Interne Abarbeitung von Joins
Man unterscheidet bezüglicher der internen Abarbeitung (physical Join Operators) von Joins zwischen:
- Nested Loops
- Merge Join
- Hash Match

Exkurs: Auf der einen Seite gibt es logische Join Operationen, wie beispielsweise Inner-Join oder Left-Join; auf der anderen Seite gibt es physicalische Join Operatoren. Damit ist die interne Abarbeitung gemeint.
In Abhängigkeit der Verfügbarkeit von Indices werden die unterschiedlichen internen Verarbeitungsmethoden von Joins angewendet.
Nested Loop Joins
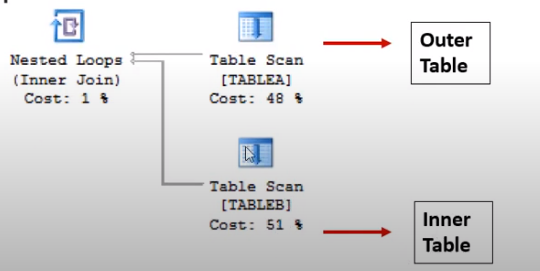
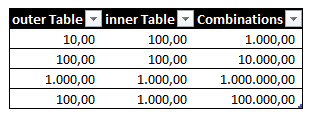
Beim Nested Loop Join wird jede Zeile der outer Table (in der Regel die kleinere Tabelle) mit der inner Table verglichen. Dieser Vorgang ist sehr speicherschonend (aber CPU lastig), aber skaliert sehr schlecht. Die Reihenfolge der Joins selbst spielt keine Rolle. Der Query Optimizer erkennt die kleinere Tabelle und macht sie zu „outer table“. Die besten Ergebnisse erziehlt man, wenn die outer table recht klein ist und die inner table sehr groß und optimalerweise einen Index hat. Sofern ein brauchbarer Index gesetzt ist, kann man sich zusätzliche Zeit sparen, da man statt einem Table Scan oder Index Scan auf einen Index Seek zurückgreifen kann, der die Anzahl der gelesenen Rows dramatisch reduziert.
Merge Join
Merge Join ist vermutlich der schnellste Join, da der Query Optimizier über jede Tabelle genau einmal iterieren muss. Voraussetzung ist aber, dass die Daten sortiert sind. Wenn man einen Merge Join vorfindet, besteht kein Optimierungspotential. Nur bei Tabellen mit bei denen bei beiden Tabellen Duplikate-Keys existieren, sind nicht so optimal. Es ist zwar auch in diesem Fall meist kein Optimierungspotential vorhanden, aber der Query Optimizer muss manchmal auch wieder zurück.
Hash Match
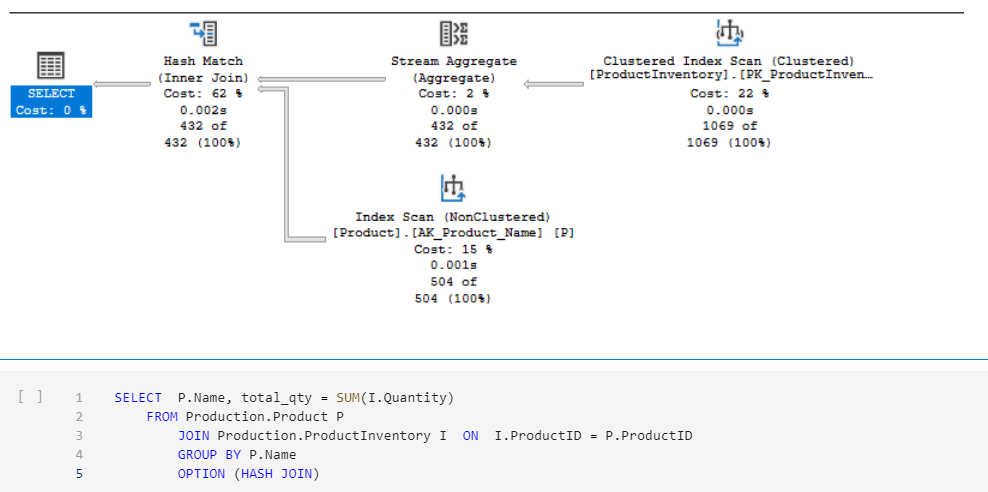
Hash Match Inner Joins werden verwendet um große Tabellen, die nicht sortiert sind (über einen Index) zu verbinden. Sie berechnen für jeden Wert einen Hash-Value um sie miteinander zu vergleichen. Dabei verwendet der Algorithmus den Arbeitspeicher und sofern dieser nicht ausreicht auch die TempDB. Durch die mögliche Verwendung der TempDB kann die Abfrage langsam werden. Der Vorteil dieser Methode ist, dass die beiden Tabellen auch sehr groß sein können. Weiters handelt es sich beim Hash Match um einen Blocking Join – dh. solange der komplette Join nicht abgeschlossen ist, bekommt der User kein Ergebnis. Hash Match Join sollten in Transaktionsdatenbanken vermieden werden. In Analysedatenbanken haben sie ihre Berechtigung.
Erzwingen eines bestimmten Joins
Mit den Execution Hints, kann man einen bestimmte Join erzwingen.
Links:
- Markus Winand – USE THE INDEX, LUKE (online-Buch zu indexbasierten SQL Tuning)
- Referenz zu logischen und physischen Showplanoperatoren
- Dinesh Asanka – Internals of Physical Join Operators (Nested Loops Join, Hash Match Join & Merge Join) in SQL Server
- Neeraj Prasad Sharma – Introduction to Nested Loop Joins in SQL Server
- Dmitry Piliugin – SQL Server – Hash Join Execution Internals
- Nested Loop, Merge and Hash Joins in SQL Server
- Steve Wort, Ross LoForte, Brian Knight – SQL Server Hash Join
- Thomas LeBlanc – Performance tuning – Nested and Merge SQL Loop with Execution Plans
- Jason Brimhall – Join Operations – Hash Match
- Difference between Nested Loop Join and Hash Join
- Difference between Nested Loop join and Sort Merge Join
- Difference between Hash Join and Sort Merge Join
- Marios Trivyzas – How we made joins 23 thousands times faster: Part one |
- manipulieren der Abfrage mittels Abfragehinweisen:





 Erhard RAINER
Erhard RAINER