T-SQL Search in Tables
- Table Scan – Lesen aller Elemente einer Tabelle
- Index Scan – empfängt alle Elemente des Index und filtert diese (nur Clustered Index)
- Index Seek – empfängt einzelne Elemente der Index (sowohl Clustered als auch Unclustered)
- RID Lookup (Heap) – schlägt ausgehend von einem Index Seek in der Tabelle direkt nach (Table Scan)
- Key Lookup (Clustered) – schlägt ausgehend von einem Index Seek in dem Clustered Index (Index Scan) nach.
Der Query Optimizer versucht als erstes einen Index Seek. Wenn kein brauchbarer Index gefunden wurde, dann macht der Query Optimizer einen Index Scan oder einen Table Scan, je nachdem ob ein Clustered Index vorliegt oder nicht. Werden neben den im Index integierten Spalten weitere Informationen benötigt, so holt die Query Engine diese mittels RID Lookup (Heap) oder Key Lookup (Cluster).
Table Scan
- Hierbei handelt es sich um den einfachsten Prozess. Die Query Engine beginnt beim physischen Beginn und arbeitete jede Zeile der Tabelle ab. Wenn eine Zeile dem Kriterium entspricht, wird sie den Ergebnis-Set hinzugefügt.
- Bei kleinen Tabellen ist es der einfachste und schnellste Weg, da die Query Engine in Memory laden kann. Bei größeren Tabellen funktioniert das nicht und es entsteht mehr IO und somit längere Query Zeiten, die diese Methode bei größeren Tabellen suboptimal machen.
- Ein Table Scan wird jedenfalls dann gemacht, wenn die Tabelle keinen WHERE-Clause hat und auch keinen Clustered Key (meist der Primary Key)
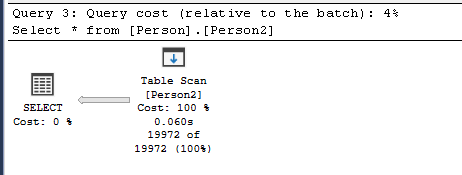
Index Scan
- Wenn ein Clustered Index (meist Primary Key) existiert und die Query die meisten oder alle Datensätze benötigt (ungeachtet davon ob es eine WHERE-Clause gibt) verwendet die Query Engine den Index Scan.
- Ein Index Scan funktioniert grundsätzlich sehr ähnlich einem Table Scan. Dh. Der Query Optimizer betrachtet die verfügbaren Indices und wählt den besten anhand der JOINS und WHERE Clauses.
- Wurde der richtige Index gefunden, arbeitet die Query Engine sich durch die Tree-Structure bis zu den Datensätzen, die den Kriterien entsprechen.
- Der Hauptunterschied zwischen einem Table Scan und einem Index Scan besteht darin, dass beim Index Scan anstelle des Heap der B-Tree durchsucht wird.
- Ein Index Scan ist etwas schneller als ein Table Scan aber wesentlich langsamer als ein Index Seek.
- Wird die gesamte Tabelle ausgegeben gibt es keinen Performance Unterschied zwischen Index Scan und Table Scan. Der einzigen Unterschied besteht darin, dass der Heap (Table Scan) oder der B-Tree (Index Scan) durchsucht wird.
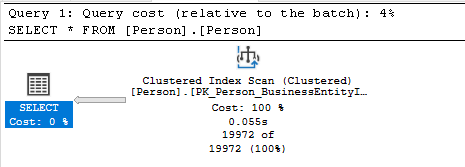
Wird eine Tabelle ohne jegliche Indices gefiltert, schlägt der Query Optimizer oftmals das Erstellen eines Non-Clustered Index vor. Man muss jedoch im Hinterkopf behalten, dass zuviele Clustered Indicies sich negativ auf das Schreiben (INSERT; UPDATE) auswirken, da der Index jeweils aktualisiert werden muss.

Index Seek
- Sofern die Such-Kriterien dem Index gut matchen, sodass er direkt zu einem bestimmten Punkt im Tree-Knotenpunkt sprichen kann. (insb. bei WHERE-Clause oder JOIN)
- Index Seeks sind die schnellste Möglichkeit in einer Datenbank zu suchen.
