Einführung in die Sentiment-Analyse
Definition und Bedeutung
Was ist Sentiment-Analyse?
Die Sentiment-Analyse, auch bekannt als Meinungs- oder Stimmungsanalyse, ist ein Feld der Textanalyse, das darauf abzielt, die Stimmung hinter einer Serie von Worten zu identifizieren und zu kategorisieren, um zu verstehen, wie die Schreiberlinge fühlen. Sie kombiniert Methoden aus der Datenverarbeitung, Textanalyse und maschinelles Lernen, um schriftlich festgehaltene Stimmungen wie in Rezensionen, Umfragen, Blogs und anderen Online-Quellen zu bewerten.
Warum ist Sentiment-Analyse wichtig?
In einer Welt, die zunehmend auf Daten und automatisierte Entscheidungsfindung setzt, gibt Sentiment-Analyse Unternehmen einen entscheidenden Einblick in die öffentliche Meinung, Marktstimmung und Kundenerfahrungen. Unternehmen verwenden Sentiment-Analyse, um ihre Produkte und Dienstleistungen zu verbessern, ihre Marketingstrategien anzupassen, die Kundenzufriedenheit zu überwachen und Krisen in sozialen Medien abzuwenden.
Grundlegende Konzepte
Die Sentiment-Analyse bedient sich unterschiedlicher Techniken, um Emotionen in Texten zu erkennen. Zu den grundlegenden Konzepten gehören die Polarisierung der Stimmung (positiv, negativ, neutral) und die Intensität der Emotion. Moderne Ansätze nutzen komplexere Modelle, die Sarcastic, „Mixed“ oder „Compound“ Emotionen erkennen, um den Nuancen menschlicher Kommunikation gerecht zu werden.
Methodik
Die Umsetzung von Sentiment-Analysen beruht häufig auf maschinellem Lernen oder auf festgelegten Regeln, wobei beide Herangehensweisen ihre Vor- und Nachteile bieten. Maschinelles Lernen benötigt für gewöhnlich große Mengen an trainierten Daten, um effektiv zu sein, während regelbasierte Systeme starrer sind, aber für Spezifische Anwendungsfälle schneller implementiert werden können.
Anwendungen und Beispielbranchen
- Marketing und Marktforschung: Erfassen der Produktbewertung und Feedback zur weiteren Produktentwicklung.
- Finanzmarktanalyse: Prognostizieren von Markttrends durch Analyse der Stimmung aus Nachrichtenartikeln oder Aktienforen.
- Kundendienst: Automatisches Erkennen von Kundenstimmungen in Support-Tickets oder Kundenfeedback, um Service zu verbessern.
- Politik: Einschätzung öffentlicher Meinungen zu politischen Kampagnen oder Entscheidungen.
Herausforderungen und Entwicklungen
Obwohl Sentiment-Analyse ein mächtiges Werkzeug ist, bleibt es herausfordernd, den Kontext und die Subtilität der menschlichen Sprache zu erfassen. Ironie, Sarkasmus und Doppeldeutigkeit sind ständige Hindernisse für genaue Ergebnisse. Forschung und Entwicklung auf diesem Gebiet sind weiterhin von großer Bedeutung, um Algorithmen zu entwickeln, die mit der Komplexität der menschlichen Sprache und Stimmung umgehen können.
Die Sentiment-Analyse ist ein faszinierender Zweig der Künstlichen Intelligenz und Natural Language Processing (NLP), der kontinuierlich wächst und sich entwickelt, um Unternehmen und Organisationen wertvolle Erkenntnisse aus unstrukturierten Daten zu liefern. Die Technologie wird immer weiter verfeinert, um die emotionale Tiefe besser zu verstehen und nützlichere, genauere Informationen aus Textquellen zu extrahieren.
Anwendungsbereiche der Sentiment-Analyse
Die Sentiment-Analyse, ist eine facettenreiche Technik, die sich in verschiedensten Bereichen als unverzichtbares Instrument etabliert hat, wie zum Beispiel in den folgenden Anwendungsbereichen:
Kundenfeedback und Marktforschung
Einer der prominentesten Einsatzgebiete der Sentiment-Analyse ist das Gebiet der Kundenfeedback-Auswertung. Gemäß einer Studie des Fraunhofer-Instituts ermöglicht die maschinelle Analyse von Kundenmeinungen eine schnelle Reaktion auf Marktänderungen und Kundenbedürfnisse. So können Unternehmen beispielsweise Produktbewertungen und Kundenrezensionen auswerten, um ihre Produkte zu verbessern und kundenspezifische Services zu entwickeln (Fraunhofer, 2018).
Soziale Medien und Online-Reputation
In der heutigen digitalen Ära spielen soziale Medien eine Schlüsselrolle in der Markenkommunikation. Sentiment-Analyse-Tools erlauben es Unternehmen, die Stimmungen und Meinungen in sozialen Medien zu verfolgen und darauf zu reagieren (Meltwater, n.d.). Diese Erkenntnisse sind besonders für das Reputation Management von Bedeutung, um schnell auf negative Äußerungen zu reagieren und Krisenmanagement zu betreiben (Reputation.com).
Politik und öffentliche Meinung
Die Analyse von Stimmungen in Nachrichtenartikeln, Blogs und Foren kann wertvolle Einblicke in die öffentliche Meinung bieten. Politische Organisationen und Nichtregierungsorganisationen nutzen Sentiment-Analyse, um Kampagnenerfolge zu messen, Wählerstimmungen zu analysieren und Debatten zu monitoren (Mindsquare, n.d.).
Finanzmärkte
Im Bereich der Finanzen wird Sentiment-Analyse dazu genutzt, um aus Nachrichtenartikeln, Berichten und sozialen Medien Stimmungsbilder zu den Finanzmärkten zu gewinnen. Diese Informationen können in Anlagestrategien einfließen und zur Vorhersage von Marktbewegungen beitragen (Altexsoft, n.d.).
Kundenservice und CRM
Kundeninteraktionen und -feedback bieten eine Fülle von Informationen, die durch Sentiment-Analyse effektiv genutzt werden können. Support-Tickets, E-Mail-Korrespondenz und Chat-Protokolle können analysiert werden, um den Kundenservice zu verbessern und personalisierte Erfahrungen zu schaffen (Userlike, n.d.).
Gesundheitswesen
Im Gesundheitswesen wird Sentiment-Analyse angewandt, um Patientenfeedback und Erfahrungsberichte auszuwerten. Dies kann Einrichtungen dabei helfen, die Qualität der Versorgung zu verbessern und Patientenzufriedenheit zu steigern (Indatallabs, n.d.).
Produktentwicklung und Innovation
Unternehmen können Sentiment-Analyse nutzen, um Feedback zu ihren Produkten zu sammeln und dieses in den Entwicklungsprozess einfließen zu lassen. Sie bietet damit eine Grundlage für Innovationsprozesse und kann entscheidend zur Produktverbesserung beitragen (Computerwoche, n.d.).
Personalwesen und Mitarbeiterengagement
Auch im Personalwesen kann die Sentiment-Analyse genutzt werden, um Stimmungen und Meinungen von Mitarbeitern aus Umfragen, Feedback-Systemen oder sozialen Netzwerken zu analysieren. So lassen sich Unternehmenskultur verbessern und Mitarbeiterengagement fördern (Forsta, n.d.).
Die vielfältigen Anwendungsbereiche der Sentiment-Analyse zeigen, wie breit gefächert ihr Potenzial ist. Sie hat sich als wertvolles Werkzeug in vielen Branchen etabliert, da sie eine tiefere Einsicht in menschliche Emotionen und Meinungen bietet und damit Entscheidungen auf einer informierteren Basis getroffen werden können. Fortlaufende Fortschritte im Bereich des Maschinellen Lernens und der natürlichen Sprachverarbeitung werden die Fähigkeiten und die Genauigkeit der Sentiment-Analyse in der Zukunft weiter steigern (Alexander Thamm GmbH, n.d.; Symanto, n.d.; Towards Data Science, n.d.).
Geschichte und Entwicklung der Sentiment-Analyse
Die Geschichte dieses in den letzten Jahren rapide gewachsenen Forschungszweiges ist sowohl ebenso faszinierend wie auch tief verwurzelt in verschiedenen Disziplinen der Wissenschaft.
Ursprünge der Sentiment-Analyse
Bereits im 18. und 19. Jahrhundert war man an der Analyse von Textstimmungen interessiert, wie Studien zu Literatur und der Verlauf historischer Ereignisse belegen. Jedoch war die Analyse zu jener Zeit rein manuell und subjektiv, von individuellen Interpreten abhängig. Mit der Digitalisierung der Texte und der Entwicklung der Informatik begann die Sentiment-Analyse, sich als ein eigenständiges Forschungsfeld zu etablieren.
In den frühen 2000er Jahren nahm das Interesse an der Sentiment-Analyse beachtlich zu, hauptsächlich getrieben durch das Wachstum des Internets und die Explosion von Nutzer-generierten Inhalten, wie Produktbewertungen, Blogs, Foren und Sozialen Medien. Die Fähigkeit, automatisch die Stimmung der Menschen, seien es Kundenbewertungen oder öffentliche Meinungen, zu erfassen und auszuwerten, wurde für Unternehmen und Organisationen immer wertvoller.
Frühe Methoden und Fortschritte
Die ersten Ansätze der computergestützten Sentiment-Analyse basierten auf einfachen Lexika, die Wörter in positive, negative oder neutrale Kategorien einordneten. Während diese Herangehensweise grundlegend war, offenbarte sie schnell ihre Grenzen bezüglich Kontextsensitivität und der Komplexität menschlicher Sprache.
Mit dem Fortschritt in der Sprachverarbeitung entwickelten Forscher ausgefeiltere Techniken, wie maschinelles Lernen, um Muster innerhalb der Daten zu erkennen und basierend darauf Stimmungen vorherzusagen. Die Verwendung von Algorithmen wie Naive Bayes, Support Vector Machines und später tiefen neuronalen Netzwerken erlaubte es, wesentlich nuancierter und genauer auf die vielschichtigen Dimensionen der Sprache einzugehen.
Die Rolle von Big Data und KI
Das Aufkommen von Big Data und die Verbesserung von KI-Technologien spielten eine entscheidende Rolle in der Weiterentwicklung der Sentiment-Analyse. Forschungen im Bereich des maschinellen Lernens und der Verarbeitung natürlicher Sprache (NLP) führten zur Entwicklung von Modellen, die in der Lage sind, Ironie, Sarkasmus und kulturelle Nuancen zu verstehen, wodurch die Genauigkeit der Sentiment-Analyse erheblich verbessert wurde.
Deep Learning und neuronale Netzwerke ermöglichten es, aus riesigen Datenmengen zu lernen und Sentiments auf einer feinkörnigeren Ebene zu identifizieren, einschließlich Emotionserkennung auf Satz- und sogar Wortebene. Transformer-Modelle wie BERT (Bidirectional Encoder Representations from Transformers) und GPT-3/4 (Generative Pre-trained Transformer 3/4) haben die Leistungsfähigkeit der Sentiment-Analyse weiter revolutioniert.
Anwendungen und Einfluss
Die praktischen Anwendungen der Sentiment-Analyse sind weitreichend und beeinflussen viele Branchen. Von der Bewertung der Kundenstimmung über soziale Medien-Überwachung und Marktanalyse bis hin zur Finanzwelt, wo sie zur Vorhersage von Aktienkursbewegungen basierend auf den Stimmungen in Nachrichten und Berichten genutzt wird.
Darüber hinaus hat die Sentiment-Analyse auch in die Politikwissenschaft Einzug gehalten, wo sie dazu verwendet wird, die öffentliche Meinung und Reaktionen auf Kampagnen in Echtzeit zu messen. Die zunehmende Integration von Sentiment-Analyse-Tools in Kundendienstsysteme und Gesundheitsdienste zeigt die Vielfalt und die Potenziale des Einsatzes.
Kritische Betrachtungen und zukünftige Entwicklungen
Trotz des beeindruckenden Fortschritts bleibt die Sentiment-Analyse ein komplexes und herausforderndes Feld. Ironie, regionale Ausdrucksweisen und der sich ständig ändernde Gebrauch von Sprache stellen laufend Hürden dar, die es zu überwinden gilt. Darüber hinaus ergeben sich ethische Fragen im Zusammenhang mit Datenschutz und Verzerrungen innerhalb von Trainingsdaten.
Aktuelle Forschungen konzentrieren sich auf die weitere Verfeinerung der Algorithmen und Modelle, um eine noch präzisere und kontextbezogene Analyse von Sentiments zu ermöglichen, sowie auf die Entwicklung von Ansätzen, die fair und ohne Vorurteile Meinungen erfassen können. Mit dem Anstieg an rechnerischer Leistung und der ständigen Weiterentwicklung von Algorithmen ist zu erwarten, dass die Sentiment-Analyse weiter an Bedeutung gewinnen und neue Anwendungsfelder erschließen wird.
Grundlagen der Sentiment-Analyse
Linguistische Prinzipien
Sentiment-Analyse ist ein interdisziplinäres Forschungsfeld, das Techniken aus der Linguistik, Informatik und künstlichen Intelligenz kombiniert, um aus textuellen Daten subjektive Informationen zu gewinnen. Im Rahmen dieses Unterkapitels werden die linguistischen Prinzipien der Sentiment-Analyse ausführlich betrachtet.
Die Rolle der Linguistik in der Sentiment-Analyse
Die Linguistik spielt eine zentrale Rolle in der Sentiment-Analyse, da die Interpretation von Emotionen und Meinungen stark von der Verarbeitung natürlicher Sprache abhängt (Minsky, „Emotion Machine“, dlg.org). Die Auswertung von Sprachstrukturen, lexikalischen Wahlen und syntaktischen Konstruktionen ist entscheidend, um den Ton und die Stimmungen in Texten erfolgreich zu erkennen und zu interpretieren (Pedocs).
Konversationsanalyse, ein Teildisziplin der Linguistik, untersucht, wie Sprecher in einem Dialog Emotionen und Einstellungen vermitteln. Diese Erkenntnisse sind wesentlich für die Entwicklung von Algorithmen, die sprachliche Nuancen erfassen sollen (Wikipedia: Konversationsanalyse, journals.sagepub.com).
Linguistische Methoden und Theorien in der Praxis
Linguistische Methoden, wie die Diskursanalyse und die Pragmatik, sind ebenso bedeutend für die Sentiment-Analyse. Diese Methoden befassen sich damit, wie Bedeutung im Kontext erstellt wird, welche Rolle Implikaturen spielen und wie Intonation das Verständnis von Sentiments beeinflusst (aclanthology.org).
Die Automatisierung der Sentiment-Analyse beruht auf theoretischen Modellen, wie der Valenz-Arousal-Theorie, die Emotionen anhand von zwei Dimensionen kategorisiert: Angenehmheit (Valenz) und Erregungsgrad (Arousal). Diese Modelle helfen, emotionale Zustände einzuordnen und somit computergestützte Analysen zu erleichtern (fortext.net, cloud.google.com).
Anwendung von linguistischen Prinzipien in Sentiment-Analysesystemen
Moderne Sentiment-Analysesysteme nutzen linguistische Prinzipien, um Muster und Strukturen im Text zu erkennen. Dazu zählen die Identifikation von Schlüsselwörtern, die für positive oder negative Emotionen stehen, die Betrachtung von Modifikatoren und Verstärkern (Adverbien, Adjektive) und das Verstehen von Ironie und Sarkasmus (mindsquare.de, landtag.nrw.de).
Sprachwissenschaftler entwickeln lexikonbasierte Ansätze, die Wörterbücher von Emotionsbegriffen verwenden, und maschinenlernbasierte Ansätze, die anhand von trainierten Datensätzen lernen, Emotionen automatisch zu klassifizieren. Diese Datensätze können beispielsweise aus Produktbewertungen oder sozialen Medien stammen und ermöglichen es, verschiedene Sprachstile und Genres zu analysieren (ResearchGate, kobra.uni-kassel.de).
Diskriminierungsrisiken und ethische Aspekte
Eine signifikante Herausforderung der Sentiment-Analyse ist die Vermeidung von Diskriminierung und Bias. Die Untersuchung der linguistischen Prinzipien bietet Einblicke, wie solche Probleme entstehen können, etwa durch verzerrte Trainingsdaten oder die Fehlinterpretation von Kontext und Mehrdeutigkeiten (Antidiskriminierungsstelle, edpb.europa.eu).
Ethik in der Sentiment-Analyse erfordert daher einen sorgfältigen Umgang mit Sprachdaten und einen bewussten Einsatz der entsprechenden Technologien, um zu vermeiden, dass Minderheiten oder einzelne Gruppen vorverurteilt werden (uni-hannover.de, uni-hildesheim.de).
Fazit und Ausblick
Das Verständnis der linguistischen Prinzipien in der Sentiment-Analyse eröffnet neue Perspektiven für die Analyse menschlicher Emotionen und Meinungen. Während computergestützte Methoden immer ausgefeilter werden, bleibt die detaillierte Auseinandersetzung mit Sprachmustern und deren Bedeutungen unverzichtbar für die Genauigkeit und Fairness dieser Systeme.
Die kontinuierliche Entwicklung in diesem Bereich erfordert eine interdisziplinäre Zusammenarbeit, um fortschrittliche Algorithmen zu entwickeln, die in der Lage sind, die Subtilitäten der menschlichen Sprache zu erfassen und adäquat zu interpretieren. Zukünftige Forschung könnte sich darauf konzentrieren, wie Sentiment-Analyse genutzt werden kann, um soziale Dynamiken besser zu verstehen und als Werkzeug für gesellschaftlichen Fortschritt zu fungieren.
Textverarbeitung und Normalisierung in der Sentiment-Analyse
Die Sentiment-Analyse ist ein Bereich des Natural Language Processing (NLP), der darauf abzielt, die Stimmung oder Meinung in Texten zu erkennen und zu klassifizieren. Damit Computer diese Stimmung analysieren können, muss der Text zunächst verarbeitet und normalisiert werden. Dies ist ein entscheidender Schritt, der sich direkt auf die Qualität und Genauigkeit der Analyse auswirkt.
Textverarbeitung
Zu Beginn der Textverarbeitung steht die Datenvorbereitung, bei der Texte aus verschiedenen Quellen gesammelt und bereinigt werden. In der Textanalyse geht es darum, relevante Informationen aus einem Textkorpus zu extrahieren und ihn für die computerbasierte Analyse aufzubereiten.
Tokenisierung
Der erste Schritt ist üblicherweise die Tokenisierung, bei der Text in kleinere Einheiten, sogenannte Tokens, unterteilt wird. Diese Tokens können Wörter, Phrasen oder sogar einzelne Zeichen sein. Tools wie RQDA bieten Funktionen, um diesen Prozess zu unterstützen und zu vereinfachen.
Entfernen von Stoppwörtern
Nach der Tokenisierung folgt häufig das Entfernen von Stoppwörtern. Stoppwörter sind Wörter, die häufig auftreten, aber in der Regel wenig zum Verständnis des Inhalts beitragen, wie zum Beispiel „der“, „und“, „ist“ usw. Verschiedene NLP-Bibliotheken bieten Listen dieser Wörter, die angepasst und erweitert werden können.
Lemmatisierung und Stemming
Lemmatisierung und Stemming sind Techniken, um Wörter auf ihre Grundform zu reduzieren. Lemmatisierung berücksichtigt die Morphologie der Wörter und Stemming schneidet Endungen ab, um auf den Wortstamm zu reduzieren. Diese Schritte helfen, die Vielfalt der Wortformen zu reduzieren und die Datenmenge handhabbarer zu machen.
Der Hauptunterschied liegt darin, dass die Lemmatisierung die morphologische Analyse der Wörter berücksichtigt, um ihre kanonische Form oder das Lemma zu finden, während das Stemming einfach den Wortstamm ohne Berücksichtigung des Kontexts oder der Korrektheit abschneidet.
Hier sind fünf Beispiele, die den Unterschied zwischen Lemmatisierung und Stemming verdeutlichen:
- Laufen
- Lemmatisierung: „laufen“ → „laufen“ (unverändert, da bereits in Grundform)
- Stemming: „laufen“ → „lauf“ (Abschneiden des Suffixes)
- Gelaufen
- Lemmatisierung: „gelaufen“ → „laufen“ (Rückführung auf das Infinitiv-Verb)
- Stemming: „gelaufen“ → „gelauf“ (Abschneiden des Suffixes)
- Bessere
- Lemmatisierung: „bessere“ → „gut“ (Rückführung auf das Adjektiv in Grundform)
- Stemming: „bessere“ → „besser“ (Abschneiden des Suffixes)
- Mäuse
- Lemmatisierung: „Mäuse“ → „Maus“ (Rückführung auf Singularform)
- Stemming: „Mäuse“ → „Mäus“ (Abschneiden des Suffixes)
- Am schnellsten
- Lemmatisierung: „am schnellsten“ → „schnell“ (Rückführung auf das Adjektiv in Grundform)
- Stemming: „am schnellsten“ → „am schnell“ (Einfaches Abschneiden ohne Berücksichtigung der korrekten Wortform)
Diese Beispiele zeigen, dass Lemmatisierung darauf abzielt, das korrekte Lemma eines Wortes zu finden, welches oft die Basisform (wie Infinitiv bei Verben oder Singular bei Substantiven) ist. Stemming hingegen schneidet einfach Endungen ab, was oft zu Formen führt, die keine gültigen Wörter sind. Lemmatisierung ist komplexer und berücksichtigt den linguistischen Kontext des Wortes, während Stemming einfacher ist und schneller ausgeführt werden kann.
Groß- und Kleinschreibung
Das Umwandeln aller Buchstaben in Kleinschreibung ist eine weitere gängige Normalisierungstechnik, um die Konsistenz im Text zu gewährleisten und die Anzahl unterschiedlicher Tokens zu verringern.
Normalisierung
Normalisierung umfasst eine Reihe von Prozessen, um Textdaten in ein einheitliches Format zu überführen. Es handelt sich um eine Vorverarbeitung, die dazu dient, die Varianz im Text zu minimieren, um die Leistung von Algorithmen im maschinellen Lernen zu verbessern.
