Einführung
Begriffsdefinitionen im Kontext von Machine Learning
Machine Learning ist ein faszinierender und schnell wachsender Bereich der Künstlichen Intelligenz (KI), der auf den Prinzipien beruht, dass Systeme von Daten lernen und sich verbessern können, ohne explizit programmiert zu werden. Hier sind einige zentrale Begriffe und Konzepte, die im Bereich des Machine Learning von Bedeutung sind:
- Algorithmus: Ein Machine Learning Algorithmus ist eine Reihe von Regeln oder Anweisungen, die einem Computer dabei helfen, ein spezifisches Problem zu lösen oder eine bestimmte Aufgabe zu erledigen. Es gibt eine Vielzahl von ML-Algorithmen, jeder mit seinen eigenen Stärken, Schwächen und Anwendungsgebieten.
- Modell: Ein Modell ist das spezifische Ergebnis des Trainings eines ML-Algorithmus auf einem Datensatz. Es repräsentiert die erlernten Muster und Beziehungen innerhalb der Daten und kann verwendet werden, um Vorhersagen zu treffen oder Entscheidungen zu treffen.
- Training: Training ist der Prozess, bei dem ein ML-Algorithmus Daten verwendet, um ein Modell zu erstellen. Während des Trainingsprozesses „lernt“ der Algorithmus von den Daten und passt seine Parameter an, um die Genauigkeit seiner Vorhersagen oder Entscheidungen zu verbessern.
- Test: Nachdem ein Modell trainiert wurde, wird es auf einem separaten Datensatz getestet, um zu sehen, wie gut es in der Lage ist, korrekte Vorhersagen oder Entscheidungen zu treffen. Dieser Datensatz wurde nicht für das Training verwendet und hilft dabei, die Leistung des Modells in „realen“ Bedingungen zu evaluieren.
- Features: Features sind individuelle messbare Eigenschaften oder Charakteristika von Phänomenen, die analysiert werden sollen. Im Kontext des ML sind Features die Variablen, die ein Modell verwendet, um Vorhersagen zu treffen.
- Labels: In überwachten Lernszenarien sind Labels die „richtigen Antworten“, die das Modell während des Trainings zu lernen versucht. Zum Beispiel könnte in einem Klassifikationsproblem jedes Beispiel in den Trainingsdaten mit einem Label versehen sein, das angibt, zu welcher Klasse es gehört.
- Überwachtes Lernen: Überwachtes Lernen ist eine Art von ML, bei der Algorithmen auf einem Datensatz trainiert werden, der sowohl die Eingabevariablen (Features) als auch die korrekten Ausgaben (Labels) enthält. Das Ziel ist, ein Modell zu entwickeln, das in der Lage ist, die richtige Ausgabe für neue, nicht gekennzeichnete Daten vorherzusagen.
- Unüberwachtes Lernen: Im Gegensatz dazu ist unüberwachtes Lernen eine Art von ML, bei der Algorithmen auf Daten ohne Labels trainiert werden. Die Algorithmen versuchen, die zugrunde liegende Struktur der Daten zu verstehen und Muster aufzudecken.
- Verstärkungslernen: Verstärkungslernen ist ein Bereich des ML, bei dem ein Agent lernt, wie er sich in einer Umgebung verhalten soll, um eine Belohnung zu maximieren. Der Agent trifft Entscheidungen und erhält Feedback in Form von Belohnungen oder Strafen, um sein Verhalten anzupassen.
Diese Begriffe und Konzepte bilden die Grundlage für das Verständnis von Machine Learning und seine breiten Anwendungsgebiete in der modernen Technologie.
Abgrenzungen: Machine Learning, Künstliche Intelligenz, Business Intelligence und Big Data
Die Begriffe Machine Learning (ML), Künstliche Intelligenz (KI), Business Intelligence (BI) und Big Data sind in der modernen Technologie- und Geschäftswelt allgegenwärtig, doch ihre Bedeutungen und Anwendungen können sich erheblich unterscheiden. Hier ist eine klare Abgrenzung zwischen diesen Begriffen:
- Künstliche Intelligenz (KI): KI ist ein übergeordneter Bereich, der sich darauf konzentriert, Maschinen und Computerprogrammen die Fähigkeit zu verleihen, menschenähnliche Intelligenz und Verhaltensweisen zu demonstrieren. Dazu gehören Lernen, Schlussfolgern, Problemlösen, Wahrnehmung und Sprachverständnis. ML ist eine Unterdisziplin der KI, die speziell darauf abzielt, Maschinen das Lernen aus Daten zu ermöglichen, um bessere Vorhersagen oder Entscheidungen zu treffen.
- Business Intelligence (BI): BI bezieht sich auf Technologien, Anwendungen und Praktiken zur Sammlung, Integration, Analyse und Präsentation von Geschäftsdaten. Ziel ist es, fundierte Geschäftsentscheidungen zu treffen. Im Gegensatz zu ML, das auf die Erstellung von Modellen zur Vorhersage zukünftiger Ereignisse abzielt, konzentriert sich BI eher auf die Bereitstellung von Einblicken in aktuelle und historische Daten.