Den Index Seek gibt es beim Clustered Index (Primary Key)
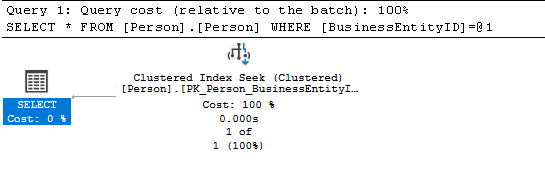
aber es gibt den Index Seek beim nonclustered index
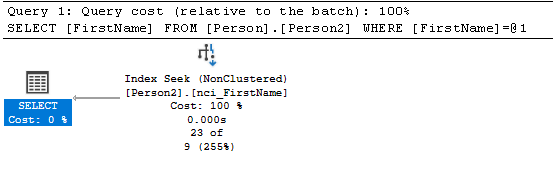
Damit der Index Seek in der Form funktioniert, müssen die angezeigten Spalten inkludiert sein. Dh. Man wählt den den Non-Clustered so, dass die mitausgegebenen Spalten als include im Index gespeichert werden.
CREATE NONCLUSTERED INDEX [nci_FirstName] ON [Person].[Person2] ( [FirstName] ASC ) INCLUDE([LastName]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO
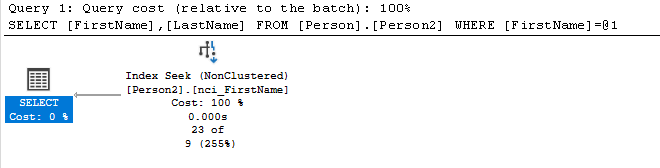
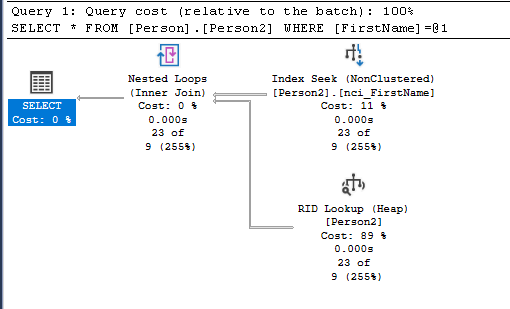
Wenn das nicht der Fall ist, dann erfolgt entweder ein RID Lookup oder ein Key Lookup.
Ein RID Lookup erfolgt, wenn die Query Engine ausgehend vom Index Seek auf die Tabelle ohne Index (Heap vgl. Table Scan) zugreift.
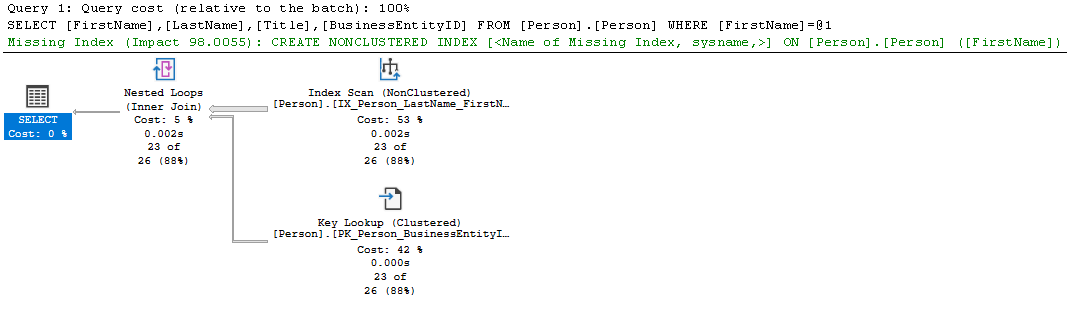
Erfolgt hingegen das Nachschlagen im Clustered Index (Index Scan), handelt es sich um ein Key Lookup.
Exkurs: Heap vs. B-Tree
Heap Table (Tabelle ohne clustered index)
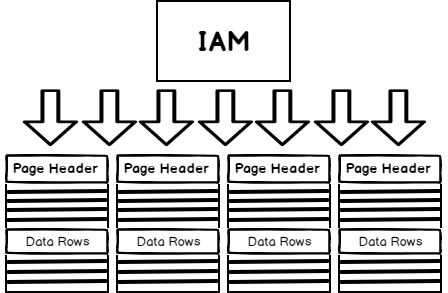
Ein Heap ist eine Tabelle ohne zugrundeliegende Ordnung. Es gibt keine Garantie beim Schreiben in eine Tabelle, in welcher Reihenfolge die Daten gespeichert werden. Ein Heap ist eine Index Allocation Map (IAM), welche zu allen Pages im Heap zeigt. Innerhalb des Heaps gibt es keine Organisation. Alles Lese-Vorgänge müssen mittels IAM alle Seiten (Pages) des Heap lesen.