Min-Max-Normalisierung
Bei der Min-Max-Normalisierung werden numerische Werte im Text (z. B. Daten) in einen Standardbereich umgerechnet (typischerweise zwischen 0 und 1), was vor allem in Bezug auf die Maßeinheiten Konsistenz schafft.
Hier sind einige Beispiele, wie das in einem Textkorpus aussehen könnte:
- Vor der Normalisierung: „Im Jahr 1990 hatte die Stadt 500.000 Einwohner.“ Nach der Normalisierung: „Im Jahr 0.72 hatte die Stadt 0.5 Einwohner.“ (angenommen, das Jahr 1990 wird relativ zu einem Bereich von 1900 bis 2000 und die Bevölkerungszahl relativ zu 0 bis 1 Million normalisiert)
- Vor der Normalisierung: „Das Produkt kostet 300 Euro.“ Nach der Normalisierung: „Das Produkt kostet 0.3 Euro.“ (angenommen, der Preisbereich wird von 0 bis 1000 Euro normalisiert)
- Vor der Normalisierung: „Die Temperatur beträgt 20 Grad Celsius.“ Nach der Normalisierung: „Die Temperatur beträgt 0.4.“ (angenommen, die Temperatur wird in einen Bereich von 0 bis 50 Grad normalisiert)
- Vor der Normalisierung: „Die Reise dauerte 10 Stunden.“ Nach der Normalisierung: „Die Reise dauerte 0.42 Stunden.“ (angenommen, die Dauer wird relativ zu einem Bereich von 0 bis 24 Stunden normalisiert)
- Vor der Normalisierung: „Die Distanz beträgt 150 Kilometer.“ Nach der Normalisierung: „Die Distanz beträgt 0.15.“ (angenommen, die Distanz wird in einen Bereich von 0 bis 1000 Kilometer normalisiert)
Batch-Normalisierung und Layer-Normalisierung
Diese Techniken stammen aus dem Bereich des Deep Learning und werden eingesetzt, um die Eingabewerte für jede Schicht eines Netzwerks zu normalisieren. Auch wenn sie primär bei der Bildverarbeitung verwendet werden, finden sie in modifizierter Form Anwendung bei der Verarbeitung von Textdaten in tiefen neuronalen Netzwerken.
Die Beispiele für diese Arten der Normalisierung sind eher abstrakt und technisch, da sie auf die internen Repräsentationen von Daten im Netzwerk angewendet werden:
- Vor der Normalisierung: Eingabewerte eines neuronalen Netzwerks mit hoher Varianz zwischen den Neuronen. Nach der Normalisierung: Eingabewerte sind über alle Neuronen hinweg standardisiert, was die Stabilität des Trainings verbessert.
- Vor der Normalisierung: Unterschiedliche Skalierung der Eingabedaten führt zu langsamer Konvergenz beim Training. Nach der Normalisierung: Einheitliche Skalierung führt zu einer effizienteren Gewichtsanpassung und schnellerer Konvergenz.
- Vor der Normalisierung: Eingabedaten in tieferen Schichten des Netzwerks sind stark korreliert. Nach der Normalisierung: Reduzierung der Korrelation zwischen den Eingabedaten, was zu einer verbesserten Unabhängigkeit der Merkmale führt.
- Vor der Normalisierung: Ein neuronales Netzwerk ist anfällig für das Problem des verschwindenden oder explodierenden Gradienten. Nach der Normalisierung: Stabilisierung der Gradienten, was das Training von tiefen Netzwerken erleichtert.
- Vor der Normalisierung: Unterschiedliche Aktivierungsniveaus in verschiedenen Schichten des Netzwerks. Nach der Normalisierung: Angleichung der Aktivierungsniveaus über das Netzwerk, was zu einer gleichmäßigeren Informationsverarbeitung führt.
Wissensgraphen und kontextuelle Intelligenz
Wissensgraphen sind eine aufkommende Methode, um semantische Beziehungen und Bedeutungen in Textdaten zu berücksichtigen. Ontotext bietet solche Analysen an, die durch das Verknüpfen von Textdaten mit externem Kontext eine reichhaltigere und tiefere Analyse ermöglichen.
Die Funktionsweise der Wissensgraphen möchte ich anhand eines Beispiels verdeutlichen:
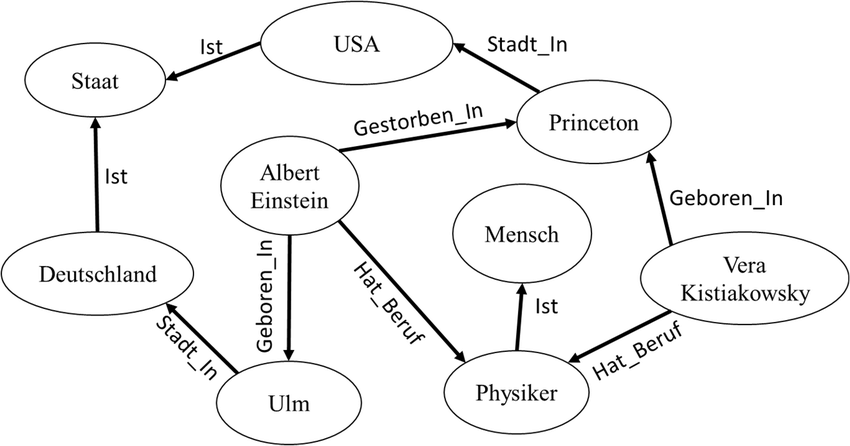
Ausgangssituation: In einer fiktiven Forschungsdatenbank für historische Persönlichkeiten wollen wir die Beziehungen zwischen verschiedenen Individuen, ihren Berufen, den Orten, an denen sie geboren wurden oder gestorben sind, und den Staaten, zu denen diese Orte gehören, verstehen.
Ziel: Das Ziel ist es, ein klareres Bild der Verbindungen zwischen Personen, Orten und Staaten zu erhalten und wie diese Elemente zusammenwirken. Zum Beispiel wollen wir verstehen, welche berühmten Physiker in Deutschland geboren wurden und in den USA gestorben sind.
Prozess:
- Aufbau des Wissensgraphen:
- Wir nutzen den vorhandenen Wissensgraphen, um unsere Datenbank zu erstärken. Der Graph zeigt bereits Verbindungen zwischen Personen wie Albert Einstein und Vera Kistiakowsky, ihren Berufen (Physiker), und Orten (Ulm, Princeton), sowie den zugehörigen Staaten (Deutschland, USA).
- Extraktion und Verknüpfung von Informationen:
- Aus dem Graphen entnehmen wir, dass Albert Einstein in Deutschland, genauer in Ulm, geboren wurde, was ein Teil des Staates Deutschland ist. Weiterhin wurde er als Physiker klassifiziert und ist in den USA, in Princeton, gestorben.
- Ähnlich verhält es sich mit Vera Kistiakowsky, die ebenfalls den Beruf Physiker hatte, jedoch fehlen in diesem Graphen Informationen über Geburts- und Sterbeort.
- Anreicherung und Analyse:
- Um unseren Wissensgraphen zu erweitern, suchen wir in unserer Datenbank nach weiteren Physikern, die ähnliche Verbindungen wie Albert Einstein haben könnten. Wir suchen nach weiteren Individuen, die in Deutschland geboren wurden und in den USA gestorben sind.
- Gleichzeitig erweitern wir die Informationen über Vera Kistiakowsky, indem wir ihren Geburts- und Sterbeort recherchieren und diese Informationen dem Graphen hinzufügen.
- Visualisierung und Erkenntnisgewinnung:
- Die visuelle Darstellung unseres erweiterten Wissensgraphen hilft uns, Muster zu erkennen, wie zum Beispiel die Migration von Wissenschaftlern im 20. Jahrhundert oder die Beziehung zwischen Geburtsorten und späteren wissenschaftlichen Leistungen.
- Wir können auch die Bedeutung von Städten wie Princeton für die wissenschaftliche Gemeinschaft erkennen, indem wir sehen, wie viele bedeutende Wissenschaftler dort gearbeitet haben oder gestorben sind.
- Schlussfolgerungen:
- Durch die Analyse des Wissensgraphen verstehen wir besser, wie die historische und geographische Bewegung von Wissenschaftlern wie Physikern die wissenschaftliche Entwicklung beeinflusst hat.
- Diese Informationen können genutzt werden, um Bildungseinrichtungen, Forschungsinstitutionen und politische Entscheidungsträger über die historischen Trends und ihre möglichen Auswirkungen auf die heutige Wissenschaftslandschaft zu informieren.
Ergebnis: Mit Hilfe des Wissensgraphen konnten wir umfassende Einsichten in die Beziehungen und historischen Muster von Persönlichkeiten in der Wissenschaft gewinnen. Dies ermöglicht es uns, nicht nur isolierte Datenpunkte zu betrachten, sondern auch die reichen Kontexte und Netzwerke, die diese Persönlichkeiten umgeben und geformt haben.
Qualitative Inhaltsanalyse
Die qualitative Inhaltsanalyse ist eine Forschungsmethode, die es ermöglicht, strukturiert und systematisch Textdaten zu analysieren. Nach dem von Philipp Mayring entwickelten Ansatz wird der Text in kleinere Einheiten zerlegt, die dann codiert und interpretiert werden. Dieser Prozess beruht auf einer Reihe von Regeln und Kategorien, die aus dem Text selbst oder aus theoretischen Überlegungen abgeleitet sind. Ziel ist es, ein tiefes Verständnis des Textes und seiner Bedeutungsebenen zu erlangen.
Mayrings Ansatz ist besonders hilfreich, wenn es darum geht, komplexe Textdaten zu analysieren, wie sie beispielsweise in der Sentiment-Analyse vorkommen. Hierbei werden Texte nicht nur auf ihren faktischen Inhalt hin untersucht, sondern auch bezüglich der darin ausgedrückten Gefühle und Meinungen. Durch die Definition von affektiven Codes können Forschende subjektive Aussagen systematisch klassifizieren und so die vorherrschenden Stimmungen und Einstellungen in Textdaten erfassen.
Beispiel für die Anwendung der Qualitativen Inhaltsanalyse in der Sentiment-Analyse:
Angenommen, wir möchten die Kundenbewertungen eines neuen Smartphones analysieren, um die Stimmung der Kunden gegenüber dem Produkt zu verstehen. Die Bewertungen liegen in Textform vor und enthalten eine Mischung aus Fakten und Meinungen.
- Datensammlung:
- Zunächst sammeln wir eine repräsentative Stichprobe von Kundenbewertungen aus verschiedenen Quellen wie Online-Shops, Foren und sozialen Medien.
- Entwicklung des Codierleitfadens:
- Wir entwickeln einen Codierleitfaden, der Kategorien enthält, die sowohl positive als auch negative Gefühle widerspiegeln. Zum Beispiel könnten Kategorien für positive Sentiments „Zufriedenheit“, „Begeisterung“ und „Empfehlungsbereitschaft“ sein, während Kategorien für negative Sentiments „Enttäuschung“, „Frustration“ und „Kritik“ umfassen könnten.
- Codierung des Materials:
- Jede Kundenbewertung wird nun sorgfältig gelesen und die relevanten Textstellen den entsprechenden affektiven Codes zugeordnet. Zum Beispiel wird der Satz „Ich liebe das klare Display und die lange Akkulaufzeit des Smartphones!“ dem positiven Code „Begeisterung“ zugeordnet.
- Interpretation der Ergebnisse:
- Nachdem alle Daten codiert wurden, analysieren wir die Häufigkeit und den Kontext der verschiedenen Codes, um die allgemeine Stimmung der Kundenbewertungen zu interpretieren. Wenn zum Beispiel der Code „Begeisterung“ deutlich häufiger vorkommt als „Frustration“, könnten wir schließen, dass die Kunden im Allgemeinen sehr zufrieden mit dem Smartphone sind.
- Exemplarische Verdichtung:
- Für eine detailliertere Analyse könnte man einzelne Bewertungen herausgreifen, die exemplarisch für bestimmte Sentiments stehen. Ein Kunde könnte beispielsweise geschrieben haben: „Ich bin so enttäuscht von der Kamera. Bei schlechten Lichtverhältnissen sind alle Bilder unscharf.“ Diese Bewertung würde den negativen Code „Enttäuschung“ erhalten und könnte im Bericht detailliert diskutiert werden, um die Probleme mit der Kamera zu veranschaulichen.
Durch die qualitative Inhaltsanalyse nach Mayring können wir also nicht nur quantitative Aussagen über die Häufigkeit bestimmter Sentiments treffen, sondern auch die tiefer liegenden Gründe für die Kundeneinstellungen verstehen. Dies ermöglicht es Unternehmen, gezielte Verbesserungen vorzunehmen und auf Kundenbedürfnisse einzugehen.
Implementierung und Tools
Für die Umsetzung stehen zahlreiche Tools zur Verfügung, darunter
- R-Pakete wie tm (Text Mining Package) und sentimentr,
- Python-Bibliotheken wie NLTK und TextBlob,
- sowie Plattformen wie Google Cloud Natural Language API und Amazon Comprehend, die Funktionen für die Sentiment-Analyse anbieten.
Beim Aufbau einer Pipeline für die Sentiment-Analyse ist es wichtig, die genannten Schritte der Textverarbeitung und Normalisierung sorgfältig zu planen und anzuwenden, um die Grundlagen für eine verlässliche und aussagekräftige Analyse zu legen.
Feature-Extraktion in der Sentiment-Analyse
Zentral für die Sentiment-Analyse ist die Feature-Extraktion, bei der es darum geht, aus Textdaten Muster oder Eigenschaften (Features) zu gewinnen, die für das Erkennen von Sentiments hilfreich sind.
Was ist Feature-Extraktion?
Feature-Extraktion ist ein Prozess, bei dem aus Rohdaten relevante Informationen extrahiert werden, um maschinelle Lernmodelle effektiv zu trainieren. Bei der Analyse von Texten kann dies beispielsweise das Herausfiltern bestimmter Wörter, Phrasen oder syntaktischer Strukturen sein. Die Qualität und Relevanz der extrahierten Features können einen signifikanten Einfluss auf die Leistung des Machine Learning-Modells haben.
Methoden der Feature-Extraktion
1. Bag of Words (BoW):
Das BoW-Modell ist eine der einfachsten Techniken zur Feature-Extraktion. Es wandelt Text in einen Satz von Features um, indem es die Häufigkeit der Wörter im Text zählt, ohne deren Reihenfolge oder Kontext zu berücksichtigen. Scikit-learn bietet ausgezeichnete Werkzeuge zur Implementierung des BoW-Modells (http://scikit-learn.org/stable/modules/feature_extraction.html).
2. TF-IDF (Term Frequency-Inverse Document Frequency):
TF-IDF ist eine statistische Methode, die gewichtet, wie wichtig ein Wort in einem Dokument im Vergleich zu einer Sammlung von Dokumenten ist. Dies reduziert die Gewichtung von häufig vorkommenden Wörtern und erhöht die Gewichtung von Wörtern, die seltener im gesamten Korpus auftreten.
3. Word Embeddings:
Wort-Einbettungen wie Word2Vec, GloVe oder FastText wandeln Wörter in dichte Vektoren um, die semantische Ähnlichkeiten zwischen den Wörtern einfangen. Diese Techniken können dazu beitragen, tiefer liegende semantische Dimensionen zu erfassen.
4. Entity & Aspect Extraction:
Entities (Namen, Orte, Organisationen) und Aspekte (spezifische Eigenschaften von Produkten oder Dienstleistungen) können wichtige Hinweise auf die Sentiments in einem Text geben. Verschiedene Tools und Frameworks wie Google Cloud Natural Language (https://cloud.google.com/natural-language/docs/basics?hl=de) und MonkeyLearn (https://monkeylearn.com/blog/entity-extraction/) bieten Funktionen, um diese Informationen aus Texten zu extrahieren.
5. Syntactic Parsing:
Das syntaktische Parsing hilft, die grammatische Struktur von Sätzen zu verstehen. Dependenz-Parser können Stimmung tragende Phrasen identifizieren und verstärken, zum Beispiel durch Negationen oder Intensivierungen.
6. Feature Selection:
Nicht alle extrahierten Features tragen gleichmäßig zur Sentiment-Detektion bei. Verfahren zur Feature-Selection wie „Chi-squared tests“ oder „Mutual Information“ können dazu beitragen, die Feature-Sets zu verfeinern und zu optimieren.
Bedeutung im Kontext der Sentiment-Analyse
Für die Sentiment-Analyse sind Features unerlässlich, um zwischen verschiedenen Sentiments, wie Positivität, Neutralität und Negativität, zu unterscheiden. So können spezifische adjektivische oder adverbiale Modifikatoren sowie die Präsenz bestimmter Schlüsselwörter einen starken Indikator für das Vorliegen eines bestimmten Sentiments darstellen. Insbesondere im Bereich des Social Media Monitorings, wo beispielsweise Unternehmen an der Analyse der öffentlichen Meinung zu ihren Produkten interessiert sind, spielt die Sentiment-Analyse eine große Rolle und beeinflusst strategische Unternehmensentscheidungen (https://sproutsocial.com/insights/sentiment-analysis/).
Herausforderungen der Feature-Extraktion
Trotz der Leistungsfähigkeit der o.g. Methoden der Feature-Extraktion gibt es Herausforderungen wie Sarkasmus, Mehrdeutigkeit und Kontextabhängigkeit, die die Analyse erschweren. Zudem kann die Sentiment-Analyse über verschiedene Domainen hinweg variieren, was die Notwendigkeit einer angepassten Feature-Extraktion unterstreicht.
Die Grundlagen der Sentiment-Analyse und deren Techniken zur Feature-Extraktion werden in zahlreichen wissenschaftlichen Publikationen, Lehrmaterialien und Online-Ressourcen behandelt. Hervorzuheben sind Arbeiten aus dem Diesner Lab, von Roman Klinger und verschiedene Artikel und Diskussionen auf Foren wie Data Science Stack Exchange.
Die Auswahl und Aufbereitung der Features ist maßgeblich für den Erfolg der Sentiment-Analyse und bleibt ein aktives Forschungsfeld in der Literatur und Anwendungsbereiche, die von Market Research bis Healthcare reichen.
Klassifikation von Sentiments
Einleitung
Die Sentiment-Klassifikation bildet einen integralen Bestandteil der computergestützten Sentiment-Analyse, welche die affektiven Zustände und subjektiven Informationen innerhalb textueller Daten extrahiert und quantifiziert. Dieses Unterkapitel strebt danach, eine umfassende und detaillierte Einführung in die technischen Grundlagen und theoretischen Konzepte der Sentiment-Klassifikation zu liefern, gestützt auf aktuelle wissenschaftliche Erkenntnisse und praktische Anwendungen.
Definition und Zielsetzung
Die Sentiment-Klassifikation ist ein Teilbereich des Natural Language Processing (NLP), der sich auf die automatisierte Identifikation und Kategorisierung subjektiver Informationen in Texten konzentriert. Der Prozess beinhaltet das Zuordnen von Textsegmenten zu spezifischen affektiven Kategorien, üblicherweise differenziert als positiv, negativ und neutral. Ziel ist es, aus einer großen Menge an unstrukturierten Textdaten nutzbare Informationen über individuelle und kollektive Einstellungen, Meinungen und Emotionen zu extrahieren. Diese Informationen sind für Akteure in der Wirtschaft, in Forschungseinrichtungen und sozialen Institutionen von unschätzbarem Wert, da sie tiefergehende Einsichten in Konsumentenverhalten, öffentliche Meinungsbilder und soziokulturelle Dynamiken ermöglichen.
Methodologische Ansätze
Die Klassifikation von Sentiments implementiert ein Spektrum an methodologischen Ansätzen, die von heuristischen bis zu modellbasierten Techniken reichen. Auf der einen Seite stehen lexikalische Ansätze, die sich auf vordefinierte Listen von Schlüsselwörtern und Phrasen mit bekannten affektiven Werten stützen, wie beispielsweise das Harvard IV-4 Psychosocial Dictionary oder SentiWordNet.
Auf der anderen Seite haben sich maschinelle Lernansätze, insbesondere tiefgreifende neuronale Netzwerkarchitekturen, als besonders mächtig erwiesen. Modelle wie BERT (Bidirectional Encoder Representations from Transformers) nutzen Transformer-Architekturen, um kontextuelle Wortbedeutungen durch bidirektionale Kontextualisierung zu erfassen. Dies ermöglicht eine präzisere Analyse von Sentiments, auch unter Berücksichtigung von Ironie, Sarkasmus und impliziten Bedeutungen. Jüngste Forschungen, darunter die von Roman Klinger, haben die Grenzen dieser Ansätze erweitert, indem sie kontextbezogene Feinheiten und semantische Relationen in die Klassifikationsprozesse integrieren.
Praktische Anwendung
Die praktische Anwendung der Sentiment-Klassifikation erstreckt sich über diverse Domänen. Unternehmen nutzen sie, um aus Produktbewertungen, Kundenfeedback und sozialen Medien Stimmungsbilder zu generieren. In der Marktanalyse ermöglicht die fortwährende Entwicklung neuer Metriken und Analyseverfahren eine zunehmend differenzierte Interpretation von Daten und damit eine verfeinerte Verbraucher- und Markteinsicht.
Beispiel einer Sentiment-Analyse: Eine Rezension könnte lauten: „Das X-Phone 3000 hat ein beeindruckendes Display, aber die Akkulaufzeit ist enttäuschend.“
- Das BERT-Modell erkennt „beeindruckend“ als positiv für das Display und „enttäuschend“ als negativ für die Akkulaufzeit.
- Diese Rezension würde daher gemischte Sentiments reflektieren: positiv für die Displayqualität und negativ für die Batterieleistung.
Ethische Betrachtung
Ethische Überlegungen spielen in der Sentiment-Klassifikation eine entscheidende Rolle, insbesondere hinsichtlich des Datenschutzes und der Informationsautonomie der Individuen. Der verantwortungsvolle Umgang mit personenbezogenen Meinungsäußerungen ist von zentraler Bedeutung. Institutionen wie der Deutsche Ethikrat haben diesbezüglich Stellungnahmen veröffentlicht, die eine normative Grundlage für den ethischen Einsatz KI-basierter Analysetechnologien bieten.
