passender Algorithmus gewählt werden. Dabei sollten die Datentypen, die Größe des Datensatzes und die spezifischen Anforderungen des Forecasting-Modells berücksichtigt werden.
- Implementierung: Der gewählte Algorithmus wird auf den bereinigten Datensatz angewendet. Dies kann mittels bestehender Bibliotheken wie scikit-learn, TensorFlow oder PyOD erfolgen.
- Evaluation: Die Ergebnisse der Ausreißer-Erkennung sollten evaluiert werden, um sicherzustellen, dass die identifizierten Punkte tatsächlich Ausreißer sind. Dies kann durch eine Kombination aus automatischen Metriken und manueller Überprüfung geschehen.
- Bereinigung: Die identifizierten Ausreißer können entfernt, korrigiert oder in der weiteren Analyse separat behandelt werden.
- Integration: Die Ausreißer-Erkennung wird als Teil eines umfassenden Datenverarbeitungs-Pipeline für das Forecasting-Modell integriert.
- Monitoring: Nach der Implementierung muss das System regelmäßig überwacht werden, um sicherzustellen, dass es weiterhin korrekt funktioniert und die Datenqualität beibehalten wird.
Fallbeispiele
In der Praxis haben zahlreiche Unternehmen festgestellt, dass durch die Anwendung von Ausreißer-Erkennung die Genauigkeit ihrer Prognosemodelle deutlich gesteigert werden konnte. Zum Beispiel konnte ein Online-Einzelhändler durch das Entfernen von Ausreißern, die durch ungewöhnliche Verkaufsaktionen verursacht wurden, die Genauigkeit seiner Lagerbestandsprognosen verbessern. Ein Finanzinstitut nutzte Ausreißer-Erkennung, um atypische Transaktionen zu identifizieren und seine Betrugserkennungsmodelle zu verfeinern.
Tipps zur Auswahl der richtigen Methode
Die Auswahl der richtigen Ausreißer-Erkennungsmethode hängt von mehreren Faktoren ab:
- Datengröße und -komplexität: Für große Datensätze mit hoher Dimensionalität sind Methoden wie Autoencoder oder Ensemble-Techniken empfehlenswert.
- Datentyp: Time-Series-Anomalieerkennungsmethoden sind für sequentielle Daten geeignet, während für strukturierte Daten Clustering- oder Dichtebasierte Methoden verwendet werden können.
- Rechenressourcen: Einige Methoden, wie tiefes Lernen, benötigen erhebliche Rechenleistung, was bei der Auswahl berücksichtigt werden sollte.
- Interpretierbarkeit: In manchen Fällen ist es wichtig, dass die Ergebnisse leicht interpretierbar sind, was für einfache statistische Methoden oder Entscheidungsbaum-basierte Ansätze spricht.
Wartung und kontinuierliche Verbesserung
Die Wartung und kontinuierliche Verbesserung von Prognosemodellen ist entscheidend, um ihre Genauigkeit und Relevanz über die Zeit zu erhalten. Dazu gehört das regelmäßige Training mit neuen Daten, um das Modell aktuell zu halten, sowie die Anpassung an neue Muster oder Trends in den Daten. Es ist auch wichtig, die Parameter der Ausreißer-Erkennungsalgorithmen regelmäßig zu überprüfen und anzupassen, um eine optimale Leistung zu gewährleisten. Die Implementierung eines robusten Feedback-Systems, das es den Benutzern ermöglicht, Feedback zur Ausreißererkennung zu geben, kann dabei helfen, die Modelle kontinuierlich zu verbessern und sie an die sich ändernden Bedingungen anzupassen.
Durch die sorgfältige Implementierung und ständige Verbesserung der Ausreißer-Erkennung innerhalb der Forecasting-Prozesse können Unternehmen wertvolle Einblicke gewinnen und ihre Entscheidungsfindung auf einer solideren Datenbasis aufbauen.
Persönliches Fazit
- Zusammenfassung der wichtigsten Erkenntnisse aus dem Artikel.
- Meine persönliche Meinung zur besten Methode der Ausreißer-Erkennung für Forecasting.
- Hinweise darauf, wie wichtig eine sorgfältige Ausreißer-Erkennung für die Genauigkeit von Forecasting ist.
- Abschließende Gedanken zur Bedeutung von Qualitätsdaten in Machine Learning-Projekten.
Das Feld der Ausreißer-Erkennung ist faszinierend und komplex zugleich. Es spielt eine entscheidende Rolle in der Welt des Forecasting, da Ausreißer die Fähigkeit eines Modells, zukünftige Datenpunkte vorherzusagen, erheblich beeinflussen können. Im Laufe dieses Artikels haben wir die verschiedenen Aspekte der Ausreißer-Erkennung erörtert, von den grundlegenden Definitionen und Methoden bis hin zu den spezifischen Techniken des maschinellen Lernens und deren Anwendung in der Praxis.
Meine persönliche Meinung ist, dass es keine universelle „beste“ Methode zur Ausreißer-Erkennung gibt; vielmehr hängt die optimale Wahl von den spezifischen Umständen des Forecasting-Problems ab. Für hochdimensionale und komplexe Datensätze, in denen die Beziehungen zwischen den Variablen nicht sofort ersichtlich sind, neige ich dazu, tieferes Lernen und speziell Autoencoder zu bevorzugen. Diese können subtile Muster in den Daten erkennen, die andere Methoden möglicherweise übersehen. In Umgebungen, in denen Berechnungseffizienz und Modellinterpretierbarkeit jedoch entscheidend sind, könnte ein einfacherer, statistischer Ansatz wie der Z-Score oder der IQR effektiver sein.
