Ich möchte anhand eines Beispiels zeigen, was die entscheidenden Faktoren sind, um große Tabellen performant abzufragen. In diesem Beispiel reden wir von 500 Millionen Zeilen. Ist bei weitem nicht die größte Tabelle, die mir in den letzten Jahren untergekommen ist, aber ein brauchbares Beispiel, um den möglichen Performance Gewinn zu demonstrieren.
Basisabfragen
Ausgangspunkt ist eine Abfrage, die die große Tabelle einschränkt, sodass nur die Datensätze angezeigt werden, die in der referenzierten Tabelle isLastScan = 1 sind.
Die Abfrage mit Where In ohne speziellen Index (außer dem PK) dauert ca. 2:40 min
Select Top 100 * from [dbo].[DiskContent] where scanid in (Select Scanid from dbo.Diskscan where isLastscan = 1)
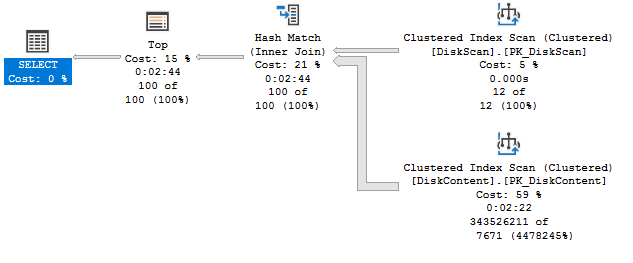
Die Abfrage mit inner join führt zum identischen Execution Plan mit gleicher Ausführzeit.
Select Top 100 dc.* from [dbo].[DiskContent] as dc inner join dbo.Diskscan as ds on dc.Scanid = ds.Scanid Where ds.isLastscan = 1
Zu selben Ergebnis – sowohl hinsichtlich Performance und Execution Plan ergibt auch die WHERE EXISTS Lösung:
Select Top 100 * from [dbo].[DiskContent] as dc where exists (Select 1 from dbo.Diskscan ds where dc.Scanid = ds.Scanid and ds.isLastscan = 1)
In diesem Beispiel hat es keinerlei Einfluss, ob man nur die PK-Spalte ausgibt oder ob man weitere Spalten ausgibt. Diese beiden Aussagen sind nicht generell, sondern auf diesen Fall bezogen. Grundsätzlich ist die Einschränkung auf einzelne Spalten ein Performance Booster und auch die 3 Methoden die Daten einzuschränken sind nicht immer gleich schnell. In diesem Fall gilt das aber nicht bzw. ist vernachlässigbar, da andere Dinge Performance kosten.
Partitionierung
Eine Partitionierung bringt in diesem Beispiel nur dann was, wenn die einzelnen Partitionen auf unterschiedlichen physischen Platten liegen. Liegen die Partitionen auf der selben physischen Platte, dann ist der Effekt vernachlässigbar.
Non-Clustered Index
Die nächste Überlegung wäre, die Spalte [ScanID] in der [dbo].[DiskContent] mit einen Non-Clustered Index zu versehen, dass – hoffentlich – die Filterung beschleunigt.
CREATE NONCLUSTERED INDEX nci_ScanID ON [dbo].[DiskContent] ([ScanID]);
Jetzt wird es interessant und – in meinen Augen – unerwartet. Durch diesen Index ändert sich rein gar nichts. Der Exeutionplan bleibt gleich, wenn wir mit * abfragen.
Select Top 100 * from [dbo].[DiskContent] where scanid in (Select Scanid from dbo.Diskscan where isLastscan = 1)

Anders sieht es aus, wenn man nur nach dem PK abfragt:
Select Top 100 DiskContentID from [dbo].[DiskContent] where scanid in (Select Scanid from dbo.Diskscan where isLastscan = 1)
In diesem Fall ändert sich der Execution Plan und die Abfrage wird wahnsinnig schnell. Execution Time: 00:00
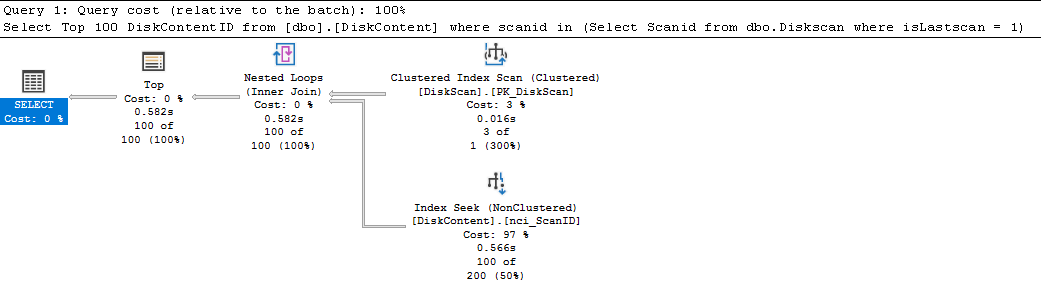
Aus dem Hash-Match (Inner Join) wurde ein Nested Loop (Inner Join). Weiters wurde aus dem Clustered Index Scan (Dauer: 2:22) auf den PK der Tabelle [dbo].[DiskContent] ein Index Seek auf den Non-Clustered Index (nci_ScanID) (Dauer: 0:00). Schauen wir uns das mal etwas im Detail an, woher der enorme Performance Gewinn kommt.