Schlussfolgerung
Die Sentiment-Klassifikation ist eine fortgeschrittene und sich kontinuierlich entwickelnde Disziplin, die ein fundiertes Verständnis von maschinellem Lernen, linguistischen Prinzipien und ethischen Standards erfordert. Die zukünftigen Entwicklungen in diesem Bereich versprechen ein erweitertes Verständnis menschlicher Emotionen und Meinungen sowie deren Auswirkungen auf gesellschaftliche und geschäftliche Entscheidungen.
Methoden der Sentiment-Analyse
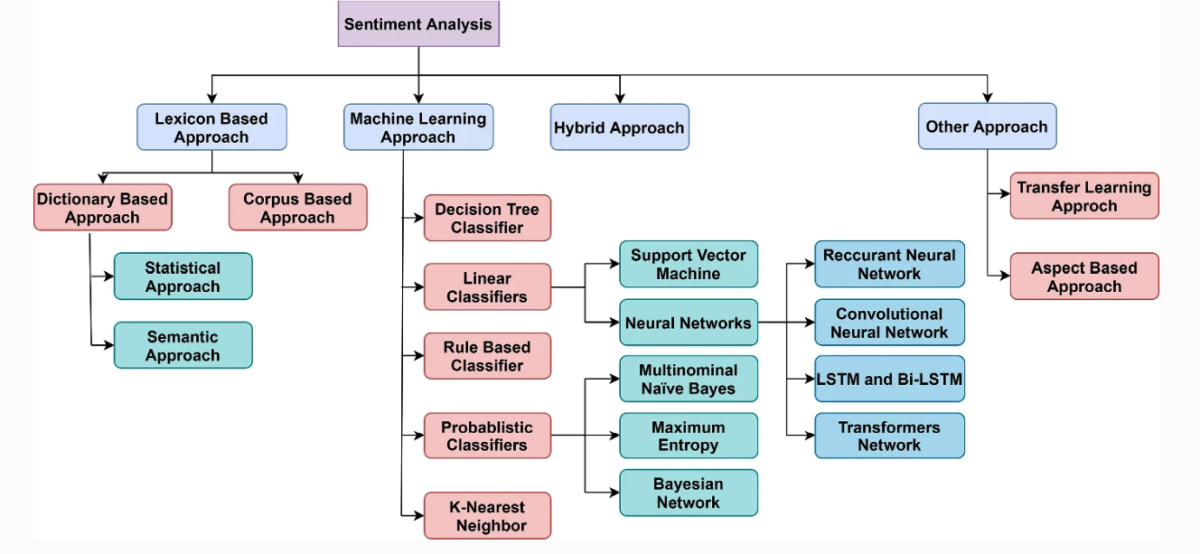
Regelbasierte Ansätze und lexikonbasierte Ansätze in der Sentiment-Analyse
Einleitung
In der Welt der Sentiment-Analyse ergänzen sich regelbasierte und lexikonbasierte Ansätze, um Texte auf ihre emotionale Färbung hin zu analysieren. Während regelbasierte Systeme komplexe linguistische Regeln anwenden, nutzen lexikonbasierte Methoden vordefinierte Sammlungen von emotional gewichteten Wörtern.
Grundprinzipien
Regelbasierte Ansätze stützen sich auf ein Regelwerk, das linguistische Muster und Strukturen erfasst, um den Kontext und die Nuancen der Sprache zu interpretieren. Sie sind in der Lage, die sentimentale Ausrichtung von Wörtern im Satzbau zu erfassen, etwa durch Erkennung von Ironie oder Negationen. Lexikonbasierte Ansätze hingegen verwenden ein Sentiment-Lexikon – beim Dictionary Based Approach oft manuell erstellt, wobei der Statistical Approach auf Frequenzanalysen und der Semantic Approach auf die Beziehungen der Wörter im Kontext setzt. Der Corpus Based Approach extrahiert und lernt Sentiment-Werte aus einem annotierten Textkorpus, was eine dynamische Anpassung an den Sprachgebrauch ermöglicht.
Unterscheidung
Die Unterscheidung zwischen regelbasierten und lexikonbasierten Ansätzen liegt in der Flexibilität und Tiefe der Analyse. Regelbasierte Methoden sind agil und kontextsensitiv, aber oft komplex in der Entwicklung. Lexikonbasierte Methoden bieten hingegen eine schnellere und direkt umsetzbare Analyse, benötigen jedoch eine Kombination von statistischen und semantischen Techniken, um präzise zu sein. Der Corpus Based Approach erweitert die lexikonbasierten Methoden um eine lernfähige Komponente, die in der Lage ist, sich an neue Ausdrucksweisen anzupassen. Zusammen können diese Ansätze die Präzision der Sentiment-Analyse verbessern und ein umfassendes Verständnis von Textdaten ermöglichen.
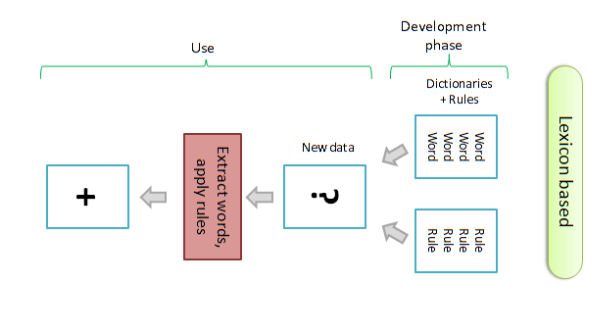
Lexikonbasierte Ansätze
- Wortlisten: Lexikonbasierte Ansätze verwenden Listen von Wörtern mit vorab zugewiesenen Sentiment-Werten. Diese Listen, oft als „Sentiment-Lexika“ bezeichnet, enthalten Wörter, die positiv, negativ oder neutral geladen sind.
- Einfache Bewertung: Die Sentiment-Analyse basiert auf der Summierung der Sentiment-Werte der Wörter, die im Text vorkommen. Manche Modelle berücksichtigen auch die Intensität der Sentiments durch gewichtete Werte.
- Keine oder geringe Kontextberücksichtigung: Traditionelle lexikonbasierte Ansätze berücksichtigen selten den Kontext, in dem ein Wort verwendet wird, was zu Ungenauigkeiten führen kann, insbesondere bei Ironie, Sarkasmus oder doppelsinnigen Ausdrücken.
Regelbasierte Ansätze
- Komplexe Regeln: Regelbasierte Ansätze nutzen ein Set von definierten Regeln, die auf die Textstruktur und -syntax eingehen. Diese Regeln können sich auf Wortkombinationen, Satzbau, Satzzeichen und weitere linguistische Faktoren beziehen.
- Erweiterte Logik: Die Regeln können komplex sein und beispielsweise die Verstärkung oder Abschwächung von Sentiments durch Modifikatoren (sehr, kaum), Negationen (nicht, kein) oder Konjunktionen (aber, jedoch) einbeziehen.
- Kontextbewusstsein: Regelbasierte Ansätze können mehr Kontext einbeziehen als einfache lexikonbasierte Modelle. Sie können spezifische sprachliche Muster identifizieren und sind potenziell besser darin, komplexere sprachliche Nuancen zu erkennen.
Gemeinsamkeiten
Beide Ansätze haben das Ziel, Texte auf der Basis von vordefinierten Sentiment-Indikatoren zu analysieren, und beide können ohne maschinelles Lernen auskommen. Zudem können lexikonbasierte Ansätze Teil eines regelbasierten Systems sein, wenn die Wörter des Lexikons durch zusätzliche Regeln ergänzt werden.
Kombinierte Ansätze
In der Praxis werden lexikon- und regelbasierte Ansätze oft kombiniert, um die Stärken beider Methoden zu nutzen und ihre Schwächen zu kompensieren. Zum Beispiel kann ein regelbasiertes System ein Sentiment-Lexikon verwenden, um grundlegende Sentiment-Werte zu erhalten, und dann zusätzliche Regeln anwenden, um den Kontext und die Syntax für eine genauere Sentiment-Analyse zu berücksichtigen.
Beispiele
lexikonbasierte Klassifikation
Lexikonbasierte Sentiment-Analyse: Normales Kundenfeedback
Kundenfeedback: „Ich bin sehr zufrieden mit dem Service im Café. Die Mitarbeiter sind immer freundlich und der Kaffee schmeckt hervorragend.“
Lexikonbasierte Klassifikation:
- Positive Wörter wie „sehr zufrieden“, „freundlich“ und „hervorragend“ sind wahrscheinlich im Sentiment-Lexikon als positiv verzeichnet.
- Der lexikonbasierte Ansatz würde dieses Feedback ebenfalls als positiv klassifizieren, da die verwendeten Wörter positiv konnotiert sind.
Lexikonbasierte Sentiment-Analyse: Ironisches Kundenfeedback
Kundenfeedback: „Großartig, ich musste nur 30 Minuten auf meinen Kaffee warten. So schnell wie ein Blitz.“
Lexikonbasierte Klassifikation:
- Wörter wie „Großartig“ und „schnell“ könnten im Sentiment-Lexikon positiv bewertet sein.
- Ein lexikonbasierter Ansatz würde dieses Feedback vermutlich fälschlicherweise als positiv klassifizieren, da er die ironische Bedeutung nicht erfassen kann.
Lexikonbasierte Sentiment-Analyse: Zynisches Kundenfeedback
Kundenfeedback: „Es ist immer so wunderbar, wenn der Kaffee so lauwarm serviert wird, dass ich meine Hände kaum aufwärmen kann.“
Lexikonbasierte Klassifikation:
- Das Wort „wunderbar“ könnte im Lexikon als positiv verzeichnet sein.
- Ähnlich wie beim regelbasierten Ansatz würde auch der lexikonbasierte Ansatz wahrscheinlich das Feedback als positiv klassifizieren, da er nicht in der Lage ist, den zynischen Kontext zu erkennen.
Lexikonbasierte Sentiment-Analyse: Sarkastisches Kundenfeedback
Kundenfeedback: „Was für eine Freude, dass mein Espresso so stark verdünnt war, dass ich fast dachte, es wäre Wasser.“
Lexikonbasierte Klassifikation:
- „Freude“ würde wahrscheinlich als positives Wort im Lexikon geführt.
- Ohne die Fähigkeit, Sarkasmus zu identifizieren, würde der lexikonbasierte Ansatz dieses Feedback fälschlicherweise als positiv einstufen.
regelbasierte Sentiment-Analyse
Regelbasierte Sentiment-Analyse: Normales Kundenfeedback
Kundenfeedback: „Ich bin sehr zufrieden mit dem Service im Café. Die Mitarbeiter sind immer freundlich und der Kaffee schmeckt hervorragend.“
Regelbasierte Klassifikation:
- Positive Wörter wie „sehr zufrieden“, „freundlich“ und „hervorragend“ werden von der regelbasierten Methode erkannt.
- Das Feedback wird als positiv klassifiziert.
Regelbasierte Sentiment-Analyse: Ironisches Kundenfeedback
Kundenfeedback: „Großartig, ich musste nur 30 Minuten auf meinen Kaffee warten. So schnell wie ein Blitz.“
Regelbasierte Klassifikation:
- Positive Wörter wie „Großartig“ und eine scheinbar positive Phrase „schnell wie ein Blitz“ werden erkannt.
- Ohne Kontextverständnis wird das Feedback fälschlicherweise als positiv klassifiziert, obwohl es ironisch gemeint ist.
Regelbasierte Sentiment-Analyse: Zynisches Kundenfeedback
Kundenfeedback: „Es ist immer so wunderbar, wenn der Kaffee so lauwarm serviert wird, dass ich meine Hände kaum aufwärmen kann.“
Regelbasierte Klassifikation:
- Wörter wie „wunderbar“ werden als positive Indikatoren identifiziert.
- Das Feedback könnte irrtümlicherweise als positiv klassifiziert werden, da die zynische Bedeutung des Kontexts nicht erfasst wird.
Regelbasierte Sentiment-Analyse: Sarkastisches Kundenfeedback
Kundenfeedback: „Was für eine Freude, dass mein Espresso so stark verdünnt war, dass ich fast dachte, es wäre Wasser.“
Regelbasierte Klassifikation:
- Das Wort „Freude“ wird normalerweise positiv bewertet.
- Ohne die Fähigkeit, Sarkasmus zu erkennen, könnte das System dieses Feedback als positiv einstufen, obwohl es tatsächlich negativ ist.
In allen vier Beispielen würde ein lexikonbasierter Ansatz ähnliche Ergebnisse liefern wie ein regelbasierter Ansatz. Beide Methoden sind gut darin, direkte sentimentale Ausdrücke zu erkennen, stoßen aber an ihre Grenzen, wenn es um Ironie, Sarkasmus oder Zynismus geht. Diese komplexen sprachlichen Nuancen erfordern ein tieferes Verständnis des Kontexts, den einfache lexikon- oder regelbasierte Ansätze nicht leisten können. Moderne Methoden des maschinellen Lernens, die auf komplexeren NLP-Techniken basieren, sind in der Lage, solche Feinheiten besser zu erkennen und zu interpretieren.
Herausforderungen und Grenzen
Trotz ihrer Effektivität bei klaren Ausdrücken emotionalen Inhalts, sehen sich regelbasierte Systeme Herausforderungen gegenüber, wenn es um subtilere Kontexte oder Ironie geht. Einzelne Worte können oft mehrdeutig sein, und ohne Kontext ist es schwierig, die korrekte Stimmung zu erkennen. Forschungsarbeiten, wie etwa die im Journal PLOS ONE veröffentlichte Studie, adressieren diese Herausforderungen und suchen nach Wegen, um die Genauigkeit regelbasierter Sentiment-Analysen zu verbessern.
Wissenschaftliche Perspektive und Entwicklung
Die wissenschaftliche Forschung ist kontinuierlich bemüht, die Leistung der regelbasierten Sentiment-Analyse zu erweitern, wie in Studien und Veröffentlichungen auf Plattformen wie ScienceDirect oder in Dissertationen wie der von Herrn Pyshchyk an der Hochschule Ruhr West dargestellt ist. Es geht darum, komplexere Regeln zu entwickeln, die Idiome, Sarkasmus und kontextabhängige Bedeutungen besser erfassen können.
Zusammenfassung und Ausblick
Regelbasierte Ansätze bieten in der Sentiment-Analyse eine solide Grundlage zur Auswertung von Texten im Hinblick auf die darin ausgedrückte Stimmung. Obwohl diese Methoden ihre Limitationen haben, sind sie ein wichtiger Bestandteil eines umfassenden Portfolios an Analysewerkzeugen für NLP-Aufgaben und bleiben ein aktives Forschungsfeld mit erheblichem Entwicklungspotenzial.
Für die Zukunft zeichnet sich ab, dass regelbasierte Systeme zunehmend mit maschinellen Lernmethoden kombiniert werden, um die Genauigkeit und Anpassungsfähigkeit von Sentiment-Analysen weiter zu steigern. Plattformen wie AWS, Elastic und Taus bieten bereits fortschrittliche Analysewerkzeuge an, die aufzeigen, wie die Integration von KI und regelbasierten Ansätzen das Verständnis menschlicher Emotionen in Textform erleichtern könnte.
Durch die fortlaufende Erforschung und Weiterentwicklung der Methoden stellt die regelbasierte Sentiment-Analyse sicher, dass Unternehmen und Organisationen weiterhin tiefe Einblicke in das Meinungsbild ihrer Kunden und Nutzer erhalten können, um darauf aufbauend ihre Produkte und Dienstleistungen zu verbessern.
Automatische Lernmethoden in der Sentiment-Analyse
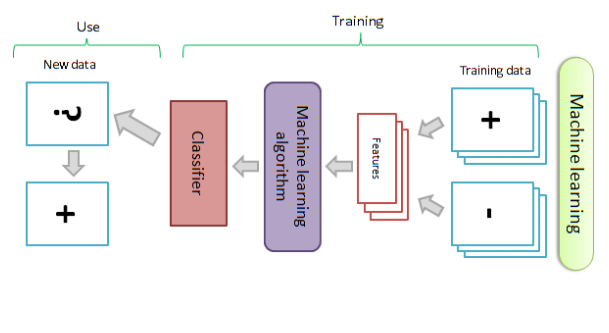
Durch den Einsatz automatischer Lernmethoden, insbesondere im Bereich des maschinellen Lernens (Machine Learning, ML) und der natürlichen Sprachverarbeitung (Natural Language Processing, NLP), hat sich die Effizienz und Genauigkeit der Sentiment-Analyse wesentlich verbessert. Dieses Unterkapitel beleuchtet die fortgeschrittenen Techniken und Algorithmen, die in den automatischen Lernmethoden der Sentiment-Analyse zur Anwendung kommen, untermauert durch aktuelle Literatur und Forschungsarbeit.
Grundlagen der automatischen Sentiment-Analyse
Die Sentiment-Analyse mittels automatischer Lernmethoden setzt auf Algorithmen, die aus großen Mengen an Textdaten lernen, um die Polarität (positiv, neutral, negativ) oder emotionale Färbung von Wörtern und Phrasen zu erkennen. Dazu bildet sie ein wichtiges Werkzeug für Unternehmen, um Einsichten aus Kundenfeedback, sozialen Medien und anderen textbasierten Kommunikationsmitteln zu gewinnen.
Maschinelles Lernen in der Sentiment-Analyse
Unterschiedliche Arten des maschinellen Lernens, wie überwachtes (supervised), unüberwachtes (unsupervised) und teilüberwachtes (semi-supervised) Lernen, sind grundlegend für moderne Sentiment-Analyse-Systeme. Überwachtes Lernen erfordert eine große Menge annotierter Trainingsdaten, wobei das Modell lernt, Sentiments basierend auf vordefinierten Kategorien zu klassifizieren. Im Gegensatz dazu versucht das unüberwachte Lernen, Muster in den Daten ohne vorherige Beschriftung zu identifizieren. Teilüberwachtes Lernen kombiniert beide Ansätze, um von einer kleinen Menge annotierter Daten und einer großen Menge nicht annotierter Daten zu profitieren.
Textanalyse und NLP-Techniken
Die Verarbeitung natürlicher Sprache und Textanalyse sind zentrale Bestandteile der Sentiment-Analyse. Komplexe NLP-Techniken wie Tokenisierung, Stemming, Lemmatisierung und Part-of-Speech-Tagging werden eingesetzt, um Texte in eine Form zu bringen, die von maschinellen Lernmodellen verarbeitet werden kann. Weiterhin spielen die Erkennung von Entitäten, Themenmodellierung und Syntaxanalyse eine entscheidende Rolle.
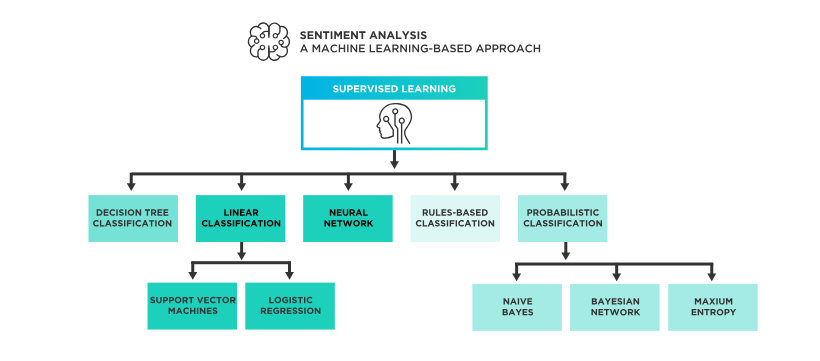
Algorithmen und Modelle der Sentiment Classifications
In der Sentiment-Analyse kommen diverse Algorithmen und Modelle zum Einsatz, die sich in ihrer Methodik und Komplexität unterscheiden. Jeder dieser Ansätze hat spezifische Stärken und eignet sich für verschiedene Aspekte der Textanalyse.
Entscheidungsbaum-Klassifikatoren (Decision Tree Classifier) sind eine Form von überwachtem Lernen, die Modellierung von Entscheidungsregeln ermöglichen. Sie arbeiten durch das Aufstellen einer Reihe von Fragen, basierend auf denen ein Text als positiv, negativ oder neutral klassifiziert wird.
Lineare Klassifikatoren hingegen, zu denen Logistic Regression (LR) und Support Vector Machines (SVM) gehören, verwenden mathematische Funktionen, um Datenpunkte in einem hochdimensionalen Raum zu trennen. LR schätzt die Wahrscheinlichkeit, dass eine Instanz zu einer Klasse gehört, während SVMs eine Grenze zwischen Klassen ziehen, die so weit wie möglich von den nächsten Datenpunkten jeder Klasse entfernt ist.
Neuronale Netzwerke sind leistungsfähige Modelle des Deep Learning, die besonders gut darin sind, komplexe Muster in großen Datensätzen zu erkennen:
- Recurrent Neural Networks (RNNs) können die Reihenfolge und Sequenz in den Daten berücksichtigen, was für die Analyse von Sätzen und längeren Texten entscheidend ist.
- Convolutional Neural Networks (CNNs) sind vorrangig aus dem Bereich der Bildverarbeitung bekannt, aber auch im NLP für die Erkennung lokaler und positioneller Muster im Text nützlich.
- Long Short-Term Memory networks (LSTMs) und Bi-directional LSTMs (Bi-LSTMs) sind spezielle Formen von RNNs, die besser mit dem Problem des langfristigen Gedächtnisses (long-term dependencies) umgehen können.
- Transformer Networks, wie BERT oder GPT, verwenden Attention-Mechanismen, um die Beziehung zwischen allen Wörtern in einem Text zu berücksichtigen und ermöglichen es, den Kontext auf eine Weise zu erfassen, die weit über die Fähigkeiten einfacher RNNs oder CNNs hinausgeht.
Regelbasierte Klassifikatoren (Rule Based Classifier) nutzen festgelegte linguistische Regeln, um die Stimmung auf Basis von Wortkombinationen und Satzstrukturen zu identifizieren.
Probabilistische Klassifikatoren beziehen Wahrscheinlichkeitsmodelle mit ein, wie:
- Multinomiale Naive Bayes (NB), die auf der Annahme basieren, dass die Merkmale (Wörter) in den Daten unabhängig voneinander sind, was eine schnelle Klassifizierung ermöglicht.
