General
Dieser Abschnitt meiner Webseite beschäftigt sich mit Business Intelligence und dergleichen. Primär beschäftige ich mich dabei mit den Grundlagen im Zusammenhang mit SQL Server. Zusätzlich befinden sich einige Einträge in meinem Blog.
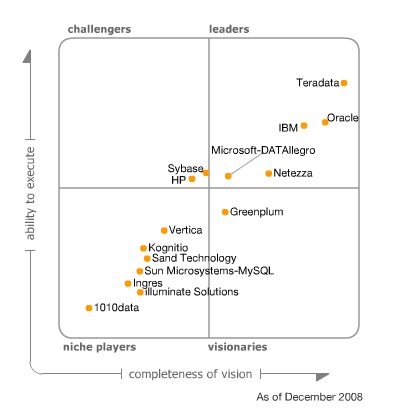
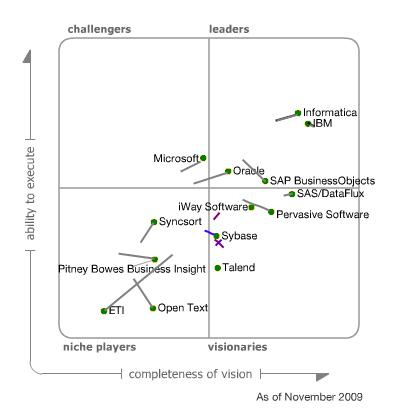
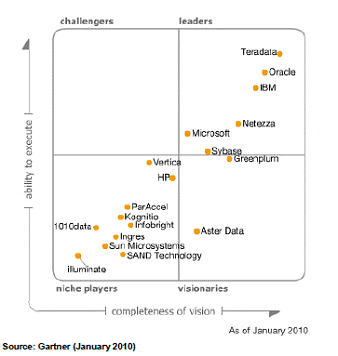
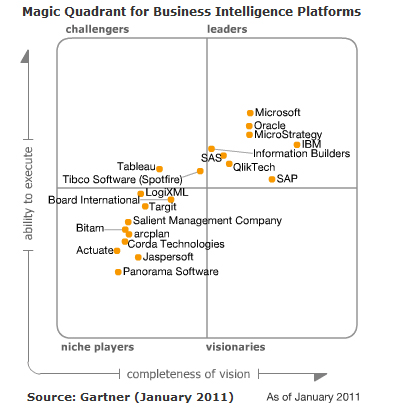
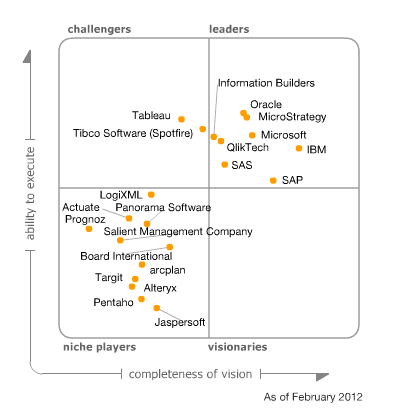
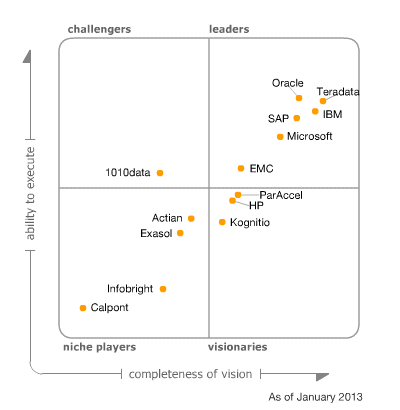
Entwicklung der BI Tools über die Zeit
Neben Microsoft gibt es aber auch noch eine Reihe anderer Mitspieler am Markt rund um BI. Im jährlich erscheinenden Gartner Report werden die wichtigsten Hersteller von BI-Software gegenübergestellt.
Datenbankmodellierung
Die meisten Datenbanken benutzen normalisierte Daten. Anders ist es im Data Warehouse: hier trifft man in der Regel auf denormalisierte Daten, auch wenn es durchaus Konzepte für normalisierte Daten im DWH gibt. Ziel des Data Warehouse (OLAP) auf schnelle Lesezugriffe zu optimieren, währende Transaktionsdatenbanken (OLTP) auf Inserts und Update optimiert sind.
Datenbankmodellierung ist der Prozess des Entwerfens und Entwickelns eines Datenbankmodells. Es ist ein wichtiger Schritt bei der Entwicklung einer Datenbank und kann die Leistung, Zuverlässigkeit und Wartbarkeit der Datenbank verbessern.
Relationale Datenbanken
Relationale Datenbanken sind eine Art von Datenbank, die Daten in Form von Tabellen speichert. Die Tabellen sind durch Beziehungen miteinander verbunden.
OLTP-Systeme (Online Transaction Processing) werden für die Verarbeitung von Transaktionen in Echtzeit verwendet, während OLAP-Systeme (Online Analytical Processing) für die Analyse von Daten aus verschiedenen Perspektiven verwendet werden.