B-Tree (Clustered index)
Die Idee hinter Clustered-Indizes ist es, den kompletten Inhalt einer Tabelle in der Datenstruktur eines B-Tree Indexes zu speichern. Wenn eine Tabelle einen Clustered-Index hat, bedeutet das, dass der Index die Tabelle ist. Clustered-Indizes haben den Vorteil, dass sie sehr schnelle Bereichs-Zugriffe ermöglichen. Das heißt, sie können Zeilen mit dem gleichen (oder ähnlichen) Clusterschlüssel sehr schnell liefern, weil sie physisch nebeneinander gespeichert sind – oft im selben Datenblock. Bei Clustered-Indizes muss man sich immer vor Auge halten, dass es keine separate Tabelle mehr gibt. Der Clustered-Index ist der primäre Tabellenspeicher—daher kann es auch nur einen pro Tabelle geben.
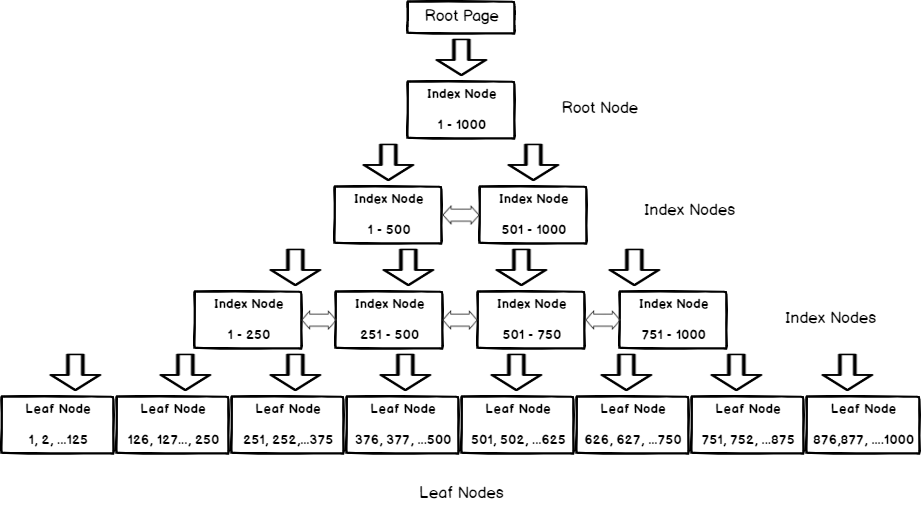
Ein Non-Clustered-Index beinhaltet hingegen nicht alle Tabellenspalten, sodass zusätzliche Leseoperationen verursacht werden um, die restlichen Spalten wenn nötig aus dem primären Tabellenspeicher zu laden. Dafür hat jede Zeile in einem Non-Clustered-Index einen Verweis auf ebendiese Zeile im primären Tabellenspeicher. In anderen Worten geht ein Non-Clustered-Index grundsätzlich mit dem Auflösen einer zusätzlichen Indirektion einher. Grundsätzlich habe ich gesagt. Es ist nämlich recht einfach diesen Aufwand zu vermeiden, indem man alle benötigen Spalten in den Non-Clustered-Index aufnimmt. Dadurch kann die Datenbank diese Daten direkt aus dem Index entnehmen und das Auflösen der zusätzlichen Indirektion einfach auslassen. Auch Non-Clustered-Indizes können also für Index-Only-Scans genutzt werden und damit ebenso schnell wie Clustered-Indizes sein.
Links
- Pinal Dave – SQL SERVER – Index Seek Vs. Index Scan (Table Scan)
- Greg Robidoux – Index Scans and Table Scans
- Markus Winand – Operationen in SQL Server Ausführungsplänen
- Pankaj Patel – The Complete Reference – Table Scan, Index Scan, And Index Seek
- Brenz Ozar – Expensive Key Lookups
- Ed Pollack – Clustered Index vs. Heap in SQL Server
- Mayank Shukla – NonClustered Index Structure



 Erhard RAINER
Erhard RAINER