- Maximum Entropy-Modelle, die versuchen, die Wahrscheinlichkeitsverteilung zu finden, die am besten zu den Trainingsdaten passt, ohne weitere Annahmen zu treffen.
- Bayesian Networks, die Wahrscheinlichkeiten auf Basis von Abhängigkeiten zwischen Variablen modellieren.
Schließlich gibt es noch den K-Nearest-Neighbor (K-NN), einen algorithmischen Ansatz, der Klassifizierungen auf der Basis der am meisten ähnlichen Trainingsbeispiele vornimmt.
Diese Algorithmen bilden das Rückgrat moderner Sentiment-Analyse-Systeme und werden je nach Anforderung und Beschaffenheit der Daten ausgewählt.
Beispiele
Um zu verstehen, wie verschiedene maschinelle Lernansätze – speziell Naive Bayes, logistische Regression, Support Vector Machines (SVM), Deep Learning und kontextuelle Modelle – die vier genannten Beispiele der Sentiment-Analyse (normales, ironisches, zynisches und sarkastisches Kundenfeedback) behandeln würden, müssen wir ihre Funktionsweisen und ihre Fähigkeiten im Umgang mit komplexen sprachlichen Merkmalen betrachten.
Naive Bayes
Naive Bayes ist ein einfaches Wahrscheinlichkeitsmodell, das auf dem Bayesschen Theorem basiert und die Unabhängigkeit zwischen den Merkmalen annimmt. Es ist effektiv für direkte sentimentale Ausdrücke.
- Normales Feedback: Würde effektiv als positiv klassifiziert, da positive Wörter wie „sehr zufrieden“ und „hervorragend“ erkannt werden.
- Ironisches/Zynisches/Sarkastisches Feedback: Könnte Schwierigkeiten haben, die wahre Bedeutung zu erkennen, da Naive Bayes nicht die Fähigkeit hat, Kontext und sprachliche Nuancen zu berücksichtigen.
Logistische Regression
Logistische Regression ist ein statistisches Modell, das Wahrscheinlichkeiten verwendet, um Klassenzugehörigkeiten vorherzusagen. Es kann etwas besser als Naive Bayes mit Kontext umgehen, aber bleibt begrenzt in der Erkennung von Ironie und Sarkasmus.
- Normales Feedback: Würde wahrscheinlich korrekt als positiv klassifiziert.
- Ironisches/Zynisches/Sarkastisches Feedback: Während es besser als Naive Bayes abschneiden könnte, ist es unwahrscheinlich, dass es ohne spezifisches Training oder zusätzliche Feature-Engineering-Techniken Ironie und Sarkasmus effektiv erkennt.
Support Vector Machines (SVM)
SVM ist ein leistungsstarker Klassifikator, der eine Entscheidungsgrenze zwischen verschiedenen Klassen findet. Es kann komplexere Muster erkennen als Naive Bayes oder logistische Regression.
- Normales Feedback: SVM würde dies wahrscheinlich korrekt als positiv klassifizieren.
- Ironisches/Zynisches/Sarkastisches Feedback: SVM könnte besser abschneiden als einfacher Naive Bayes oder logistische Regression, insbesondere wenn es mit Features trainiert wird, die Kontext und sprachliche Nuancen einfangen.
Deep Learning
Deep Learning Modelle, insbesondere solche, die neuronale Netzwerke verwenden, sind fähig, komplexere Muster und Beziehungen in Daten zu erkennen.
- Normales Feedback: Wird mit hoher Wahrscheinlichkeit korrekt klassifiziert.
- Ironisches/Zynisches/Sarkastisches Feedback: Deep Learning Modelle sind wahrscheinlich effektiver in der Erkennung von Ironie und Sarkasmus, besonders wenn sie mit einem großen und diversifizierten Trainingsdatensatz trainiert werden, der diese sprachlichen Nuancen einschließt.
Zusammenfassung
Während traditionelle maschinelle Lernmodelle wie Naive Bayes, logistische Regression und SVM gewisse Einschränkungen bei der Erkennung von Ironie, Sarkasmus und Zynismus aufweisen, bieten fortgeschrittene Deep Learning und kontextuelle Modelle eine deutlich verbesserte Fähigkeit, diese komplexen sprachlichen Ausdrücke zu interpretieren. Die Leistungsfähigkeit dieser Modelle hängt jedoch stark von der Qualität und Vielfalt des Trainingsdatensatzes sowie vom Grad des Feature-Engineerings ab. Kontextuelle Modelle, die auf umfangreichen Datensätzen trainiert wurden, sind in der Lage, subtile Nuancen und Kontext in der Sprache zu erfassen, was sie zu den fortschrittlichsten Tools in der Sentiment-Analyse macht.
Herausforderungen und aktuelle Forschung
Trotz großer Fortschritte gibt es in der automatisierten Sentiment-Analyse weiterhin Herausforderungen wie Ironie, Slang, Idiome oder Kontextabhängigkeit. Aktuelle Forschungen konzentrieren sich unter anderem auf kontextuelle Modelle, wie sie beispielsweise in BERT (Bidirectional Encoder Representations from Transformers) und GPT (Generative Pretrained Transformer) zu finden sind, die eine noch tiefere semantische Verständnisfähigkeit ermöglichen.
Fazit
Computational linguistics, machine learning, und NLP weiterhin die Grenzen der Sentiment-Analyse durch fortgeschrittene Modelle und Techniken erweitern. Durch den gezielten Einsatz dieser Methoden können Unternehmen und Wissenschaftler tiefere Einblicke in die Meinungen und Gefühle von Menschen gewinnen, was in einer breiten Palette von Anwendungen, von der Marktanalyse bis hin zur politischen Meinungsforschung, von hoher Bedeutung ist.
Hybride Modelle in der Sentiment-Analyse
In der Sentiment-Analyse haben sich verschiedene Methoden etabliert, die grundsätzlich in zwei Hauptgruppen (die gerade beschrieben wurden) eingeteilt werden können: maschinenlernbasierte (ML) Ansätze und regelbasierte bzw. lexikonbasierte (LB) Ansätze. Maschinenlernmethoden nutzen klassifizierende Algorithmen, um Stimmungen aus Texten zu erkennen, während lexikonbasierte Ansätze Listen von wertgeladenen Wörtern verwenden und anhand deren Präsenz im Text eine Stimmung identifizieren.
Hybride Modelle kombinieren sowohl ML- als auch LB-Ansätze, um von den Stärken beider Methoden zu profitieren und ihre Nachteile auszugleichen. Sie sind Gegenstand vieler Studien und technischer Berichte, einschließlich solcher, die von Forschungseinrichtungen wie Hewlett-Packard oder in Journalen wie dem Journal of Big Data und anderen wissenschaftlichen Publikationen veröffentlicht wurden.
Die Vorteile hybrider Modelle liegen auf der Hand: Sie können die fehlende Kontextsensitivität von LB-Methoden durch das Erlernen von Mustern mittels ML überwinden. Gleichzeitig können sie die Schwierigkeit von ML-Methoden, Sarkasmus, Ironie oder kontextuelle Nuancen zu erfassen, durch die Einbeziehung von lexikonbasierten Techniken angehen. Viele Studien, wie die von der IEEE oder MDPI veröffentlichten, zeigen, dass hybride Modelle die Genauigkeit der Sentiment-Analyse signifikant verbessern können.
Ein weiterer Vorteil hybrider Modelle, der in der Forschung hervorgehoben wird, ist die Möglichkeit zur Individualisierung. Indem man Muster aus ML mit spezifischen, domänengebundenen LB-Ansätzen kombiniert, kann man Modelle schaffen, die auf den spezifischen Kontext und das spezifische Vokabular eines Themas oder einer Branche abgestimmt sind.
Ein Beispiel für die Anwendung hybrider Modelle ist die Analyse von Kundenfeedback in Echtzeit, um einen umfassenden Blick auf Kundenmeinungen zu erhalten, wie es Plattformen wie Sprinklr ermöglichen. Durch die Kombination von quantitativen Daten aus ML-Analysen mit qualitativen Erkenntnissen aus LB-Verfahren können Unternehmen nuancierter auf Kundenstimmungen reagieren.
Die Herausforderung bei der Entwicklung und Implementierung hybrider Modelle liegt darin, die richtige Balance zwischen ML und LB Methoden zu finden, wie auch die Berichte von Hindawi oder von de Gruyter diskutieren. Es ist entscheidend, den Gesamtkontext, die spezifischen Anforderungen und die verfügbaren Ressourcen zu berücksichtigen, um eine maßgeschneiderte, effektive Hybridlösung zu schaffen.
Abschließend, während reine ML- oder LB-Modelle ihre eigenen Vorteile aufweisen, bieten hybride Modelle eine vielversprechende Alternative, um die vielfältigen und komplexen Aspekte der menschlichen Sprache in der Sentiment-Analyse zu berücksichtigen. Durch kontinuierliche Forschung und Entwicklung sowie den Einsatz fortgeschrittener Algorithmen und leistungsfähigerer Computer wird erwartet, dass sich die Leistungsfähigkeit hybrider Modelle in der Sentiment-Analyse weiter verbessern wird.
Andere Ansätze
Transfer Learning und Aspect-Based Ansätze sind innovative Methoden in der Sentiment-Analyse, die jeweils einzigartige Vorteile bieten.
Der Ansatz des Transferlernens (Transfer Learning) basiert auf dem Konzept der Übertragung von Wissen, das ein Modell durch das Training auf einer bestimmten Aufgabe erworben hat, auf eine neue, jedoch verwandte Aufgabe. Diese Methodik ist in der Sentiment-Analyse besonders nützlich, da sie es ermöglicht, fortschrittliche Modelle, die auf umfangreichen und generischen Datensätzen trainiert wurden, auf spezifische Sentiment-Analyse-Aufgaben anzuwenden. Modelle wie BERT oder GPT, die umfassende Sprachrepräsentationen während des Trainingsprozesses erlernen, können ihre Fähigkeiten nutzen, um auch bei einer begrenzten Verfügbarkeit von spezifischen Trainingsdaten effektiv zu sein. Diese Modelle, oft auch als kontextuelle Modelle bezeichnet, heben sich durch ihre Fähigkeit hervor, den gesamten Kontext eines Wortes innerhalb eines Satzes zu berücksichtigen. Sie gehen damit über die Analyse unmittelbar benachbarter Wörter hinaus und nutzen Attention- oder Self-Attention-Mechanismen, um die Beziehungen zwischen Wörtern über längere Distanzen im Text hinweg zu erfassen. Solche kontextuellen Modelle sind in der Lage, subtile Nuancen und komplexe sprachliche Phänomene wie Ironie und Sarkasmus zu erkennen, was sie für die Sentiment-Analyse besonders wertvoll macht. Die Diskussion und das Verständnis kontextueller Modelle tragen maßgeblich dazu bei, die Algorithmen und Modelle der Sentiment-Klassifikation in der aktuellen Forschung und Anwendung zu erweitern und zu aktualisieren.
Aspect-Based Sentiment Analysis (ABSA): ABSA konzentriert sich auf die Identifizierung von Meinungen, die sich auf spezifische Aspekte oder Merkmale eines Produkts oder Dienstes beziehen. Anstelle einer allgemeinen Sentiment-Bewertung analysiert ABSA, wie Kunden einzelne Aspekte wie die Qualität des Produkts, die Effizienz des Services oder die Benutzerfreundlichkeit einer Software fühlen. Dies ermöglicht Unternehmen, gezielte Einblicke zu gewinnen und spezifische Bereiche für Verbesserungen zu identifizieren. Beispielsweise könnte ein ABSA-Modell in Hotelbewertungen die Sentiments bezüglich Sauberkeit, Komfort der Betten oder Freundlichkeit des Personals separat analysieren und somit detaillierte Informationen für das Management bereitstellen.
Beide Ansätze erweitern die Fähigkeiten der traditionellen Sentiment-Analyse und ermöglichen eine feinere und spezifischere Analyse von Textdaten, die für präzisere Geschäftsentscheidungen unerlässlich sind.
Technologien und Tools für die Sentiment-Analyse
NLP-Bibliotheken und Frameworks für die Sentiment-Analyse
Die Verarbeitung Natürlicher Sprache (Natural Language Processing, NLP) ist ein zentraler Bestandteil der Sentiment-Analyse und spielt eine entscheidende Rolle bei der Interpretation und Bewertung von Textdaten. Verschiedene NLP-Bibliotheken und Frameworks bieten Entwicklern und Forschern leistungsstarke Werkzeuge, um Stimmungen (Sentiments) in großen Mengen von Textdaten zu erkennen und zu analysieren. In diesem Unterkapitel werden wir einige der beliebtesten und effektivsten NLP-Bibliotheken und Frameworks diskutieren, die für die Sentiment-Analyse verwendet werden können.
Open-Source NLP-Bibliotheken
Die Open-Source-Gemeinschaft hat einige hochwertige Bibliotheken bereitgestellt, die für die Sentiment-Analyse eingesetzt werden können. Diese Bibliotheken sind meist kostenlos, verfügen über eine aktive Entwicklergemeinde und werden ständig weiterentwickelt.
- NLTK (Natural Language Toolkit): NLTK ist eine der führenden Plattformen für die Verarbeitung von natürlicher Sprache in Python. Sie bietet einfache Schnittstellen zu über 50 Korpora und lexikalischen Ressourcen wie WordNet sowie eine Suite von Textverarbeitungs-Bibliotheken für Klassifikation, Tokenisierung, Stemming, Tagging, Parsing und semantische Argumentation.
- spaCy: spaCy ist bekannt für seine Geschwindigkeit und Effizienz und bietet vortrainierte statistische Modelle und Wortvektoren. Es wird häufig bei produktionsreifen Anwendungen eingesetzt und verfügt über eine reichhaltige Entwicklererfahrung.
- TextBlob: TextBlob ist eine weitere einfache Bibliothek für die Verarbeitung von Textdaten in Python. Es ist besonders benutzerfreundlich, was es zu einer guten Wahl für den Einstieg in NLP und Sentiment-Analyse macht.
- Stanford CoreNLP: Diese Java-basierte Bibliothek bietet eine breite Palette von NLP-Tools und ist für ihre Genauigkeit bekannt. Sie kann auch aus anderen Programmiersprachen wie Python genutzt werden.
- VADER (Valence Aware Dictionary and sEntiment Reasoner): VADER ist eine lexikon- und regelbasierte Sentiment-Analyse-Bibliothek, die speziell für soziale Medien und Texte mit Slangs, Emojis und Akronymen entwickelt wurde.
| Bibliothek/Framework | Unterstützte Methoden der Sentiment-Analyse |
|---|---|
| NLTK | Lexikonbasiert (z.B. mit Sentiment-Lexika), Unterstützung für diverse ML-Algorithmen wie Naive Bayes, Entscheidungsbäume, bietet auch Tools für regelbasierte Analyse |
| spaCy | Integration mit ML-Frameworks (z.B. scikit-learn), bietet Entity Recognition und Dependency Parsing, keine spezifischen Sentiment-Analyse-Tools out-of-the-box |
| TextBlob | Einfache lexikonbasierte Sentiment-Analyse, Integration mit Naive Bayes und Decision Trees für maßgeschneiderte Sentiment-Analyse |
| Stanford CoreNLP | Umfangreiche NLP-Tools, inklusive regelbasierter Ansätze, ML-basierte Methoden (z.B. Support Vector Machines) über Integration mit anderen Bibliotheken |
| VADER | Spezialisiert auf lexikonbasierte Sentiment-Analyse, optimiert für soziale Medien und Texte mit Slang, verwendet eine Kombination aus lexikalischen Heuristiken und Regeln |
Kommerzielle NLP-Produkte und API-basierte Lösungen
Neben den Open-Source-Bibliotheken gibt es auch kommerzielle Produkte, die meist cloud-basierte NLP-Dienste bereitstellen. Diese sind oft benutzerfreundlich und bieten leistungsstarke APIs für verschiedene NLP-Aufgaben, einschließlich Sentiment-Analyse.
- Google Cloud Natural Language API: Dieser Dienst von Google bietet leistungsstarke maschinelle Lernfunktionen, um die Struktur und Bedeutung von Text zu verstehen. Er unterstützt mehrere Sprachen und kann Emotionen und Meinungen in Texten identifizieren.
- Amazon Comprehend: Amazons Comprehend-Dienst erkundet und klassifiziert Textdaten, um Kunden dabei zu helfen, besser zu verstehen, was ihre Daten vermitteln. Es verwendet maschinelles Lernen, um Muster und Themen in unstrukturierten Daten zu identifizieren.
- IBM Watson Natural Language Understanding: IBMs Service kann Emotionen und Stimmungen in Textinhalten erkennen und liefert tiefe Einblicke in die öffentliche Meinung und das Kundensentiment.
- Microsoft Azure AI Language Service: Microsoft Azure AI Language Service bietet einen Sentimentanalyse-Dienst an, der auf der Azure-Cloud-Plattform basiert. Dieser Dienst ist Teil eines größeren Angebots an kognitiven Diensten, die sprachliche, visuelle und Entscheidungsfunktionen umfassen und in bestehende Applikationen integriert werden können.
- MonkeyLearn: MonkeyLearn bietet benutzerdefinierte Sentiment-Analyse-Modelle, die für spezifische Anforderungen und Branchen trainiert werden können, und ist einfach in vorhandene Infrastrukturen zu integrieren.
| API-Lösung | Unterstützte Methoden der Sentiment-Analyse |
|---|---|
| Google Cloud Natural Language | Maschinelles Lernen für Strukturanalyse, mehrsprachige Sentiment-Erkennung |
| Amazon Comprehend | ML-basierte Mustererkennung, Klassifizierung von Textdaten, Erkennung von Themen |
| IBM Watson Natural Language | Erkennung von Emotionen und Stimmungen, tiefgehende Analyse öffentlicher Meinungen |
| Microsoft Azure AI Language | ML-basierte Sentimentanalyse, Teil eines umfangreicheren Angebots an kognitiven Diensten |
| MonkeyLearn | Benutzerdefinierte ML-Modelle für spezifische Branchen, einfache Integration |
Python-Bibliotheken und Frameworks
Python gilt als die führende Sprache im Bereich NLP aufgrund seiner Einfachheit und der großen Zahl an Bibliotheken. Hier sind einige Python-spezifische Bibliotheken und Frameworks:
- scikit-learn: Ein breit einsetzbares Machine-Learning-Toolkit, mit dem auch Feature-Engineering und -Extraktion für Textklassifikation vorgenommen werden können.
- Gensim: Speziell für „Topic Modeling“ und „Document Similarity“ entwickelt, werden in Gensim auch Funktionen für Sentiment-Analyse unterstützt.
- Keras/TensorFlow/PyTorch: Diese fortgeschrittenen Machine-Learning- und Deep-Learning-Bibliotheken werden für komplexere Sentiment-Analyse-Modelle benötigt, die auf neuronalen Netzwerken basieren.
| Python-Bibliothek/Framework | Unterstützte Methoden der Sentiment-Analyse |
|---|---|
| scikit-learn | Unterstützt ML-Algorithmen für Textklassifikation, Feature-Engineering und -Extraktion |
| Gensim | Topic Modeling, Document Similarity, unterstützt auch Sentiment-Analyse Funktionen |
| Keras/TensorFlow/PyTorch | Fortgeschrittene Deep Learning-Frameworks, geeignet für komplexe neuronale Netzwerkmodelle in der Sentiment-Analyse |
Akademische Recherche und Diskussionen
Wissenschaftliche Publikationen und Foren wie Quora, ScienceDirect, IEEE Xplore und Springer bieten tiefergehende Einblicke in die Theorien hinter Sentiment-Analyse, aktuelle Forschungen und Entwicklungen in diesem Bereich sowie Bewertungen verschiedener Ansätze und Tools.
Die Sentiment-Analyse ist ein lebendiger und sich schnell entwickelnder Bereich, getrieben durch den Wunsch nach besseren Einblicken in die Meinungen der Menschen. Die breite Palette an verfügbaren Tools – von Fertigprodukten bis hin zu anpassbaren Lösungen – bietet Unternehmen und Forschern eine Vielzahl von Möglichkeiten, um die Stimmungen und Meinungen in großen Textmengen zu analysieren. Unabhängig von der gewählten Methode oder Technologie ist es entscheidend, das Tool zu finden, das am besten zu den spezifischen Anforderungen und Daten passt.
Sentiment-Analyse-Software
Die Sentiment-Analyse ist ein Bereich des Natural Language Processing (NLP), der sich mit der Identifizierung und Kategorisierung von Meinungen in Text umfasst, um zu verstehen, ob die Stimmung einer Aussage positiv, neutral oder negativ ist. Dank fortschrittlicher Algorithmen und des zunehmenden Bedarfs an Datenanalytik in den sozialen Medien, Kundenfeedback und anderen Arten der digitalen Kommunikation hat sich ein vielfältiges Angebot an Sentiment-Analyse-Tools entwickelt. Diese Tools nutzen sowohl maschinelles Lernen als auch linguistische Ansätze, um den Ton und die subjektiven Informationen in großen Mengen von Text effizient zu analysieren.
Einige der bekanntesten Sentiment-Analyse-Softwares und deren Eigenschaften werden in der folgenden Ausführung präsentiert.
Beispielhafte Tools und ihre Funktionen
Machine Learning-basierte Analyseplattformen
MonkeyLearn ist eine bekannte Plattform für Textanalyse, die umfangreiche Sentiment-Analyse-Tools bietet. Es ermöglicht Benutzern, mithilfe von maschinellem Lernen maßgeschneiderte Modelle zu trainieren, die auf die spezifischen Anforderungen und Datenstrukturen abgestimmt sind. Die Stärke von MonkeyLearn liegt in seiner benutzerfreundlichen Schnittstelle und der Fähigkeit, schnell und effektiv Stimmungen aus Kundenbewertungen, Umfragen und anderen Textquellen zu extrahieren.