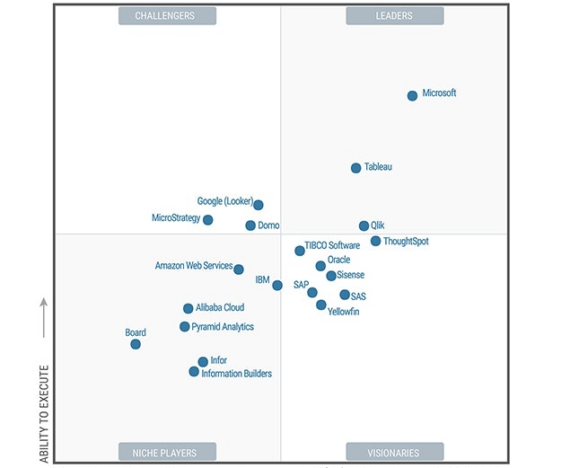
Business Intelligence Plattformen
Datenintegration: ETL vs. ELT
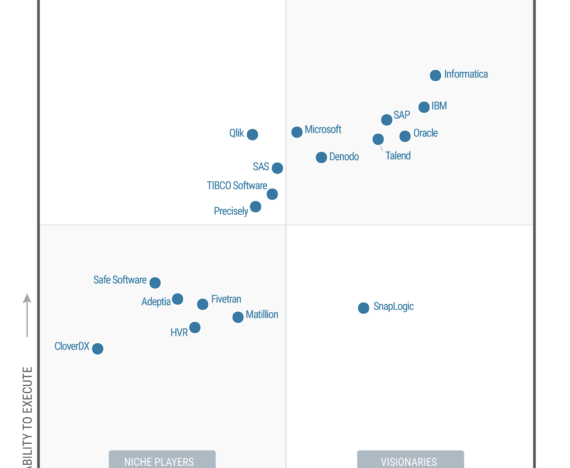
ETL steht für Extract, Transform, Load und beschreibt den Prozess der Datenextraktion einer Datenquelle und Transformation in das Format für die weitere Verarbeitung, beispielsweise für das DWH.
- Informatica – Power Center
- IBM – Infosphere Information Server
- Oracle Data Integrator
- Microsoft SQL Integration Services (SSIS)
- Talend
- Pentaho Data Integration
- Apache NiFi
- SAP – Business Objects Date Integrator
- Sybase ETL
- DBSoftlab
- Jasper
ETL und ELT sind zwei verschiedene Ansätze für die Datenintegration. ETL steht für Extract, Transform, Load, während ELT für Extract, Load, Transform steht.
Bei ETL werden Daten aus verschiedenen Quellen extrahiert, transformiert und dann in ein Zielsystem geladen. Bei ELT werden Daten dagegen direkt in das Zielsystem geladen und erst dort transformiert.
DWH – Data Warehouse
Ein Data Warehouse ist eine Sammlung von Daten aus verschiedenen Quellen, die für die Analyse und Entscheidungsfindung genutzt werden. Data Warehouses werden häufig in Unternehmen verwendet, um Geschäftsdaten aus verschiedenen Abteilungen und Systemen zusammenzuführen.
Data Warehouse in der Cloud
- Google Big Query
- Amazon Redshift
- Azure Data Warehouse / Azure Synapse Analytics
- Snowflake
- Apache Kylin
- weiterführende Informationen:
- Data Warehouse Cloud Benchmark
- Farhad Alam & Neel Kamal – Survey on Data Warehouse from Taditional ot Realtime and Society Impact of Real Time Data
Beispiele
Umsetzung im MS Umfeld
Auswertung der Daten
- Darstellung der Daten am Sharepoint (nicht mehr aktuell)
- Power BI
- Qlik
- Tableau
- Google Looker
- Amazon QickSight
- Darstellung der Daten am SharePoint
- Excel Services
- PerformancePoint Services
- Poverpivot für SharePoint
- Reporting Services
- Micorosft Report Builder:
- Access
- Zugriff auf eine OLTP-Datenbank (relationale Datenbank) mit Access
- Power BI
SAP
SAP BW/4HANA
Wenn man sich im Bereich SAP BI zertifizieren lassen möchte, empfehle ich die Zertifizierung „SAP Certified Application Associate – Reporting, Modeling and Data Acquisition with SAP BW/4HANA 2.x„. Diese umfasst folgende Themengebiete:
- Data Acquisition into SAP BW/4HANA (BW450)
- SAP BW Query Design (BW405)
- InfoObjects and InfoProviders (BW410)
- Native SAP HANA Modeling (BW410 / BW430)
- SAP BW/4HANA Project and the Modeling Process (BW430)
- SAP BW/4HANA Modeling (BW430)
- SAP BW/4HANA Data Flow (BW410)
- SAP Analytics Tools (BW405)
- Fundamentals (BW405 / BW430) / BW450)
- Data Acquisition into SAP HANA (BW450)
Wenn man Student ist kann man auch über
- SAP BW/4HANA – Datenfluss und BusinessObjects Reporting (BW1)
- SAP BW/4HANA – Datenmodelierung und BusinessObjects Lumira (BW2)
Hier habe ich einzelne Themen zusammengefasst
- Datenstrukturen in SAP-BW anlegen
- Berichte erstellen (Query Designer)
SAP Analytics Cloud
Neben der oben erwähnten Zertifizierung gibt es noch die Möglichkeit „SAP Certified Application Associate – SAP Analytics Cloud“ zu zertifizieren. Diese Prüfung umfasst folgende Module
- Content presentation, Sharing, Collaboration (SAC01)
- Business Intelligence (SAC01 / SACMS1)
- Data Preparation: Data Model (SAC01 / SACMS1)
- Predictive Analytics (SAC01 / SACMS1)
- Overview and Core Functionality (SAC01)
- SAP Analytics Cloud Administration, Connections and Integration (SAC01 / SACMS1)
- SAP Analytics Cloud Analytics Designer and Microsoft Office Integration (SAC01)
- ERP4Students: SAP Analytics Cloud (SAC) – Analyse, Planung und Integration