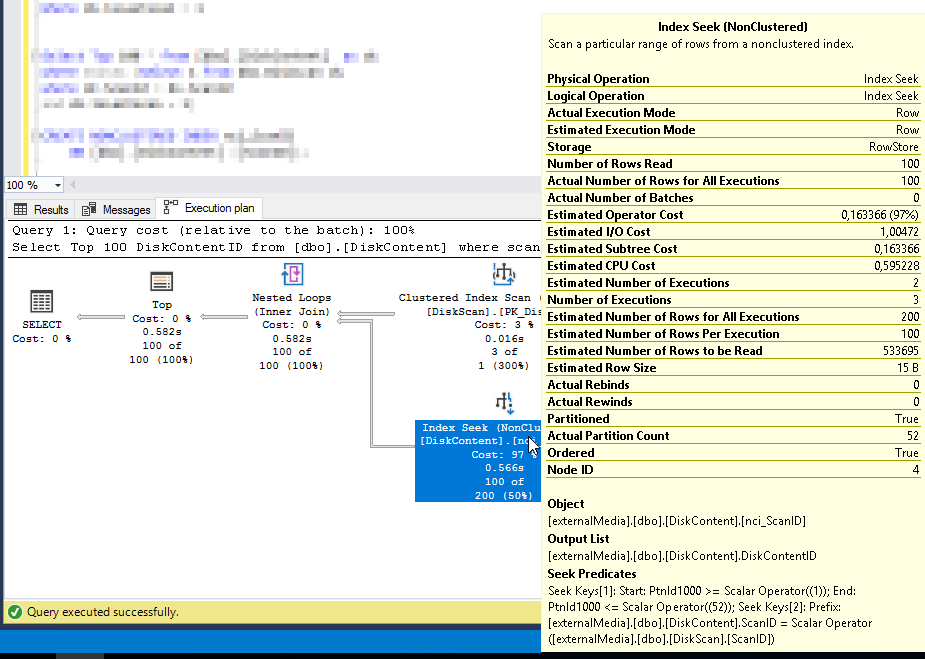
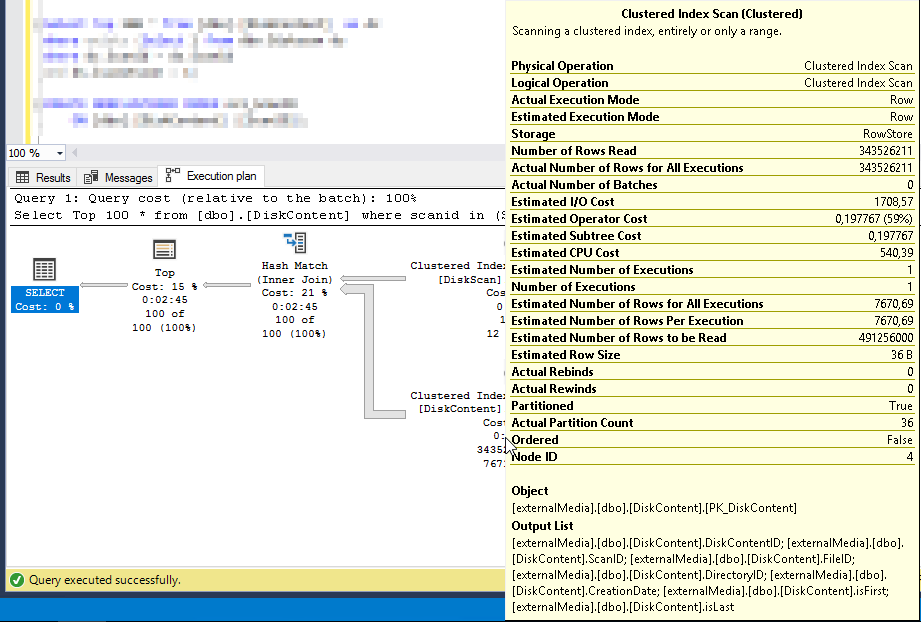
An dieser Stelle ein kurzer Exkurs:
- Index Seek – durchwandert den Indexbaum und folgt anschießend der Blattkonoten Liste, um alle Treffer zu finden.
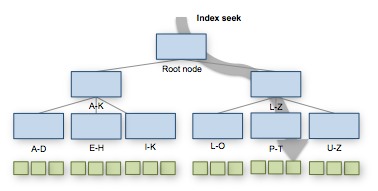
- Index Scan – liest den gesamten Index – alle Zeilen – in der Index Reihenfolge.
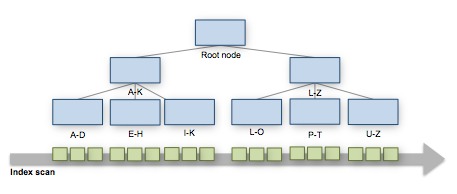
Das wirkt sich natürlich auch auf die Number of Rows Read (100 vs, 343.526.211) und somit auch auf die Zeit aus (0.556 s vs. 2:22 min)
Der zweiter Unterschied ist wie der Inner Join erfolgt:
- Hash-Match
- Nested Loop





 Erhard RAINER
Erhard RAINER