Social Media Sentiment-Analyse-Tools
Brand24 bietet eine Echtzeitanalyse von Online-Gesprächen, einschließlich Überwachung der Sozialen Medien, was es für Marken einfach macht, nicht nur Erwähnungen ihres Namens zu verfolgen, sondern auch die Stimmung dieser Erwähnungen zu analysieren. Es liefert Insights zu Kundenstimmungen und hilft bei der Krisenvermeidung, indem negative Kommentare schnell erkannt werden.
Customer Review Analysis
SOCi Reviews ist ein Produkt der SOCi-Plattform, das speziell darauf ausgerichtet ist, Customer Reviews zu sammeln und zu analysieren. Mit Fokus auf lokale Unternehmen und deren Ratings ermöglicht SOCi Reviews eine granulare Analyse von Kundenfeedback, was für Unternehmen, die lokale SEO priorisieren, besonders wertvoll ist.
Vergleiche von Sentiment-Analyse-Tools
Auf Investiga.ai oder Gartner finden sich umfangreiche Analysen und Vergleiche verschiedener Sentiment-Analyse-Tools. Diese bieten einen guten Überblick über die Stärken und Schwächen verschiedener Ansätze und Produkte, indem sie Faktoren wie Genauigkeit, Umfang der Sprachenunterstützung, Integrationsmöglichkeiten und Anpassungsfähigkeit berücksichtigen.
Cloud-basierte Sentiment-Analyse-Dienste
Die oben beschriebenen API-Dienste sind Teil eines größeren Angebots an kognitiven Diensten, die sprachliche, visuelle und Entscheidungsfunktionen umfassen und in bestehende Applikationen integriert werden können. Daneben existieren auch noch firmenspezifische Analyse-Dienstleistungen. Hitachi’s Sentiment Analysis ist ein Beispiel dafür, wie spezialisierte IT-Dienstleistungsunternehmen ihre eigenen proprietären Sentiment-Analyse-Tools entwickeln. Diese sind oft auf spezifische Branchenanforderungen zugeschnitten und bieten individuelle Lösungen für große Unternehmen an.
Schlüsselaspekte der Sentiment-Analyse-Software
Wichtig bei der Wahl einer Sentiment-Analyse-Software sind unter anderem folgende Elemente:
- Analysegenauigkeit: Die Präzision, mit der das Tool die Stimmung von Text erfassen kann.
- Echtzeitverarbeitung: Für viele Anwendungen ist es entscheidend, dass die Sentiment-Analyse in Echtzeit erfolgt.
- Sprachunterstützung: Produkte, die mehrere Sprachen unterstützen, bieten einen breiteren Anwendungsbereich.
- Anpassungsfähigkeit: Die Fähigkeit der Software, auf spezifische Anforderungen eines Unternehmens oder Sektors zugeschnitten zu werden.
- Integrationen: Wie gut sich ein Tool in bestehende Systeme und Prozesse einbinden lässt.
- Preismodelle: Die Kosten können je nach Funktionsumfang, Nutzungsintensität und benötigter Skalierung stark variieren.
Fazit
Es gibt eine breite Palette an Sentiment-Analyse-Tools auf dem Markt, die sowohl für kleine Unternehmen als auch für große Konzerne passende Lösungen bieten. Die Wahl der richtigen Software hängt von den individuellen Bedürfnissen des Nutzers ab und sollte basierend auf Faktoren wie Genauigkeit, Sprachunterstützung, Anpassbarkeit und Kosten getroffen werden. Wissenschaftliche Forschung und Produktvergleiche von renommierten Unternehmen wie Gartner können bei dieser Entscheidung eine wichtige Hilfestellung bieten.
Cloud-Dienste und APIs im Detail
In den letzten Jahren haben sich die oben beschriebenen Cloud-Dienste und APIs als Schlüsseltechnologien für die Sentiment-Analyse etabliert, da sie eine einfache Integration und eine skalierbare Analyse in Echtzeit ermöglichen. In diesem Unterkapitel werden wir uns verschiedene Cloud-Plattformen und APIs ansehen, die für die Sentiment-Analyse genutzt werden können.
Google Cloud Natural Language API
Die Google Cloud Natural Language API ist eines der führenden Werkzeuge zur Sentiment-Analyse. Sie nutzt maschinelles Lernen, um Text zu analysieren und wertvolle Metadaten hinsichtlich Stimmung, Entitätenerkennung und Syntax zu extrahieren. Mit dieser API können Entwickler einfache Anfragen senden und die Analysen auf einer Skala von -1 (sehr negativ) bis +1 (sehr positiv) erhalten. Dies ermöglicht Unternehmen, die Stimmung ihrer Kunden schnell zu erfassen und entsprechend zu handeln. Die Kosten für die Nutzung der Google Cloud Natural Language API können je nach Volumen der Anfragen variieren, wodurch Unternehmen ihre Ausgaben je nach Bedarf skalieren können.
AWS Comprehend
Ähnlich wie Google bietet auch Amazon Web Services (AWS) mit AWS Comprehend ein mächtiges Tool für die Sentiment-Analyse. Comprehend verwendet ebenfalls maschinelles Lernen, um Muster und Zusammenhänge in Texten zu verstehen. Es erlaubt nicht nur die Erkennung von Sentiments, sondern auch die Identifizierung von Themen und Kategorisierung von Textdaten. Durch die nahtlose Integration mit anderen AWS-Diensten eignet sich Comprehend für Unternehmenslösungen, die eine umfassende Datenanalyseplattform benötigen.
IBM Watson Natural Language Understanding
IBM Watson Natural Language Understanding liefert tiefe Einblicke in Textinhalte, darunter Emotionen, Konzepte, Entitäten und vieles mehr. Die Plattform zeichnet sich durch ihre Fähigkeit aus, branchenspezifische Modelle zu bilden und wird damit besonders interessant für Unternehmen, die in besonderen Bereichen tätig sind. Darüber hinaus bietet IBM eine robuste Sicherheit und Bearbeitungsmöglichkeiten, die es Regierungsbehörden und großen Unternehmen ermöglichen, die Plattform anzupassen.
Microsoft Azure Text Analytics API
Die Azure Text Analytics API von Microsoft ist eine weitere wichtige Lösung, die Sentiment-Analyse, Entitätenerkennung, Schlüsselphrasenextraktion und Spracherkennung anbietet. Diese API kann in zahlreichen Sprachen genutzt werden und ermöglicht es somit Unternehmen, global mit ihren Kunden zu kommunizieren und auf deren Bedürfnisse einzugehen. Microsofts Engagement für künstliche Intelligenz und maschinelles Lernen garantiert die ständige Verbesserung der Algorithmen hinter ihrem Service.
Drittanbieter-Apis und Plattformen
Neben den großen Cloud-Anbietern gibt es eine Vielzahl von Drittanbieter-Apis, die auf den Markt drängen und ihre eigene Expertise im Bereich der Sentiment-Analyse anbieten. Plattformen wie MonkeyLearn, Yotpo’s Smart Sentiment Analysis und HubSpot präsentieren maßgeschneiderte Lösungen, die speziell auf Marketing, Kundendienst und Marktforschung ausgerichtet sind. Plattformen wie RapidAPI ermöglichen den Zugang zu einer breiten Palette von Sentiment-Analyse APIs und erleichtern die Integration verschiedener Dienste.
Fazit
Cloud-Dienste und APIs spielen eine zentrale Rolle in der modernen Sentiment-Analyse. Sie bieten eine schnelle, effiziente und flexible Möglichkeit, große Mengen an Textdaten zu analysieren und wertvolle Einblicke zu gewinnen. Von großen Plattformen wie Google, Amazon, IBM und Microsoft bis hin zu spezialisierten Anbietern und RapidAPI-Marktplätzen, die Auswahl an Tools und Technologien ist vielfältig und wächst stetig. Die kontinuierliche Forschung und Entwicklung in diesem Bereich lässt auch in Zukunft weitere Innovationen und Verbesserungen erwarten.
Herausforderungen und Lösungsansätze
Verarbeitung von Slang und Ironie
Die Verarbeitung natürlicher Sprache (Natural Language Processing – NLP) hat durch ihre breite Anwendung in Chatbots, Sprachassistenten, und Sentiment-Analyse-Tools zunehmend an Bedeutung gewonnen. Ein spezifisches Problem in diesem Bereich stellt die effektive Verarbeitung von Slang und Ironie dar. Diese Aspekte der Sprache sind besonders anspruchsvoll, da sie oft kontextabhängig und kulturspezifisch sind.
Herausforderungen bei der Verarbeitung von Slang
Slang als Teil der alltäglichen Sprache zeichnet sich durch ständige Änderungen und eine Vielfalt an Formen aus. Da Slang Ausdrücke informell und oft regional begrenzt sind, können sie von NLP-Systemen leicht missverstanden werden. Sentiment-Analyse-Tools, welche die Stimmung hinter Texten erkennen sollen, können durch Slang-Begriffe leicht in die Irre geführt werden. Laut einer Übersicht der besten Sentiment-Analyse-Tools von Talkwalker können Anpassungen in diesen Systemen erforderlich sein, um regionale Slangs korrekt zu erfassen und ihre Bedeutung im Kontext richtig zu interpretieren.
Weitere Herausforderungen bei der Verarbeitung von Slang betreffen die Identifikation und das Lernen neuer Slang-Ausdrücke. Internetlinguistik ist hierbei ein hilfreiches Forschungsfeld, weil es sich mit den Besonderheiten der Sprache im digitalen Raum beschäftigt, wo Slang sich rasch entwickelt und verbreitet.
Herausforderungen bei der Verarbeitung von Ironie
Ironie ist eine rhetorische Figur, die das Gegenteil dessen vermittelt, was tatsächlich gesagt wird. Eine Masterarbeit aus dem Bereich des NLP verweist auf die besondere Schwierigkeit, Ironie zu erkennen, da sie meistens von Kontext, Tonfall und Vorwissen abhängt. Die computergestützte Erkennung von Ironie ist insbesondere deshalb komplex, weil maschinenlesbare Hinweise wie etwa der Tonfall in textbasierten Daten nicht vorhanden sind.
Das Erkennen von Ironie kann ausgiebige semantische Analysen und oft auch Wissen über die zugrundeliegenden emotionalen Zustände und Absichten der Nutzer erfordern. Forschungsarbeiten, wie im Journal ‚Informatik Spektrum‚ veröffentlicht, zeigen, dass maschinelles Lernen und Deep Learning Techniken vielversprechende Ansätze bieten, um solche komplexen sprachlichen Phänomene zu erfassen.
Lösungsansätze und Fortschritte
Um die Herausforderungen von Slang und Ironie zu überwinden, werden verschiedene Lösungsstrategien verfolgt. Einerseits werden fortlaufend spezialisierte Korpora und Datensätze erstellt, die Slang und ironische Äußerungen enthalten, um bessere Trainingsdaten für NLP-Systeme bereitzustellen. Zum Beispiel erforscht die Arbeit von Roman Klinger die unterschiedlichen emotionalen Ausdrucksformen in Texten, einschließlich Ironie.
Andererseits werden immer ausgefeiltere Algorithmen für Deep Learning und semantische Analyse entwickelt und angewandt, um den Kontext und die versteckten Bedeutungen hinter Worten besser zu verstehen. Die Fortschritte in der Sentimentanalyse zeigen, dass mit genügend Daten und kontextueller Information die Genauigkeit solcher Systeme verbessert werden kann (https://mindsquare.de/knowhow/sentimentanalyse/).
Gleichzeitig gewinnen Anwendungen, die Modelle wie BERT oder GPT (Generative Pretrained Transformer) verwenden, an Popularität, da sie in der Lage sind, komplizierte Sprachmerkmale in größeren Kontexten zu erkennen (Link). Diese Modelle verstehen zunehmend den Gebrauch von Sprache und können so helfen, die Nuancen von Slang und Ironie zu erfassen.
Zukunftsprognose für NLP-Technologie
Obwohl heutige NLP-Systeme beachtliche Erfolge bei der Verarbeitung von Sprache erzielen, bleibt die Integration und Verarbeitung von Slang und Ironie eine andauernde Herausforderung. Die Evolution von NLP steht in direktem Zusammenhang mit technologischen Fortschritten und der zunehmenden Verfügbarkeit von Big Data. Eine kontinuierliche Forschung ist notwendig, um künftige Algorithmen und Modelle zu entwickeln, die noch besser in der Lage sind, menschliche Sprache in all ihren Facetten zu verstehen und zu interpretieren.
Zusammenfassend lässt sich sagen, dass die Behandlung von Slang und Ironie im Bereich des NLP ein dynamisches Forschungsfeld darstellt, das sowohl interdisziplinäres Wissen als auch kreative technologische Innovationen erfordert. Die bestehenden Ansätze und laufenden Forschungen zeigen ein zukunftsorientiertes Bild, in dem NLP-Systeme immer menschenähnlicher in ihren Fähigkeiten werden, die Feinheiten und Komplexitäten der Sprache zu erfassen und zu verarbeiten.
Analyse von Multilingualität: Herausforderungen und Lösungsansätze
In der modernen globalisierten Welt ist die Fähigkeit, mit Multilingualität umzugehen, entscheidend für den Erfolg in vielen Bereichen – von der Technikentwicklung über das Bildungswesen bis hin zum Umweltschutz. Die Analyse von Multilingualität wirft zahlreiche Herausforderungen auf, die kreative und effektive Lösungsansätze erfordern.
Bedeutung von Multilingualität in Bezug auf Sentiment Analyse
Die Multilingualität spielt in der Sentiment-Analyse eine entscheidende Rolle, vor allem in unserer zunehmend globalisierten und digital vernetzten Welt. Die Fähigkeit, Sentiments in verschiedenen Sprachen zu analysieren, ist für viele Anwendungen von wesentlicher Bedeutung. Hier sind einige Schlüsselaspekte, die die Bedeutung der Multilingualität in der Sentiment-Analyse unterstreichen:
- Zugang zu einer breiten Datenbasis/Vielfältige Datenquellen: Sentiments werden in zahlreichen Sprachen auf Plattformen wie sozialen Medien, Blogs, Foren und Kundenbewertungen ausgedrückt. Unternehmen und Organisationen, die global agieren, benötigen Tools zur Sentiment-Analyse, die mit dieser sprachlichen Vielfalt umgehen können.
- kulturelle und linguistische Nuancen:
- Kontextverständnis: Unterschiedliche Sprachen tragen unterschiedliche kulturelle und kontextuelle Bedeutungen. Wörter und Ausdrücke in einer Sprache können in einer anderen Sprache keine direkten Entsprechungen haben, was die Analyse komplexer macht.
- Subtilitäten im Ausdruck: Ironie, Sarkasmus und andere Feinheiten können sich von einer Sprache zur anderen unterscheiden, was die Notwendigkeit einer tiefgehenden Kenntnis jeder spezifischen Sprache unterstreicht.
- Herausforderungen bei der Übersetzung:
- Verlust von Nuancen: Direkte Übersetzungen von Texten in eine einzige Sprache (meist Englisch) vor der Sentiment-Analyse können zu einem Verlust von Nuancen und Bedeutungen führen.
- Übersetzungsfehler: Automatische Übersetzungstools sind nicht immer genau, was zu falschen Interpretationen in der Sentiment-Analyse führen kann.
- Entwicklung multilingualer Modelle:
- Fortschritte in NLP: Die Entwicklungen im Bereich des Natural Language Processing (NLP), insbesondere mit kontextuellen Modellen wie BERT, haben multilinguale Modelle hervorgebracht, die in der Lage sind, Texte in mehreren Sprachen zu verarbeiten.
- Training und Ressourcen: Das Training effektiver multilingualer Modelle erfordert umfangreiche Datensätze in mehreren Sprachen und ist ressourcenintensiv.
Herausforderungen bei der Analyse von Multilingualität
Die Herausforderungen der Analyse von Multilingualität sind vielfältig. In technischen Systemen wie Softwareanwendungen oder Informationssystemen stellt die Vielfalt der Sprachen hohe Anforderungen an die Lokalisierung, Übersetzung und Anpassung an regionale Eigenheiten. Beispielsweise erfordert die Lokalisierung von Applikationen die Übersetzung und Anpassung von Inhalten, was auf Plattformen wie Mendix (Mendix Guide) umgesetzt wird.
Im wissenschaftlichen Bereich, insbesondere in der Sprachwissenschaft, wird die Analyse von Multilingualität als ein weites Feld betrachtet, das von der Struktur verschiedener Sprachen bis hin zu sozialen und kognitiven Aspekten reicht (siehe Universität Göttingen). Für Sprachtherapeuten und Logopäden bedeutet Multilingualität zusätzliche Herausforderungen in der Diagnostik sowie in der individuellen Therapieplanung (siehe Logomania).
Im Bereich des Umweltschutzes sind Dokumentationen zu „Besten verfügbaren Techniken“ wie die vom Umweltbundesamt veröffentlichte Studie zu PFOS Umweltbundesamt Publikationen auch mehrsprachig verfügbar, was die Kommunikation von Umweltschutzstandards über Sprachgrenzen hinweg erleichtert.
Lösungsansätze und Best Practices
Zur Bewältigung dieser Herausforderungen sind umfassende Lösungsansätze notwendig. Im Bildungsbereich müssen Pädagogen Strategien entwickeln, um Mehrsprachigkeit im Klassenzimmer zu unterstützen und zu fördern (Cedefop Studie, HRK Expertise).
Im Gesundheitswesen müssen Lösungen entwickelt werden, um Mehrsprachigkeit in der Patientenversorgung zu berücksichtigen, was neue Anforderungen an das Versorgungssystem stellt (siehe Kinderärztliche Praxis).
In der Sprachtechnologie und der Entwicklung künstlicher Intelligenz spielen mehrsprachige Datensätze und Algorithmen eine Schlüsselrolle, wie sie am Deutschen Forschungszentrum für Künstliche Intelligenz erforscht werden (DFKI). Ebenso tragen linguistische Studien, wie sie an der Ludwig-Maximilians-Universität München (LMU) durchgeführt werden, dazu bei, die Komplexität von Mehrsprachigkeit besser zu verstehen.
Die Entwicklung von Informationssystemen, die Mehrsprachigkeit unterstützen, ist Gegenstand zahlreicher Forschungsarbeiten (ResearchGate), während europäische Initiativen zur Förderung von Mehrsprachigkeit vor allem im Bildungskontext die Wichtigkeit dieses Aspektes auf politischer Ebene unterstreichen (Europäische Kommission).
Ebenfalls wichtig sind die Fortschritte in der Softwareentwicklung, die multilinguale Unterstützung in verschiedene Plattformen integrieren, wie z.B. Autodesk (Autodesk Help) und Angular (Angular i18n Overview).
Qualitative Studien und Forschungen in der Pädagogik (siehe Fachportal Pädagogik) und weiterführende Forschungen wie die der TH Lübeck (TH Lübeck Publikation) bieten wertvolle Erkenntnisse für die effektive Nutzung von Mehrsprachigkeit in Bildungsumgebungen.
Das Deutsche Schulportal thematisiert die Doppelrolle von Mehrsprachigkeit als Lernvorteil und potenziellen Risikofaktor (Deutsches Schulportal), während die Europäische Lexikographie und ihre Publikationen (Euralex) die Bedeutung und Herausforderungen von multilingualen, kontrastiven Studien betonen.
Abschließend ist es wichtig anzuerkennen, dass die Analyse von Multilingualität ein dynamischer Bereich ist, der ständige Anpassungen und innovative Lösungen erfordert. Im Zuge dessen bleibt die interdisziplinäre Zusammenarbeit zwischen Sprachwissenschaftlern, Technologen, Pädagogen und anderen Fachleuten ein Schlüsselfaktor für den Erfolg.
meine persönliche Herangehensweise und Herausforderungen
Meine persönlich bevorzugte Herangehensweise umfasst folgende Schritte:
- Erkennung der Sprache
- Auswahl entsprechender Sentimentanalyse
Diese Methode wird häufig in der Praxis eingesetzt, birgt aber einige Herausforderungen und Einschränkungen:
- Spracherkennung – Erkennungsgenauigkeit: Die korrekte Erkennung der Sprache eines Textes ist der erste Schritt. Während dies bei längeren Texten mit klaren sprachlichen Merkmalen meist zuverlässig funktioniert, können kürzere Texte oder Texte mit gemischten Sprachen (wie es oft in sozialen Medien vorkommt) zu Fehlidentifikationen führen.
- Spezialisierte Sentiment-Modelle
- Ressourcen für verschiedene Sprachen: Für einige Sprachen, insbesondere Englisch, gibt es umfangreiche Ressourcen und hochentwickelte Sentiment-Analyse-Modelle. Für andere Sprachen können solche Ressourcen jedoch begrenzt sein, was zu weniger präzisen Analysen führt.
- Anpassung an kulturelle Kontexte: Selbst wenn die Sprache korrekt erkannt wird, müssen die Sentiment-Modelle an die kulturellen und sprachlichen Besonderheiten dieser Sprache angepasst sein. Wörter und Phrasen können je nach kulturellem Kontext unterschiedliche emotionale Konnotationen haben.
- Skalierbarkeit und Effizienz: Der Betrieb separater Modelle für jede Sprache kann aus Sicht der Systemressourcen und des Managements herausfordernd sein, insbesondere für Organisationen, die globale Datenströme in vielen verschiedenen Sprachen verarbeiten.
Alternative Ansätze
- Mehrsprachige Modelle: Neuere Entwicklungen in der NLP-Technologie, wie mehrsprachige Versionen von BERT und anderen Transformer-basierten Modellen, versuchen, ein einzelnes Modell zu trainieren, das Texte in mehreren Sprachen verarbeiten kann. Diese Ansätze nutzen oft Transfer Learning, um Wissen von einer Sprache auf eine andere zu übertragen.
- Kontextualisierung: Moderne Modelle versuchen, Kontext und kulturelle Nuancen über Sprachgrenzen hinweg zu erfassen, um die Genauigkeit der Sentiment-Analyse zu verbessern.
Schlussfolgerung
Die Verwendung von auf spezifische Sprachen optimierten Sentiment-Analyse-Modellen nach der Spracherkennung ist ein verbreiteter Ansatz, doch erfordert er erhebliche Ressourcen für die Entwicklung und Wartung dieser spezialisierten Modelle. Fortschritte in der mehrsprachigen NLP-Technologie bieten alternative Wege, um mit der Herausforderung der Multilingualität umzugehen, indem sie ein breiteres Spektrum an Sprachen mit einem einzigen, effizienteren Modell abdecken.