Die sorgfältige Ausreißer-Erkennung ist für die Genauigkeit des Forecasting unerlässlich. In der Praxis habe ich beobachtet, dass Modelle, die ohne eine solche Überprüfung trainiert wurden, oft zu falschen Vorhersagen neigen, insbesondere in volatilen oder ungewöhnlichen Marktbedingungen. Ausreißer können die Modellleistung auf zwei Arten beeinträchtigen: Sie können zu einer Überanpassung führen, bei der das Modell die „Rauschen“ anstelle der tatsächlichen Signal lernt, oder sie können zu einer Unteranpassung führen, bei der das Modell wichtige Informationen nicht erfassen kann.
Abschließend möchte ich betonen, wie entscheidend Qualitätsdaten in Machine Learning-Projekten sind. Unabhängig von der gewählten Methode ist die Qualität der zugrunde liegenden Daten ausschlaggebend für den Erfolg oder Misserfolg des Projekts. Eine gründliche Datenbereinigung und -verarbeitung, einschließlich einer effektiven Ausreißer-Erkennung, ist nicht nur wünschenswert, sondern absolut notwendig. Wie das Sprichwort in der Datenwissenschaft lautet: „Garbage in, garbage out“. Ohne eine solide Datenbasis ist jedes Machine Learning-Modell, egal wie fortschrittlich, zum Scheitern verurteilt.
Abschließend ist die Ausreißer-Erkennung kein statischer Prozess; es ist ein dynamisches Feld, das kontinuierliche Aufmerksamkeit, Anpassung und Verbesserung erfordert. Die Welt verändert sich ständig, und unsere Modelle und Methoden müssen sich ebenfalls weiterentwickeln, um Schritt zu halten. In der Welt des maschinellen Lernens und des Forecasting ist die Ausreißer-Erkennung daher nicht nur ein Werkzeug, sondern eine Notwendigkeit, um präzise, zuverlässige und robuste Vorhersagen zu gewährleisten.
Abschluss
- Aufruf zum Handeln für die Leser, eigene Modelle zu überprüfen und zu verbessern.
- Einladung zur Diskussion und Kommentar zu Erfahrungen mit Ausreißer-Erkennung.
- Hinweis auf zukünftige Artikel oder weiterführende Ressourcen.
Während wir uns dem Ende dieses umfassenden Streifzugs durch die Landschaft der Ausreißer-Erkennung und deren Bedeutung für das Forecasting nähern, möchte ich Sie, die Leserinnen und Leser, dazu ermutigen, das neu erworbene Wissen anzuwenden und Ihre eigenen Modelle und Annahmen zu überprüfen.
Aufruf zum Handeln
Ich fordere Sie auf, einen kritischen Blick auf Ihre Datenverarbeitungs-Pipelines zu werfen. Beginnen Sie mit einer gründlichen explorativen Datenanalyse, um ein intuitives Verständnis für Ihre Daten zu entwickeln. Nutzen Sie dann die unterschiedlichen Methoden zur Ausreißer-Erkennung, die wir besprochen haben, um zu sehen, wie sie die Qualität Ihrer Daten und die Leistung Ihrer Forecasting-Modelle verbessern können. Experimentieren Sie mit verschiedenen Techniken, passen Sie sie an Ihre speziellen Anforderungen an und messen Sie die Auswirkungen. Erinnern Sie sich daran, dass die richtige Ausreißer-Erkennung Ihre Modelle nicht nur resistenter gegenüber Datenanomalien macht, sondern auch zu präziseren und verlässlicheren Vorhersagen führen kann.
Einladung zur Diskussion
Ihre Erfahrungen und Einsichten sind wertvoll, und ich lade Sie herzlich ein, sie zu teilen. Haben Sie bestimmte Methoden zur Ausreißer-Erkennung in Ihren Projekten angewendet? Welche Herausforderungen sind Ihnen begegnet? Welche Erfolgsgeschichten können Sie erzählen? Die Kommentarsektion dieses Artikels soll ein offenes Forum sein, in dem wir alle von gegenseitigen Erfahrungen lernen können. Jeder Beitrag, ob Frage, Kommentar oder Kritik, ist willkommen und trägt zum gemeinschaftlichen Wissen bei.
Zukünftige Artikel und Ressourcen
Die Welt des maschinellen Lernens entwickelt sich rasant weiter, und die Ausreißer-Erkennung ist nur ein Aspekt davon. In zukünftigen Artikeln werde ich weitere nuancierte Themen aufgreifen, wie die Integration von Ausreißer-Erkennungsmethoden in Echtzeitsysteme, den Einsatz von KI zur automatischen Anpassung von Ausreißer-Detektionsparametern und fortgeschrittene Themen wie die Verwendung von Transferlernen und unsupervised learning. Bleiben Sie dran, um keine dieser spannenden Entwicklungen zu verpassen.
Darüber hinaus plane ich, eine Reihe von Ressourcen zur Verfügung zu stellen, die Ihnen helfen sollen, Ihr Verständnis zu vertiefen und Ihre Fähigkeiten zu erweitern. Dazu gehören Leitfäden, Tutorials und Fallstudien, die in zukünftigen Beiträgen oder auf meiner Webseite bereitgestellt werden.
Ich möchte mich bei Ihnen für Ihre Zeit und Ihr Engagement bedanken. Die Reise in die Welt des maschinellen Lernens ist eine fortlaufende Entdeckung, und ich freue mich darauf, sie gemeinsam mit Ihnen fortzusetzen. Nehmen Sie das Gelernte und wenden Sie es an, diskutieren Sie offen und bleiben Sie neugierig und engagiert. Die nächste große Entdeckung in Ihren Daten könnte nur ein paar Ausreißeranalysen entfernt sein.

 Erhard RAINER
Erhard RAINER