Kulturübergreifende und sprachliche Variationen
Ein weiteres zentrales Thema in der Sentiment-Analyse stellt die Berücksichtigung kulturübergreifender und sprachlicher Variationen dar. Beispielsweise könnte das Wort ’stolz‘ in westlichen Kulturen positive Konnotationen haben, während es in einigen asiatischen Kontexten als weniger wünschenswert angesehen wird. Ebenso kann das Emoji 😂, das im westlichen Kulturkreis oft Freude ausdrückt, in anderen Kulturen als Zeichen von Traurigkeit oder Spott interpretiert werden. Auch idiomatische Ausdrücke wie ‚Das ist der Hammer‘ im Deutschen, welche positiv gemeint sein können, verlieren in wörtlicher Übersetzung in andere Sprachen ihre Bedeutung und können zu Missverständnissen führen. Die Entwicklung von Systemen, die solche sprachlichen und kulturellen Nuancen erkennen, erfordert fortgeschrittene linguistische Algorithmen und eine umfassende, kulturell informierte Datenbasis. Die kontinuierliche Erforschung und Integration interkultureller Aspekte in die Sentiment-Analyse ist daher unerlässlich, um sicherzustellen, dass Analysen nicht nur sprachlich, sondern auch kulturell präzise und fair sind.
Umgang mit Ambiguität
Ambiguität, oder Mehrdeutigkeit, spielt eine wesentliche Rolle in der Sentiment-Analyse, da sie einen direkten Einfluss auf die Genauigkeit und Zuverlässigkeit der Analyseergebnisse hat. Ambiguität in der Sprache kann verschiedene Formen annehmen und stellt verschiedene Herausforderungen dar:
Typen der Ambiguität der Sprache
Lexikalische Ambiguität:
Einzelne Wörter können mehrere Bedeutungen haben. Zum Beispiel kann das Wort „leicht“ je nach Kontext „nicht schwer“ oder „nicht dunkel“ bedeuten. Diese Mehrdeutigkeit erschwert die korrekte Interpretation des Sentiments.
Syntaktische Ambiguität:
Die Struktur eines Satzes kann mehrdeutig sein, was zu unterschiedlichen Interpretationen führen kann. Beispielsweise kann der Satz „Ich sah den Mann mit dem Fernglas“ bedeuten, dass entweder der Beobachter oder der Mann ein Fernglas benutzt.
Semantische Ambiguität:
Sätze oder Ausdrücke können aufgrund ihres semantischen Inhalts mehrdeutig sein. Zum Beispiel kann der Satz „Das ist kinderleicht“ wörtlich oder ironisch gemeint sein.
Pragmatische Ambiguität:
Die Bedeutung eines Satzes kann von seinem Kontext abhängen, einschließlich der Absichten des Sprechers und des Hintergrundwissens des Hörers. Zum Beispiel kann die Aussage „Das ist ja eine tolle Leistung“ je nach Tonfall und Situation als Kompliment oder als Sarkasmus verstanden werden.
Herausforderungen
Erkennung des Kontextes:
Die korrekte Identifizierung des Sentiments hängt oft stark vom Kontext ab. Ohne Kontextverständnis kann die Analyse zu falschen Schlussfolgerungen führen.
Umgang mit Ironie und Sarkasmus:
Ironie und Sarkasmus sind Formen der Ambiguität, die besonders herausfordernd sind, da sie oft das Gegenteil von dem bedeuten, was wörtlich gesagt wird.
Berücksichtigung des kulturellen Hintergrunds:
Kulturelle Unterschiede können zu verschiedenen Interpretationen desselben Ausdrucks führen. Was in einer Kultur als positiv gilt, kann in einer anderen neutral oder sogar negativ aufgefasst werden.
Technologische Ansätze zur Bewältigung der Ambiguität
Advanced NLP-Techniken:
Fortgeschrittene NLP-Modelle, insbesondere solche, die Deep Learning und kontextuelle Modelle wie Transformer verwenden, sind besser in der Lage, Ambiguitäten zu handhaben, indem sie den umfassenden Kontext und die Nuancen der Sprache erfassen.
Manuelles Training und Anpassungen:
Die manuelle Anpassung von Sentiment-Analyse-Systemen und das Training mit annotierten Datensätzen, die Ambiguitäten enthalten, können helfen, die Genauigkeit in der Erkennung von Sentiments zu verbessern.
Schlussfolgerung
Ambiguität stellt eine signifikante Herausforderung in der Sentiment-Analyse dar, da sie die Interpretation von Texten komplex macht. Die Entwicklung effektiver Sentiment-Analyse-Systeme erfordert fortschrittliche Technologien und Ansätze, die in der Lage sind, mit den verschiedenen Formen der Ambiguität umzugehen. Das Verständnis und die Berücksichtigung von Ambiguitäten sind entscheidend, um präzise und zuverlässige Sentiment-Analysen durchzuführen.
Skalierbarkeit und Echtzeit-Verarbeitung
Die digitale Transformation von Unternehmen, verbunden mit immer größerer Datenmengen und der Notwendigkeit einer prompten Datenverarbeitung, hat zwei wesentliche technische Herausforderungen in den Vordergrund gerückt: Skalierbarkeit und Echtzeit-Verarbeitung.
Skalierbarkeit
Skalierbarkeit bezieht sich auf die Fähigkeit eines Systems, mit einer Zunahme von Last umzugehen, ohne an Performance zu verlieren. Herausforderungen im Kontext der Skalierbarkeit sind vielfältig und umfassen sowohl Hardware- als auch Softwareaspekte. Themen wie Datenverteilung, Lastausgleich, Microservices, und die Aufrechterhaltung von Leistungsspitzen, werden in zahlreichen Publikationen und technischen Diskursen behandelt.
Das Paper „The Challenges of Software Scalability and How to Overcome Them“ von PilotCore Systems thematisiert beispielsweise Ansätze zur Bewältigung von Skalierungsproblemen in modernen Softwarearchitekturen. Die Publikation schlägt vor, dass man durch den Einsatz von Microservices und Cloud-basierten Technologien, wie sie auf Google Cloud Dataflow verfügbar sind, solche Herausforderungen meistern kann.
Die Bundesnetzagentur setzt sich in ihrer Publikation „Einführung in die Blockchain-Technologie“ mit der Skalierbarkeit von verteilten Systemen auseinander, die besonders für Transaktionssysteme wie die Blockchain von wesentlicher Bedeutung ist.
Die Skalierbarkeit in Bezug auf die Sentimentanalyse bezieht sich auf die Fähigkeit eines Sentiment-Analyse-Systems, effizient und effektiv mit einer zunehmenden Menge und Vielfalt von Daten umzugehen. Hier sind einige Aspekte, die die Bedeutung der Skalierbarkeit in der Sentiment-Analyse hervorheben:
Verarbeitung Großer Datenvolumen
Soziale Medien und Online-Plattformen:
Mit dem exponentiellen Wachstum von User-generated Content auf sozialen Medien, Blogs, Foren und Review-Plattformen wächst auch das Datenvolumen, das analysiert werden muss. Ein skalierbares Sentiment-Analyse-System muss große Mengen an Textdaten effizient verarbeiten können.
Echtzeitanalyse:
In vielen Anwendungsfällen, wie bei der Markenüberwachung oder in der Finanzmarktanalyse, ist eine schnelle Verarbeitung der Daten erforderlich, um zeitnahe Einsichten und Reaktionen zu ermöglichen.
Vielfalt der Datenquellen
Unterschiedliche Datenformate:
Textdaten kommen in verschiedenen Formaten vor, von strukturierten Reviews bis hin zu unstrukturierten sozialen Medien-Posts. Ein skalierbares System muss in der Lage sein, mit dieser Vielfalt umzugehen.
Multilingualität:
Unternehmen und Organisationen, die global agieren, müssen in der Lage sein, Sentiment-Analysen in mehreren Sprachen durchzuführen. Skalierbarkeit in diesem Kontext bedeutet die Fähigkeit, Modelle auf mehrere Sprachen auszuweiten.
Technologische Herausforderungen
Rechenressourcen:
Sentiment-Analyse, besonders wenn sie fortgeschrittene NLP-Techniken oder Deep Learning verwendet, kann rechenintensiv sein. Skalierbare Lösungen erfordern effizientes Management von Rechenressourcen, einschließlich der Nutzung von Cloud-Diensten und paralleler Verarbeitung.
Anpassungsfähigkeit:
Ein skalierbares Sentiment-Analyse-System sollte flexibel genug sein, um sich an sich ändernde Datenmengen, neue Datenquellen und sich entwickelnde Sprachgebrauche anzupassen.
Wirtschaftliche und Geschäftliche Betrachtungen
Kosteneffizienz:
Die Skalierung von Systemen muss wirtschaftlich tragbar sein. Unternehmen müssen das Kosten-Nutzen-Verhältnis bei der Erweiterung ihrer Sentiment-Analyse-Kapazitäten berücksichtigen.
Breitere Anwendungsfälle:
Skalierbare Systeme ermöglichen es Unternehmen, Sentiment-Analyse in einer Vielzahl von Geschäftsbereichen einzusetzen, von Kundenbeziehungsmanagement bis hin zu Produktentwicklung.
Schlussfolgerung
Skalierbarkeit in der Sentiment-Analyse ist wesentlich, um mit dem rasanten Wachstum und der Diversität der Daten Schritt zu halten. Sie erfordert technologische Anpassungsfähigkeit, effizientes Ressourcenmanagement und eine kontinuierliche Anpassung an neue Herausforderungen. Die Fähigkeit, effizient zu skalieren, ermöglicht es Organisationen, aus umfangreichen Datenmengen wertvolle Einsichten zu gewinnen und wettbewerbsfähig zu bleiben.
Echtzeit-Verarbeitung
Echtzeit-Verarbeitung bezieht sich auf die Fähigkeit eines Systems, Daten so schnell zu verarbeiten, dass ein unmittelbarer Datenfluss gewährleistet wird. Diese Anforderung ist insbesondere in Systemen relevant, die eine sofortige Reaktion erfordern, wie zum Beispiel in der Prozesssteuerung oder bei Finanztransaktionen.
Die Publikation „Advanced Real-Time Location Services Using Bluetooth Low-Energy-Technology“ zeigt auf, wie Echtzeit-Verarbeitung in Location-Based Services eine Schlüsselrolle spielt. Weiterhin setzt sich die Azure-Architektur mit Echtzeit-Datenverarbeitung auseinander und bietet einen Überblick darüber, wie man Daten in einem Real-Time Data Lakehouse-Szenario verarbeitet.
Ein Beispiel für ein Echtzeitsystem stellt Wikipedia zur Verfügung, das verschiedene Typen und Anwendungsbereiche erklärt und auf die spezifischen Eigenschaften und Anforderungen dieser Systeme eingeht.
Die Echtzeit-Verarbeitung in der Sentiment-Analyse spielt eine zunehmend wichtige Rolle, insbesondere in dynamischen und schnelllebigen Bereichen wie Social Media Monitoring, Kundenservice und Finanzmarktanalyse.
Bedeutung der Echtzeit-Verarbeitung
Sofortige Einsichten und Reaktionen:
In sozialen Medien und Online-Plattformen können Meinungen und Stimmungen schnell wechseln. Die Echtzeit-Analyse ermöglicht es Unternehmen, unmittelbar auf positive oder negative Trends zu reagieren.
Krisenmanagement:
Die Fähigkeit, Stimmungen in Echtzeit zu erfassen, ist entscheidend für das Krisenmanagement. Negative Sentiments können schnell identifiziert und adressiert werden, bevor sie sich weiter verbreiten.
Kundenerfahrung:
Im Kundenservice ermöglicht die Echtzeit-Sentiment-Analyse ein sofortiges Feedback und die Anpassung der Kundeninteraktion, um eine positive Kundenerfahrung zu gewährleisten.
Marktanalyse:
In der Finanzbranche kann die Echtzeit-Analyse von Nachrichten und sozialen Medien wichtige Indikatoren für Marktbewegungen liefern.
Probleme und Herausforderungen
Verarbeitungsgeschwindigkeit:
Die größte Herausforderung ist die schnelle Verarbeitung großer Datenmengen. Echtzeit-Systeme müssen in der Lage sein, Daten kontinuierlich und in kürzester Zeit zu verarbeiten und zu analysieren.
Datenqualität und -vielfalt:
Die Qualität und Vielfalt der Daten in Echtzeit können variieren. Umgangssprachliche Ausdrücke, Slang, Rechtschreibfehler und Mehrdeutigkeiten erhöhen die Komplexität der Analyse.
Skalierbarkeit:
Systeme müssen skalierbar sein, um Spitzenlasten zu bewältigen, insbesondere bei plötzlichen Ereignissen, die zu einem starken Anstieg der Datenmengen führen.
Genauigkeit:
Das Gleichgewicht zwischen Verarbeitungsgeschwindigkeit und Genauigkeit ist schwierig. Schnelle Systeme neigen dazu, weniger genau zu sein, insbesondere bei der Erkennung von feinen sprachlichen Nuancen wie Ironie oder Sarkasmus.
Kontextverständnis:
Echtzeitanalysen können es schwierig machen, den vollständigen Kontext eines Gesprächs oder einer Diskussion zu erfassen, was zu Fehlinterpretationen führen kann.
Datenschutz und ethische Bedenken:
Die Verarbeitung persönlicher Daten in Echtzeit wirft Fragen des Datenschutzes und der Einhaltung von Datenschutzbestimmungen auf.
Fazit
Die Echtzeit-Verarbeitung in der Sentiment-Analyse bietet erhebliche Vorteile für Unternehmen und Organisationen, erfordert jedoch fortgeschrittene technologische Lösungen, um die Herausforderungen der Verarbeitungsgeschwindigkeit, Genauigkeit und Skalierbarkeit zu bewältigen. Zudem müssen Datenschutz und ethische Überlegungen berücksichtigt werden, um einen verantwortungsvollen Umgang mit sensiblen Daten zu gewährleisten. Fortschritte in Bereichen wie Cloud-Computing, Edge-Computing und KI-basierte Analysetechniken tragen dazu bei, diese Herausforderungen zu meistern.
Zusammenfassung
Die Skalierbarkeit und Echtzeit-Verarbeitung sind Schlüsselfaktoren für erfolgreiche moderne Systeme. Während sich die Skalierbarkeit mit der Effizienz bei wachsendem Datenverkehr und Nutzervolumen befasst, sorgt die Echtzeit-Verarbeitung dafür, dass Daten prompt verarbeitet und bereitgestellt werden. Unternehmen stehen vor der Aufgabe, beide Aspekte zu meistern, was ein gründliches Verständnis der zugrunde liegenden Prinzipien und den Einsatz geeigneter Technologien erfordert. Die genannten Ressourcen bieten einen tiefen Einblick in beide Themenfelder und stellen Konzepte, Herausforderungen und bewährte Lösungsansätze vor, die zur Überwindung dieser Hürden erforderlich sind.
Ethische und Datenschutzüberlegungen
Ethische und Datenschutzüberlegungen spielen eine entscheidende Rolle in der Sentiment-Analyse. Die Verwendung von personenbezogenen Daten, wie sie in Online-Bewertungen oder sozialen Medien vorkommen, wirft Fragen bezüglich der Einwilligung der Nutzer und des Datenschutzes auf. Beispielsweise kann die Analyse von Tweets oder Kommentaren ohne explizite Zustimmung der Nutzer ethische Bedenken hervorrufen. Darüber hinaus besteht die Gefahr von Verzerrungen in den Daten, die zu diskriminierenden Schlussfolgerungen führen könnten. Ein Beispiel hierfür wäre ein System, das aufgrund von unzureichenden Trainingsdaten bestimmte Dialekte oder Sprachmuster falsch interpretiert und so systematisch bestimmte Nutzergruppen benachteiligt. Die Entwicklung von Sentiment-Analyse-Systemen erfordert daher einen sorgfältigen Umgang mit persönlichen Daten und eine fortwährende Überprüfung auf mögliche Verzerrungen, um faire und ethisch vertretbare Analysen zu gewährleisten.
Arten der Sentiment-Analyse
Emotion Detection Sentiment Analysis
Die Emotion Detection Sentiment Analysis konzentriert sich darauf, spezifische Emotionen in Texten zu identifizieren, wie Freude, Traurigkeit, Wut oder Überraschung. Diese Art der Analyse geht über die einfache positive, negative oder neutrale Einstufung hinaus und versucht, die Bandbreite menschlicher Emotionen in Textdaten zu erfassen. Ein Beispiel hierfür wäre die Analyse von Kundenfeedback in sozialen Medien, um nicht nur die allgemeine Stimmung, sondern auch spezifische emotionale Reaktionen auf ein Produkt oder eine Dienstleistung zu erkennen.
Aspect-Based Sentiment Analysis
Die Aspect-Based Sentiment Analysis (ABSA) zielt darauf ab, die Stimmung in Bezug auf spezifische Aspekte oder Merkmale eines Produkts oder einer Dienstleistung zu analysieren. Anstatt einen gesamten Text als positiv oder negativ einzustufen, identifiziert ABSA spezifische Aspekte (wie Preis, Qualität, Kundenservice) und analysiert die Stimmung bezüglich dieser Aspekte. Beispielsweise könnte bei der Analyse von Restaurantbewertungen ABSA genutzt werden, um die Stimmung bezüglich des Essens, des Services und der Atmosphäre separat zu bewerten.
Fine-Grained Sentiment Analysis
Die Fine-Grained Sentiment Analysis unterteilt die Stimmung in mehrere Ebenen, typischerweise von sehr negativ bis sehr positiv. Diese Art der Analyse bietet eine detailliertere Einsicht in die Stimmung als eine einfache positive/negative Klassifikation. Ein Beispiel hierfür ist die Analyse von Produktbewertungen, bei der Bewertungen auf einer Skala von 1 (sehr negativ) bis 5 (sehr positiv) kategorisiert werden, um ein nuancierteres Bild der Kundenmeinungen zu erhalten.
Intent-Based Sentiment Analysis
Die Intent-Based Sentiment Analysis fokussiert auf die Erkennung der Absicht hinter einem Text. Diese Methode untersucht, ob der Zweck eines Textes informativ, beschwerend, anfragend oder lobend ist. So könnte bei der Analyse von Kunden-E-Mails an einen Support-Service die Intent-Based Sentiment Analysis helfen, die E-Mails zu kategorisieren und Prioritäten für die Bearbeitung zu setzen, basierend darauf, ob die Absicht des Kunden eine Beschwerde, eine Anfrage nach Informationen oder Feedback ist.
Beispiel
„Ich habe kürzlich im Restaurant ‚Zum Goldenen Löffel‘ gegessen. Das Essen war absolut hervorragend, besonders die Pasta war ein Traum. Allerdings war der Service ziemlich langsam und der Kellner schien genervt. Das Ambiente war gemütlich, aber ein bisschen zu dunkel für meinen Geschmack. Insgesamt war es ein gutes Erlebnis, aber es gibt definitiv Raum für Verbesserungen im Servicebereich.“
Analyse der Rezension:
- Emotion Detection Sentiment Analysis: Die Rezension zeigt eine Mischung aus Emotionen. Freude und Begeisterung über das Essen („absolut hervorragend“, „ein Traum“), enttäuscht und leicht verärgert über den Service („ziemlich langsam“, „genervt“).
- Aspect-Based Sentiment Analysis: Bezüglich der verschiedenen Aspekte des Restaurantbesuchs ergibt sich folgendes Bild: Essen (sehr positiv), Service (negativ), Ambiente (gemischt, tendenziell positiv).
- Fine-Grained Sentiment Analysis: Wenn man die Stimmung auf einer Skala bewerten würde, könnte das Essen mit ’sehr positiv‘ (5/5), der Service mit ’negativ‘ (2/5) und das Ambiente mit ’neutral bis positiv‘ (3/5) bewertet werden.
- Intent-Based Sentiment Analysis: Die Absicht der Rezension scheint hauptsächlich informativ zu sein, mit dem Ziel, spezifisches Feedback zu verschiedenen Aspekten des Restaurantbesuchs zu geben.
Diese Analyse zeigt, wie die verschiedenen Arten der Sentiment-Analyse dazu beitragen können, ein umfassendes Bild der Kundenmeinung zu erhalten, indem sie verschiedene Aspekte und Nuancen der Rezension berücksichtigen.
APIs und deren Umfang
| API-Lösung | emotion detection | aspect-based | fine-grained | intent-based | Sprachen |
| Google Cloud Natural Language | x | x | |||
| Amazon Comprehend | x | Deutsch, Englisch, Spanisch, Italienisch, Portugiesisch, Französisch, Japanisch, Koreanisch, Hindi, Arabisch, Chinesisch (vereinfacht und traditionell) | |||
| IBM Watson Natural Language | x | ||||
| Microsoft Azure AI Language | x |
Praktische Anwendung der Sentiment-Analyse
Sentiment-Analyse im Marketing
Im digitalen Zeitalter, in dem soziale Medien und Online-Interaktionen eine zentrale Rolle spielen, hat die Sentiment-Analyse sich als ein wesentliches Instrument im Arsenal des Marketings etabliert. Für das Marketing liefert sie wertvolle Einblicke in die Kundenwahrnehmung und hilft dabei, Markenstrategien effektiver zu gestalten.
Verständnis der Kundenperspektive
Marketing-Fachleute nutzen die Sentiment-Analyse, um zu verstehen, wie Kunden über ihre Produkte oder Dienstleistungen denken. Durch die Analyse von Kundenrezensionen, Social-Media-Kommentaren und anderen Online-Diskussionen können Marken positive, negative und neutrale Stimmungen identifizieren. Diese Informationen sind entscheidend, um die Kundenzufriedenheit zu verbessern, Krisenmanagement zu betreiben, und auch, um positive Aspekte hervorzuheben und auf sie aufzubauen.
Anwendungsbereiche
Einige der praktischen Anwendungsbereiche der Sentiment-Analyse im Marketing umfassen:
- Produktfeedback: Unternehmen können Produktrezensionen analysieren, um zu verstehen, welche Aspekte des Produkts gelobt oder kritisiert werden.
- Markenüberwachung: Sentiment-Analyse ermöglicht es, die allgemeine Meinung über die Marke im Zeitverlauf zu verfolgen und auf potentielle PR-Probleme schnell zu reagieren.
- Kampagnenanalyse: Die Auswertung der Stimmungslage bezüglich Marketingkampagnen kann Aufschluss darüber geben, welche Botschaften resonieren und welche nicht.
- Mitbewerberanalyse: Unternehmen können die Wahrnehmung von Wettbewerberprodukten beurteilen und daraus strategische Einsichten gewinnen.
Techniken und Werkzeuge
Moderne Sentiment-Analyse-Tools nutzen fortgeschrittene Algorithmen, einschließlich maschinellem Lernen und Natural Language Processing (NLP), um Texte zu analysieren und Sentiment effizient zu klassifizieren. Tools wie Brand24, Keyhole und Infranodus bieten robuste Plattformen zur Überwachung von Marken und Wettbewerbern.
Case Studies: Sentiment-Analyse in Aktion
Fallstudien zu erfolgreichen Marken wie Nike und Lidl zeigen, wie Sentiment-Analyse dazu beitragen kann, soziale Medien und Marketingstrategien zu optimieren. Nike nutzt beispielsweise Sentiment-Analyse, um seine Social-Media-Strategie zu steuern, während Lidl auf KI-basierte Marketingkampagnen setzt, welche die Kundenstimmung berücksichtigen, um die Botschaften zu personalisieren und die Interaktion zu erhöhen.
Fazit
Die Sentiment-Analyse ist für das Marketing unverzichtbar geworden. Sie ermöglicht es, tieferen Einblick in die Gedanken und Gefühle der Kunden zu erhalten und darauf aufbauende, datengesteuerte Entscheidungen zu treffen. In einer Welt, in der die Kundenmeinung im Netz schnell das Markenimage prägen kann, ist es für Marketingspezialisten wichtiger denn je, die Werkzeuge und Methoden der Sentiment-Analyse zu beherrschen, um die Strategien ihrer Kunden erfolgreich zu gestalten und zu optimieren.
Sentiment-Analyse in sozialen Medien
In der Anwendung auf soziale Medien bietet Sentiment-Analyse Unternehmen, Forschern und Public Relations-Experten die Möglichkeit, öffentliche Meinungen über Produkte, Dienstleistungen, Kampagnen und Trends zu verstehen. Hierbei wird maschinelles Lernen und Natural Language Processing (NLP) verwendet, um aus der Unmenge an Nutzer-erzeugtem Inhalt wertvolle Einsichten zu gewinnen.
Grundlagen der Sentiment-Analyse in sozialen Medien
Sentiment-Analyse in den sozialen Medien analysiert Daten aus Plattformen wie Twitter, Facebook, Instagram und anderen Foren, um Stimmungen und Meinungen der Nutzer zu identifizieren. Wie auf bernet.ch und reputativ.com beschrieben, erkennt die Sentiment-Analyse positive, negative und neutrale Stimmungen und kann sogar spezifischere Emotionen wie Wut, Freude oder Enttäuschung aufdecken. Das grundlegende Ziel dabei ist, ein besseres Verständnis für die Kundenstimme zu entwickeln.
Praktische Umsetzung
In der praktischen Umsetzung der Sentiment-Analyse in sozialen Medien werden spezialisierte Tools und Plattformen wie die von cloud.google.com oder talkwalker.com verwendet um Strukturen und Muster in den Daten zu erkennen. Diese Werkzeuge sind in der Lage, große Datenmengen in Echtzeit zu analysieren, was für die Überwachung von Marken- und Produktreaktionen entscheidend ist. Beispiele für die praktische Umsetzung werden in Fallstudien auf guidehouse.com und in wissenschaftlichen Publikationen wie ncbi.nlm.nih.gov erörtert.
Anwendungsbereiche in sozialen Medien
Die Anwendungsbereiche der Sentiment-Analyse in sozialen Medien sind breit gefächert. Unternehmen nutzen sie für:
- Markenüberwachung: Die Einschätzung der öffentlichen Wahrnehmung einer Marke im Zeitverlauf ermöglicht es Unternehmen, ihre Strategien anzupassen. (Quellen: meltwater.com, sozial-pr.net)
- Produktfeedback: Die Analyse von Kundenmeinungen zu Produkten liefert wichtige Erkenntnisse für Produktentwicklung und -verbesserung. (Quelle: hotjar.com)
- Krisenmanagement: Durch die frühzeitige Erkennung negativer Stimmungen können Unternehmen potenzielle Krisen identifizieren und entsprechend reagieren. (Quelle: bdu.de)
- Kampagnenanalyse: Die Auswertung der Reaktionen auf Marketingkampagnen hilft bei der Bewertung von deren Erfolg. (Quelle: flaminjoy.com)
- Kundendienst: Die Analyse von Kundenfeedback kann dazu beitragen, den Kundenservice zu verbessern und dessen Effektivität zu steigern. (Quelle: computerweekly.com)
Herausforderungen und zukünftige Entwicklungen
Die Sentiment-Analyse in sozialen Medien steht vor einigen Herausforderungen. Dazu gehören Mehrdeutigkeiten in der Sprache, Ironie, Slang und wechselnder Kontext. Somit ist die kontinuierliche Weiterentwicklung der NLP- und KI-Technologien unverzichtbar. Zukünftige Verbesserungen könnten eine noch genauere und dynamischere Emotionserkennung ermöglichen.
Fazit
Die Sentiment-Analyse in sozialen Medien hat sich zu einem wichtigen Werkzeug für Unternehmen und Organisationen entwickelt, um Verbraucherwahrnehmungen und Marktrends zu verstehen. Die Verfügbarkeit hochentwickelter Analysetools ermöglicht eine effiziente und präzise Analyse der riesigen Menge an Daten, die täglich in sozialen Netzwerken generiert werden. Als Disziplin, die eng mit den raschen Entwicklungen im Bereich der Künstlichen Intelligenz und des maschinellen Lernens verknüpft ist, bleibt die Sentiment-Analyse ein spannendes und sich ständig weiterentwickelndes Feld.
Sentiment-Analyse im Kundenservice
Durch die automatisierte Analyse von Kundenfeedback können Unternehmen tiefergehende Einblicke in die Kundenzufriedenheit erhalten und somit den Service verbessern.
Kundenservice steht stets im direkten Kontakt mit den Kunden. Feedback, sei es in Form von Bewertungen, E-Mails, Chatprotokollen oder in sozialen Medien (blog.hootsuite.com/de), liefert wertvolle Einsichten in die Kundenzufriedenheit. Die Sentiment-Analyse kann helfen, diese Meinungsäußerungen zu kategorisieren, Trends zu erkennen und frühzeitig auf Probleme zu reagieren (computerweekly.com/de). Dadurch wird ein proaktives Service Management möglich, das Kundenzufriedenheit und -bindung erhöht.
Praktische Anwendung im Kundenservice
Auswertung von Kundenfeedback
Unternehmen erhalten täglich eine Vielzahl an Kundenfeedback durch verschiedene Kanäle. Die Sentiment-Analyse kann dabei unterstützen, diese Datenmengen zu verarbeiten, indem sie positive, neutrale und negative Äußerungen identifiziert. Tools wie die bereits beschriebenen Machine Learning Modelle, um die Tonalität in Texten zu bewerten und Unternehmen zu ermöglichen, schnell auf kritische Feedbacks zu reagieren.
Verständnis und Verbesserung des Customer Journeys
Mit Hilfe der Sentiment-Analyse können Unternehmen die Customer Journey kartieren und emotionale High- und Low-Points identifizieren. Dienste wie Hotjar bieten die Möglichkeit, Usability-Tests mit Sentiment-Daten anzureichern, um so die Nutzererfahrung (User Experience) zu verstehen und zu verbessern.
Echtzeit-Service und Support
Durch die Echtzeit-Analyse von Kundeninteraktionen im Support, beispielsweise via Live-Chat, können Servicemitarbeiter ein besseres Verständnis für die Kundenstimmung entwickeln und entsprechend empathisch reagieren. Dies kann die Kundenzufriedenheit erheblich steigern und dazu beitragen, potenzielle Servicekrisen abzuwenden.
Schulung von Service-Personal
Die Erkenntnisse aus der Sentiment-Analyse können genutzt werden, um Schulungsprogramme zu entwickeln. Dadurch lernen Kundendienstmitarbeiter, sensibler auf die emotionale Verfassung des Kunden einzugehen und können ihre Kommunikationsstrategien verbessern (zukunftsinstitut.de).
Chatbots und automatisierte Dienste
Immer häufiger werden KI-gestützte Chatbots im Kundenservice eingesetzt. Durch die Integration von Sentiment-Analyse-Tools können diese Systeme nicht nur informative, sondern auch empathische Antworten generieren, die auf die Stimmung des Kunden abgestimmt sind.
Tools und Technologien
Zahlreiche Anbieter wie HubSpot, Voxco, MonkeyLearn oder Qualtrics bieten spezialisierte Tools für die Sentiment-Analyse an. Diese variieren in ihrer Komplexität von einfachen Plug-and-play-Lösungen bis hin zu maßgeschneiderten AI-Systemen.
Fazit
Die Sentiment-Analyse bietet im Kundenservice enorme Möglichkeiten zur Datenanalyse und zur Verbesserung der Kundenkommunikation. Die praktische Anwendung dieser Technologie ermöglicht es Unternehmen, Kundenerwartungen besser zu verstehen und Serviceerlebnisse individuell anzupassen. Um dies effektiv zu tun, ist es notwendig, die richtigen Tools auszuwählen und die gewonnenen Einsichten konsequent umzusetzen. Die digitale Transformation des Kundenservices ist ein fortlaufender Prozess, bei dem die Sentiment-Analyse eine Schlüsselrolle in der strategischen Entwicklung spielt.
Monitoring von Markentrends durch Sentiment-Analyse
Einführung
In der heutigen, schnelllebigen Geschäftswelt ist es unabdingbar, dass Unternehmen nicht nur ihre Zielmärkte verstehen, sondern auch die Stimmungen und Einstellungen, die Verbraucher gegenüber ihren Marken hegen. Einsatzmöglichkeiten sind vielfältig, wie die Qualtrics-Website ausführt, umfassen aber insbesondere das Monitoring von Markentrends.
Wesentliche Aspekte und Nutzen der Sentiment-Analyse
Die Analyse von Konsumentenmeinungen unterstützt Brand-Manager dabei, Stimmungstrends zu erkennen und rechtzeitig darauf zu reagieren. Wie aus dem Dissertationsteil hervorgeht, bietet die Sentiment-Analyse Einblicke in die nicht nur quantitativen, sondern auch qualitativen Aspekte von Kundenfeedback.
Aus den Quellen von SRH Berlin und Cogitaris erfahren wir, dass mithilfe der Sentiment-Analyse riesige Mengen an unstrukturierten Textdaten aus Bewertungen, Social Media, Foren oder Kundenfeedback in strukturierte Daten umgewandelt werden können. Diese Informationen bieten wertvolle Einblicke in die öffentliche Wahrnehmung einer Marke und ermöglichen es Unternehmen, Trends frühzeitig zu erkennen und entsprechend zu handeln.
Methoden und Techniken
Unternehmen wie QuestionPro und Mindsquare bieten fortschrittliche Lösungen und Tools zur Durchführung der Sentiment-Analyse. Diese Technologien nutzen maschinelles Lernen und natürliche Sprachverarbeitung (Natural Language Processing, NLP), um Stimmungen in Texten zu erkennen und zu klassifizieren.
Die IKUM-Arbeit hebt hervor, dass moderne Systeme der Sentiment-Analyse nicht nur simple positive oder negative Stimmungen erkennen können, sondern auch komplexere Emotionen und Meinungsnuancen in den Daten aufspüren können. So können detailliertere Profile von Verbraucherstimmungen erzeugt werden, die für das Monitoring von Markentrends entscheidend sind.
Praxisanwendungen und Case Studies
Praxisbeispiele, etwa die beschriebenen, zeigen, wie durch die Analyse von Nutzerkommentaren in Echtzeit Reaktionen auf Marketingkampagnen oder öffentliche Ereignisse verfolgt werden können. Unternehmen nutzen diese Erkenntnisse, um ihre Kommunikationsstrategien anzupassen und das Markenimage zu schützen oder zu verbessern.
Darüber hinaus verdeutlicht das Rosalux-Paper, dass Sentiment-Analyse auch für das Verständnis übergeordneter gesellschaftlicher Trends eingesetzt werden kann, die wiederum Einfluss auf das Konsumverhalten haben können.
Herausforderungen und Grenzen
Trotz der vielseitigen Anwendungsmöglichkeiten dürfen die Grenzen der Technologie nicht außer Acht gelassen werden. Quellen wie die von der UWI Cave Hill und Quickheal betonen die Herausforderungen im Umgang mit Ironie, Sarkasmus und kulturell spezifischen Ausdrücken, die von Algorithmen oft fehlinterpretiert werden können.
Zukunftsperspektiven und Entwicklung
Abschließend skizziert Simon Schnetzer die Bedeutung von Sentiment-Analyse für die Anpassung an die sich ständig ändernden Vorlieben jüngerer Generationen, die vermehrt Wert auf Authentizität und soziale Verantwortung der Marken legen. In einer Welt, in der Daten das neue Gold sind, wird die Sentiment-Analyse weiterhin eine Schlüsselrolle spielen, um wertvolle Einblicke in das Verhalten und die Einstellungen von Konsumenten zu gewinnen und den Erfolg von Marken zu fördern.
Fallstudien und Erfolgsgeschichten
Sentiment-Analyse in der Politik
Einführung
In der heutigen, digital dominierten Welt spielt die öffentliche Meinung in der Politik eine entscheidende Rolle. Politische Akteure, Wahlkampfteams und politische Analyst:innen setzen daher zunehmend auf Technologien wie die Sentiment-Analyse, um Meinungen, Einstellungen und Gefühle der Wählerschaft zu verstehen und darauf zu reagieren. Die Sentiment-Analyse, auch Stimmungsanalyse genannt, ist ein Zweig der Datenwissenschaft, der sich damit beschäftigt, Texte mithilfe von Natural Language Processing (NLP), Textanalyse und Computational Linguistics zu bewerten, um subjektive Informationen herauszufiltern.
Anwendungsbeispiele
Fallstudie 1: Wahlkampfanalyse
In einer jüngsten Wahlkampagne nutzte ein Kandidat die Sentiment-Analyse, um die Reaktionen auf seine Reden und Wahlkampfveranstaltungen in Echtzeit zu verfolgen. Social Media Posts wurden überwacht, um die Stimmung der Wähler:innen zu messen. Das Team konnte feststellen, welche Themen positiv aufgenommen wurden und welche negativen Sentiments hervorriefen. Diese Einsichten halfen dabei, die Kampagnenstrategie anzupassen und die Kommunikation für zukünftige Veranstaltungen zu optimieren.
Fallstudie 2: Analyse von Fernsehdebatten
Sentiment-Analyse wurde ebenfalls verwendet, um die Leistungen von Kandidat:innen in Fernsehdebatten zu analysieren. Durch die Auswertung von Live-Tweets und Online-Kommentaren während der Debatte konnte identifiziert werden, welche Argumente und welche Auftritte die öffentliche Meinung beeinflussten. Dies half den Kampagnen, sich auf Stärken zu konzentrieren und Schwächen in Vorbereitung auf zukünftige Debatten zu adressieren.
Fallstudie 3: Reaktionen auf politische Skandale
Eine weitere Anwendung ist die Analyse von Bürger:innenreaktionen auf politische Skandale. Als ein Skandal um einen politischen Akteur aufkam, analysierten Forscherinnen und Forscher mit Sentiment-Analyse die öffentliche Meinung in Echtzeit. Ergebnisse zeigten eine schnelle Verschlechterung des Sentiments, und das Team des betroffenen Politikers konnte schnell mit Schadensbegrenzungsstrategien reagieren.
Fallstudie 4: Politische Stimmungsüberwachung
Langfristige Sentiment-Analysen werden auch für die Überwachung der politischen Stimmung eingesetzt. Indem Daten über längere Zeiträume gesammelt und analysiert werden, können Trends und Meinungsverschiebungen in der Bevölkerung festgestellt werden. Diese Informationen sind hilfreich für die Planung von Kampagnen und die Entwicklung von politischen Botschaften, die mit den Ansichten der Wählerschaft im Einklang stehen.
Herausforderungen und Ethik
Trotz der Vorteile bringt die Sentiment-Analyse einige Herausforderungen mit sich. Ironie, Slang und kontextabhängige Bedeutungen können zu fehlerhaften Interpretationen führen. Auch die Frage der Privatsphäre und ethische Bedenken beim Sammeln und Analysieren von Daten sind wichtige Überlegungen.
Zusammenfassung und Ausblick
Sentiment-Analyse in der Politik liefert wertvolle Einsichten, die dazu beitragen können, Wahlkämpfe zu gestalten, politische Strategien zu schärfen und ein besseres Verständnis der öffentlichen Meinung zu erlangen. Mit fortschreitender Technologie wird diese Form der Analyse weiter verfeinert und spielt eine immer größere Rolle bei der Formung der politischen Landschaft. Zukünftige Entwicklungen könnten die Genauigkeit verbessern und noch tiefergehende Analysen der Stimmungen und Emotionen der Wähler:innen ermöglichen.
Finanzmarkt und Börsenprognosen
Einführung
Der Finanzmarkt ist ein komplexes Ökosystem, in dem Vermögenswerte wie Aktien, Anleihen und Derivate gehandelt werden. Die Fähigkeit, zukünftige Marktbewegungen und Trends vorherzusagen, ist entscheidend für Investoren und Finanzanalysten. Börsenprognosen basieren auf einer Vielzahl von Methoden, von fundamentaler und technischer Analyse bis hin zu quantitativen Modellen und Sentiment-Analyse. Dieses Unterkapitel konzentriert sich auf richtungweisende Fallstudien und Erfolgsgeschichten, die Licht auf erfolgreiche Prognosemethoden und -strategien werfen.
Quantitative Analyse: Der Black-Scholes-Merton Fall
Im Jahr 1973 präsentierten Fischer Black, Myron Scholes und Robert Merton das Black-Scholes-Modell, ein bahnbrechender Ansatz zur Bewertung von Optionen. Die darauf basierende Fallstudie zeigt, wie theoretische Finanzmodelle dazu beitragen können, Preise von Derivaten mit großer Genauigkeit zu prognostizieren. Die Erfolge des Modells beeinflussten nicht nur die Entwicklung neuer Finanzprodukte, sondern legten auch den Grundstein für das Risikomanagement und die Portfolio-Optimierung.
Fundamentalanalyse: Der Warren Buffett Weg
Warren Buffett, der CEO von Berkshire Hathaway, wurde durch seine Anlagestrategie, die sich stark auf die Fundamentalanalyse stützt, zu einem der erfolgreichsten Investoren. Durch die gründliche Bewertung von Unternehmen basierend auf ihren Geschäftsmodellen, finanziellen Aussagen und Marktpositionen konnte Buffett Aktien identifizieren, die unterbewertet waren und dadurch langfristige Erfolge erzielen. Seine Investitionen in Unternehmen wie Coca-Cola und American Express sind klassische Beispiele für die Validität der Fundamentalanalyse.
Technische Analyse: Der George Soros Fall
George Soros ist bekannt für seine Nutzung der technischen Analyse, insbesondere durch seine Wette gegen das Britische Pfund im Jahr 1992. Er erkannte Muster und Trends, die auf eine Überbewertung und die bevorstehende Abwertung des Pfunds hindeuteten. Durch den Einsatz von Leverage-Positionen konnte Soros erheblichen Profit aus diesen Vorhersagen ziehen. Diese Fallstudie demonstriert die Bedeutung der technischen Analyse und den Wert, der in der Erkennung von Chartmustern und -signalen liegt.
Machine Learning: Algorithmisches Trading
Die Nutzung von Machine Learning und künstlicher Intelligenz für Börsenprognosen ist ein vergleichsweise neues Feld, das beeindruckende Fortschritte zeigt. Algorithmen, die aus historischen Daten lernen, können Muster erkennen, die für menschliche Investoren undurchsichtig sind. Als Fallbeispiel lässt sich Renaissance Technologies anführen, ein Hedgefonds, der fortschrittliche mathematische Modelle nutzt und damit außerordentlich hohe Renditen erzielte. Diese Erfolgsgeschichte zeigt das Potential von algorithmischem Trading und die fortschreitende Digitalisierung des Finanzsektors.
Sentiment-Analyse: Die Kraft der Meinungen
Die Sentiment-Analyse, die Beurteilung der Stimmung auf dem Markt mittels Nachrichten, sozialen Medien und anderen Textquellen, wird zunehmend wichtig für Finanzprognosen. Ein interessanter Anwendungsfall ist die Reaktion der Märkte auf Tweets von einflussreichen Persönlichkeiten wie Elon Musk. Fallstudien zeigen, dass Äußerungen auf Twitter direkte und manchmal massive Auswirkungen auf Aktienpreise haben können. Dies unterstreicht die Bedeutung von psychologischen und emotionalen Faktoren bei der Vorhersage von Marktbewegungen.
Schlussbemerkung
Diese Unterkapitel hebt hervor, dass keine einzelne Methode alle Antworten auf die Herausforderungen des Finanzmarkts liefert. Erfolgreiche Börsenprognosen erfordern eine Kombination aus verschiedenen Analysen, ein tiefes Verständnis für den Markt und die Bereitschaft, sich neuen Technologien und Ansätzen anzupassen. Ob durch klassische Ansätze wie Fundamentalanalyse oder durch neuartige Techniken wie Machine Learning, die Fallstudien und Erfolgsgeschichten bieten wichtige Lehren für künftige Marktteilnehmer und Analysten.
Produktbewertungen und Verbraucherfeedback
Im digitalen Zeitalter spielen Produktbewertungen und Verbraucherfeedback eine entscheidende Rolle im Erfolg eines Unternehmens und seiner Produkte oder Dienstleistungen. Unternehmen streben danach, positive Erfahrungsberichte zu sammeln, nicht nur, um potenzielle Kunden zu überzeugen, sondern auch, um ihre Produkte und Services fortlaufend zu verbessern. In diesem Abschnitt werden wir untersuchen, wie Produktbewertungen und Verbraucherfeedback wertvolle Einblicke bieten, den Verkauf beeinflussen können und warum der Aufbau einer Feedbackkultur für Unternehmen von immenser Bedeutung ist.
Die Bedeutung von Produktbewertungen
Produktbewertungen sind ein mächtiges Werkzeug im Online-Handel. Sie bieten potenziellen Käufern eine Vorstellung davon, was sie erwarten können, wenn sie sich für ein Produkt entscheiden. Bewertungen haben oft einen direkten Einfluss auf die Kaufentscheidung und können die Konversionsrate und den Gesamtumsatz steigern oder mindern. Studien belegen, dass eine große Mehrheit der Online-Käufer Bewertungen liest, bevor sie einen Kauf tätigt.
Verbraucherfeedback als Marktforschungsinstrument
Verbraucherfeedback geht über die Sternebewertung hinaus. Detaillierte Kommentare und Erfahrungsaustausch geben Unternehmen einen Einblick in die Stärken und Schwächen ihrer Produkte. Feedback kann als kostenfreies Marktforschungsinstrument dienen, das es einem Unternehmen ermöglicht, Produkte zu verfeinern, Kundenservice zu verbessern und Innovationen voranzutreiben.
Fallstudien und ihre Rolle in der Nutzung von Feedback
Es gibt zahlreiche Beispiele von Unternehmen, die ihr Produktangebot und Kundenerlebnis auf Basis von Rückmeldungen erheblich verbessert haben. Fallstudien belegen, wie die konstruktive Nutzung von Feedback zu einer Verbesserung des Produktangebots und zu Innovationen führen kann. Beispielsweise hat der Technologieriese Apple durch das Sammeln und Analysieren des Feedbacks seiner Nutzer mehrere Verbesserungen an seinen Produkten vorgenommen, die zu einer höheren Kundenzufriedenheit und Markentreue geführt haben.
Positive Bewertungen als Marketinginstrument
Positive Produktbewertungen können als wirksame Marketinginstrumente fungieren. Sie bieten sozialen Beweis, der Vertrauen unter Konsumenten schafft und die Glaubwürdigkeit eines Produktes oder Dienstleistung stärkt. Durch die Hervorhebung positiver Bewertungen auf der Produktseite, in Werbekampagnen oder auf Social-Media-Plattformen können Unternehmen potenzielle Kunden beeinflussen und ihre Marke stärken.
Umgang mit negativem Feedback
Negatives Feedback ist unvermeidbar, aber die Art und Weise, wie ein Unternehmen damit umgeht, kann kritisch sein. Proaktives Adressieren von Problemen, die in negativen Bewertungen genannt werden, und das Anbieten von Lösungen kann Kundenbeschwerden in Chancen umwandeln und die Kundenbindung erhöhen. Offene Kommunikation und Transparenz bei der Behebung von Problemen führen oft zu einer positiven Wahrnehmung des Unternehmens.
Schaffung einer Feedbackkultur
Um den größtmöglichen Nutzen aus Produktbewertungen und Verbraucherfeedback zu ziehen, sollten Unternehmen eine Kultur schaffen, die das Sammeln und die Analyse von Kundenrückmeldungen fördert. Mitarbeiter sollten ermutigt werden, Kundenfeedback ernst zu nehmen und als Chance für persönliches Wachstum und Verbesserung zu betrachten.
Zusammenfassung
Fallstudien und Erfolgsgeschichten verdeutlichen, dass Produktbewertungen und Verbraucherfeedback zentrale Pfeiler der Kundenintelligenz und des Marketings sind. Sie tragen dazu bei, den Bedarf der Kunden besser zu verstehen, Produktdifferenzierung zu betonen und letztendlich den Verkauf zu steigern. Eine Strategie, die sich auf die Erhebung, Analyse und Reaktion auf Kundenfeedback konzentriert, kann nicht nur eine bessere Produktqualität fördern, sondern auch ein loyales Kundenstamm aufbauen, das im heutigen wettbewerbsintensiven Markt ein wesentlicher Erfolgsfaktor ist.
Zukunft der Sentiment-Analyse
Aktuelle Trends in der Sentiment-Analyse
Die Sentiment-Analyse hat sich zu einem entscheidenden Instrument in der Interpretation menschlicher Emotionen und Meinungen aus unstrukturierten Datenquellen, wie sozialen Medien, Kundenfeedback und anderen Bereichen der textuellen Kommunikation entwickelt. Mit der schnellen Evolution der Künstlichen Intelligenz (KI) und des maschinellen Lernens befindet sich auch die Sentiment-Analyse in einem stetigen Wandel. In diesem Abschnittwerfen wir einen Blick auf die aktuellen Trends in diesem Forschungsgebiet, basierend auf den neuesten wissenschaftlichen Erkenntnissen und Meinungsartikeln.
Multimodale und Kontextbezogene Analysen
In einer Studie wird die Bedeutung multimodaler Fähigkeiten in der Sentiment-Analyse hervorgehoben. Moderne Ansätze beziehen neben dem Text auch visuelle und akustische Informationen mit ein, um die Emotionalität der Nutzer besser zu verstehen. Solche multimodalen Systeme sind in der Lage, mehrschichtigere Kontextinformationen zu verarbeiten und führen so zu präziseren Analyseergebnissen.
Feinkörnige Sentiment-Erkennung
Beiträge aus dem Journal of Medical Internet Research und SSRN beleuchten den Trend zur feinkörnigen Sentiment-Analyse. Hier wird versucht, subtile Nuancen in den Meinungsäußerungen zu erfassen und damit über die herkömmliche Einteilung in „positiv“, „neutral“ und „negativ“ hinauszugehen. Die Identifizierung bestimmter Emotionen wie Freude, Vertrauen oder Wut ermöglicht eine tiefergehende Interpretation von Stimmungslagen.
Deep Learning und Transfer-Learning
Fortschrittliche Deep-Learning-Modelle, insbesondere diejenigen, die auf Transformern basieren, werden in der IEEE-Literatur (IEEE:9706209 und IEEE:10021083) diskutiert. Diese Modelle, wie BERT oder GPT-3/4, haben die Fähigkeit, aus großen Datensätzen zu lernen und können durch Transfer Learning schnell an spezifische Domänen angepasst werden. Solche Techniken ermöglichen es, auch komplexe sprachliche Muster und Ironie besser zu erkennen.
Echtzeitdatenanalyse und Interaktivität
Die dynamischen Bedingungen des Internets erfordern Echtzeitreaktionen, wie auf Medium (info-957 und analytics-vidhya) und Datamation nachzulesen ist. Sentiment-Analyse-Werkzeuge werden zunehmend in der Lage sein, in Echtzeit auf sich ändernde Meinungslagen zu reagieren und ermöglichen es Marken und Organisationen, unmittelbar auf Kundenfeedback zu antworten.
Anwendungen in spezifischen Domänen
Die Branchenspezifität ist ein weiterer Trend in der Entwicklung der Sentiment-Analyse, wie aus Artikeln auf I-JIM (I-JIM:10600) und auf Atlas.ti hervorgeht. Ob im Gesundheitswesen, im Marketing oder in der Finanzbranche, die Sentiment-Analyse wird zunehmend maßgeschneidert für spezifische Anwendungsfälle entwickelt, um tiefergehende Einblicke in die speziellen Bedürfnisse und die Eigenheiten der jeweiligen Industrie zu gewähren.
Ethik und Fairness
Die ethische Dimension und die Gewährleistung von Fairness werden ebenfalls zunehmend berücksichtigt, wie in der Annual Review of Statistics and Its Application (annurev-statistics-030718-105242) und AWS Blog (aws.amazon.com) beleuchtet. Fragen der Voreingenommenheit, des Datenschutzes und der Transparenz der Algorithmen werden stärker in den Vordergrund gerückt, um vertrauenswürdige AI-Systeme zu entwickeln.
Performance Monitoring und Erklärbarkeit
Die Frage nach der Erklärbarkeit von KI-Entscheidungen, insbesondere in der Sentiment-Analyse, gewinnt ebenfalls an Relevanz, wie auf Fast Data Science und in der Literatur betont wird. Die Überwachung der Performance und die Rückverfolgbarkeit der Analyseergebnisse werden unerlässlich, damit Benutzer und Forscher die Schlussfolgerungen der Systeme verstehen und nachvollziehen können.
Die Zukunft der Sentiment-Analyse liegt in der Entwicklung intelligenter, flexibler und ethisch verantwortungsvoller Systeme, die ein tiefgreifendes Verständnis menschlicher Kommunikation und Emotion ermöglichen und gleichzeitig mit den rasanten technologischen Entwicklungen Schritt halten können.
Die Zukunft der Sentiment-Analyse verspricht eine Weiterentwicklung in vielerlei Hinsicht, insbesondere im Bereich der Forschung und Entwicklung. Sentiment-Analyse-Technologien sind für viele Branchen von Bedeutung, darunter Medien, Marketing, Produktentwicklung und politische Beratung. Die Fortschritte in der künstlichen Intelligenz (KI) und im maschinellen Lernen (ML) treiben diese Entwicklung an.
Forschungstrends zeigen deutlich die Anstrengungen, die zur Verbesserung der Genauigkeit und des Anwendungsbereichs der Sentiment-Analyse unternommen werden. Methoden der Digitalen Technikanalyse (TA) eröffnen neue Perspektiven in der Wissenschaftsforschung. So zeigt ein Blick in die aktuellen Methoden, wie im Bericht des Büros für Technikfolgen-Abschätzung beim Deutschen Bundestag ersichtlich, dass es einen zunehmenden Fokus auf die Transparenz und Interpretierbarkeit von KI-Systemen gibt.
Der österreichische Mediensektor, wie in einem APA-Bericht erörtert, nutzt die Sentiment-Analyse aktiv zur Ermittlung öffentlicher Meinungen und Trends. Es werden fortgeschrittene ML-Algorithmen angewandt, um relevante Patterns zu erkennen und sentimentbasierte Auswertungen vorzunehmen. Diese Verfahren nutzen große Datenmengen und sind auf die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) angewiesen. Die stetige Verbesserung dieser Technologien ermöglicht es, Feinheiten in der Sprache besser zu erfassen und unterschiedliche Kontexte zu berücksichtigen.
In der akademischen Welt werden beispielsweise an der Johannes Kepler Universität Linz Studien zum Thema Sentiment-Analyse durchgeführt, die sich mit der automatisierten Erhebung von Emotionen aus Textdaten beschäftigen. Diese Forschungen tragen dazu bei, die theoretische Basis der Sentiment-Analyse zu erweitern und die Effektivität der Algorithmen in praktischen Anwendungen zu erhöhen.
Auf der individuellen Ebene treiben Experten wie Stefan van Wulfen von Vango AI dieses Feld voran. Van Wulfen, der Erfahrung in emotionaler KI und markenbasierten Analysen hat, ist ein Beispiel für Fachleute, die an der Schnittstelle von Marktforschung und KI arbeiten, um neuartige Lösungen für die Sentimentanalysen zu entwickeln.
Außerdem zeigt der Blick auf relevante Literatur wie „Schlüsselwerke der sozialwissenschaftlichen Klimaforschung“ auf, dass Sentimentanalysen in verschiedenen wissenschaftlichen Disziplinen angewandt werden, z.B. um die öffentliche Meinung zum Klimawandel zu analysieren. Sentiment-Analyse-Tools können zur Erfassung und Auswertung von Einstellungen in sozialen Medien und anderen Textquellen genutzt werden, um einen Einblick in das kollektive Bewusstsein zu erhalten und darauf aufbauend politische sowie gesellschaftliche Entscheidungsprozesse zu unterstützen.
Zusammenfassend lässt sich feststellen, dass die zukünftige Forschung und Entwicklung der Sentiment-Analyse geprägt sein wird von einer immer präziseren und kontextbezogeneren Interpretation von Textdaten, der Integration mit anderen Disziplinen und der Gestaltung einer transparenten und verantwortungsbewussten Technologieanwendung. Mit der weiteren Ausarbeitung von Methoden zur Gewährleistung der Ethik und Fairness von KI-Systemen, sowie der Erschließung neuer Anwendungsbereiche, wird die Sentiment-Analyse zunehmend als wichtiges Instrument in vielen Sektoren fungieren.
Potenzielle neue Anwendungsfelder
In der Zukunft der Sentiment-Analyse, einem Teilbereich der künstlichen Intelligenz und des maschinellen Lernens, zeichnen sich viele neue Anwendungsfelder ab. Unternehmen, Forschungsgruppen und IT-Entwickler suchen ständig nach Innovationen, um die Fähigkeiten der Sentiment-Analyse auszubauen und in neuen Kontexten nutzbar zu machen. In diesem Unterkapitel untersuchen wir mögliche neue Bereiche, in denen die Sentiment-Analyse eine signifikante Rolle spielen könnte.
Gesundheitswesen
Im Gesundheitswesen könnten Fortschritte in der Sentiment-Analyse dazu beitragen, den emotionalen Zustand von Patienten besser zu bewerten. Über soziale Medien und patientenbezogene Foren hinaus könnten Algorithmen für die Sentiment-Analyse dazu verwendet werden, in Echtzeit auf Änderungen der Stimmung oder des Verhaltens, die auf mögliche Erkrankungen hinweisen, aufmerksam zu machen. Ein weiterer möglicher Einsatzbereich ist die Analyse der Kommunikation zwischen Patienten und Gesundheitspersonal, um Missverständnisse und emotionale Bedürfnisse schneller zu erkennen und die Patientenbetreuung zu optimieren.
Bildung
In der Bildung könnten sentimentanalytische Werkzeuge Lehrkräfte dabei unterstützen, die Reaktionen von Schülern auf Lehrinhalte besser zu verstehen. Automatisierte Systeme könnten Diskussionen in Online-Lernplattformen auswerten, Stimmungen erkennen und anpassbare Feedback-Schleifen bereitstellen. Außerdem kann die Technologie dabei helfen, Bildungsinhalte so zu gestalten, dass sie emotional ansprechender und dadurch effektiver werden.
Finanzmärkte
Obwohl die Sentiment-Analyse bereits im Finanzsektor angewendet wird, um Marktstimmungen aus Nachrichtentexten und sozialen Medien abzuleiten, liegen hier noch ungenutzte Potenziale. Die nächste Generation von Sentiment-Analysewerkzeugen könnte durch die Verbesserung der Genauigkeit bei der Erkennung von Emotionen in Wirtschaftsnachrichten und Börsenkommentaren das Verständnis der Marktdynamik weiter vertiefen.
Politische Wissenschaft
In der politischen Analyse wird die Sentiment-Analyse zunehmend wichtiger, um die öffentliche Meinung und Stimmungen in sozialen Netzwerken zu bewerten. Zukünftige Anwendungen könnten die Vorhersage von Wahlentscheidungen, das Verständnis von politischen Kampagnen und deren Wirkung sowie die Früherkennung von politischen Spannungen oder Konflikten beinhalten.
Smart Cities und Urbane Planung
Smart Cities könnten vom Einsatz der Sentiment-Analyse profitieren, indem Bürgerfeedback und Stimmungen aus sozialen Medien zur städtischen Planung und zur Verbesserung öffentlicher Dienstleistungen herangezogen werden. Ziel könnte dabei sein, eine stärkere Einbeziehung und Berücksichtigung der Bewohner in Entwicklungsprozessen zu erzielen.
Kundendienst und CRM
Der Kundendienst könnte durch den Einsatz fortgeschrittener Sentiment-Analysetechniken revolutioniert werden. Bessere Einschätzungen von Kundenmeinungen und -stimmungen in Echtzeit könnten zu personalisierten Serviceerfahrungen führen. In Verbindung mit Customer-Relationship-Management-Systemen (CRM) könnten Emotionen von Kunden erkannt und entsprechende Marketingstrategien oder Produktanpassungen vorgenommen werden.
Gaming und Entertainment
Die Gaming- und Unterhaltungsindustrie könnte durch die Integration von Sentiment-Analyse-Funktionen in Spiele und Plattformen das Nutzererlebnis verbessern. Spieleentwickler könnten Spielerreaktionen analysieren und Spielinhalte dynamisch anpassen, um das Engagement zu erhöhen und personalisierte Erfahrungen zu schaffen.
Automobilindustrie
In der Automobilindustrie lässt sich die Sentiment-Analyse einsetzen, um Stimmungen und Meinungen über Marken, Modelle und Features in sozialen Netzwerken und Online-Foren zu analysieren. Dies könnte in der Produktentwicklung und im Marketing genutzt werden, um Trends zu erkennen und auf Kundenwünsche schneller zu reagieren.
Die aufgezeigten potenziellen Anwendungsfelder der Sentiment-Analyse sind nur ein kleiner Ausschnitt dessen, was in Zukunft möglich sein könnte. Mit der Fortentwicklung der künstlichen Intelligenz und der Erweiterung des Bereichs maschinelles Lernen dürften sich noch viele weitere innovative Anwendungsfelder eröffnen. Diese Entwicklung wird nicht nur die Entscheidungsfindung, sondern auch die Interaktion zwischen Mensch und Maschine grundlegend verändern und verbessern.
Perspektiven für die Sentiment-Analyse
Die Sentiment-Analyse, auch als Meinungsmining bekannt, hat sich im Laufe der Jahre rasant entwickelt und ist zu einem unverzichtbaren Werkzeug in verschiedenen Branchen geworden. Von der Überwachung der Markenreputation bis hin zur Produktentwicklung und Kundenbetreuung – die Fähigkeit, Stimmungen und Meinungen aus Textdaten herauszufiltern, ist für Unternehmen zu einem echten Wettbewerbsvorteil geworden. Mit den weiteren Fortschritten in der künstlichen Intelligenz (KI) und im maschinellen Lernen (ML) stehen wir nun an der Schwelle zu neuen, aufregenden Entwicklungen in der Sentiment-Analyse, die weitreichende Auswirkungen auf Forschung, Industrie und Gesellschaft haben werden.
Integration von Kontextbewusstsein
Eine der zentralen Herausforderungen in der Sentiment-Analyse ist das Verständnis des Kontextes, in dem eine Meinung geäußert wird. Zukünftige Entwicklungen werden sich voraussichtlich darauf konzentrieren, Modelle zu schaffen, die in der Lage sind, feinere Nuancen der Sprache, einschließlich Ironie, Sarkasmus und implizite Bedeutungen, korrekt zu interpretieren. Groß angelegte Sprachmodelle wie GPT (Generative Pretrained Transformer) entwickeln sich ständig weiter und bieten immer raffiniertere Möglichkeiten, subtile sprachliche Hinweise zu erkennen und so genauer auf den sentimentalen Gehalt eines Textes zu schließen.
Verarbeitung von Multimodal-Daten
Die Sentiment-Analyse wird sich nicht mehr nur auf Text beschränken. Der Trend geht hin zur Multimodal-Sentiment-Analyse, bei der Text, Bild, Video und Audio gleichzeitig analysiert werden, um ein umfassenderes Bild von den Emotionen und Meinungen einer Person zu erhalten. So können beispielsweise Gesichtsausdrücke und Stimmmodulationen in Videos dazu beitragen, die wahre Stimmung hinter den Worten zu erfassen.
Echtzeit-Analyse und Entscheidungsfindung
Mit der Verbesserung der Rechenleistung und Technologien wie Edge-Computing erwarten wir eine Zunahme der Echtzeit-Sentiment-Analyse. Für Unternehmen bedeutet dies, unmittelbar auf Kundenfeedback reagieren zu können, sei es durch automatisiertes Customer Relationship Management (CRM) oder durch die Einbindung von Sentiment-Daten in Echtzeit-Dashboards, die Unternehmensführung und Marketingstrategien informieren.
Ethik und Datenschutz
Da Sentiment-Analyse-Systeme immer tiefer in Privatsphäre eingreifen können, wird die Frage von Ethik und Datenschutz zunehmend wichtig. Es werden Standards und Vorschriften benötigt, um zu definieren, wie und in welchem Umfang Meinungsdaten erhoben und ausgewertet werden dürfen. Dabei müssen Persönlichkeitsrechte gewahrt und der sichere und verantwortungsbewusste Umgang mit sensiblen Daten gewährleistet werden.
Branchenspezifische Sentiment-Analyse
Obwohl Sentiment-Analyse-Tools bereits branchenübergreifend eingesetzt werden, werden zukünftige Systeme wahrscheinlich noch spezialisierter werden. Eine maßgeschneiderte Sentiment-Analyse für bestimmte Branchen wie das Gesundheitswesen, den Finanzsektor oder die Unterhaltungsindustrie könnte zu präziseren Einblicken und besserer Entscheidungsfindung führen.
Kombination mit anderen AI-Techniken
Die Kombination von Sentiment-Analyse-Techniken mit anderen KI-Methoden wie Predictive Analytics oder Natural Language Understanding (NLU) wird die Vorhersagekraft und Anwendungsbreite erweitern. Unternehmen könnten beispielsweise die Ergebnisse von Sentiment-Analysen verwenden, um Trends vorauszusagen oder das Verbraucherverhalten besser zu verstehen und zu beeinflussen.
Zusammenfassend lässt sich sagen, dass die Perspektiven für die Sentiment-Analyse äußerst vielversprechend sind. Mit der Weiterentwicklung von Technologien und Methoden werden unsere Fähigkeiten, sentimentale Informationen aus großen Datenmengen herauszufiltern und zu interpretieren, weiterhin sprunghaft zunehmen. Dies wird nicht nur die Art und Weise, wie Unternehmen mit ihren Kunden interagieren, revolutionieren, sondern auch neue Fortschritte in der sozialwissenschaftlichen Forschung und politischen Analyse fördern. Die Herausforderung besteht darin, diese Werkzeuge verantwortungsbewusst zu nutzen und sicherzustellen, dass sie zum Wohle aller und nicht zum Nachteil einzelner eingesetzt werden.

 Erhard RAINER
Erhard RAINER