- Big Data: Big Data bezieht sich auf extrem große Datenmengen, die so umfangreich sind, dass traditionelle Datenverarbeitungswerkzeuge sie nicht effizient handhaben können. Big Data kann strukturiert, unstrukturiert oder semi-strukturiert sein und wird oft durch die drei Vs charakterisiert: Volumen (Menge an Daten), Vielfalt (verschiedene Arten von Daten) und Geschwindigkeit (die Geschwindigkeit, mit der neue Daten generiert und verarbeitet werden). ML und Big Data sind eng miteinander verknüpft, da ML-Algorithmen oft eingesetzt werden, um Muster in großen Datenmengen zu erkennen und wertvolle Einblicke zu gewinnen.
Die Verbindung zwischen diesen Begriffen liegt in ihrer gemeinsamen Zielsetzung, die Informationsverarbeitung zu verbessern und bessere Entscheidungen zu ermöglichen, sei es durch menschenähnliche Intelligenz, durch datengetriebene Einsichten oder durch die Entdeckung von Mustern in riesigen Datenmengen.
Geschichte und Entwicklung von Machine Learning
- 1950s:
- 1950: Alan Turing veröffentlicht einen Artikel, in dem er die Frage „Können Maschinen denken?“ stellt und den Turing-Test vorschlägt.
- 1957: Frank Rosenblatt erfand den Perzeptron-Algorithmus, den Vorläufer moderner neuronaler Netzwerke.
- 1960s:
- 1967: Der k-Nearest Neighbors Algorithmus (k-NN) wird eingeführt, ein einfacher, instanzbasierter Lernalgorithmus.
- 1970s:
- 1979: Die Entwicklung des Konzepts der Entscheidungsbaum-Algorithmen beginnt, die den Grundstein für viele moderne ML-Algorithmen legen.
- 1980s:
- 1986: Rumelhart, Hinton und Williams veröffentlichten Backpropagation, eine Methode zum Trainieren von mehrschichtigen neuronalen Netzwerken.
- 1990s:
- 1995: Cortes und Vapnik stellen den Support-Vektor-Maschinen-Algorithmus vor, eine mächtige Methode für Klassifikationsaufgaben.
- 1997: IBM’s Deep Blue besiegt den Schachweltmeister Garry Kasparov, ein historischer Meilenstein in der KI- und ML-Geschichte.
- 2000s:
- 2006: Geoffrey Hinton prägt den Begriff „Deep Learning“ für Algorithmen mit vielen Schichten von Neuronen (tiefen neuronalen Netzwerken).
- 2010s:
- 2012: AlexNet, ein tiefes künstliches neuronales Netzwerk, gewinnt den ImageNet-Wettbewerb und löst einen Boom im Deep Learning aus.
- 2014: Ian Goodfellow et al. stellen Generative Adversarial Networks (GANs) vor, ein neues Framework für das Training von generativen Modellen.
- 2015: Residual Networks (ResNets) werden eingeführt und setzen neue Standards in Deep Learning.
- 2020s:
- 2020: OpenAI veröffentlicht GPT-3, das bisher größte und leistungsfähigste Sprachmodell.
- 2021: Fortschritte in Transformer-Architekturen und Selbstüberwachtem Lernen führen zu weiteren Durchbrüchen in der ML-Forschung.
Die Entwicklung von Machine Learning ist eine fortlaufende Reise, die durch Zusammenarbeit und Innovationen in der breiten Gemeinschaft von Wissenschaftlern, Ingenieuren und Praktikern vorangetrieben wird. Diese Zeitlinie bietet einen Überblick über einige der wichtigsten Meilensteine und Entwicklungen, die den heutigen Stand des Machine Learning geprägt haben.
Grundlagen
- Mathematische Grundlagen
- Lineare Algebra
- Statistik und Wahrscheinlichkeit
- Optimierung
- Daten
- Datensammlung
- Datenbereinigung und -verarbeitung
Arten von Machine Learning
Eine kurze Einführung
Die Welt des Machine Learning (ML) ist faszinierend und bietet eine reiche Palette an Techniken und Methoden, die darauf abzielen, Maschinen das Lernen aus Daten zu ermöglichen. Von der Vorhersage von Aktienkursen bis hin zur Erkennung von Gesichtern in einer Menge – die Anwendungsfälle sind endlos. Dieser Artikel wird die vier Hauptarten des Machine Learning untersuchen: Supervised Learning, Unsupervised Learning, Deep Learning und Reinforcement Learning, und beleuchtet, wo jede Art am besten eingesetzt wird.
Supervised Learning (Überwachtes Lernen):
Supervised Learning ist, wie ein Lehrer im Klassenzimmer, wo die Modelle aus einem gelabelten Datensatz lernen. Hier sind die Datenpunkte mit den korrekten Antworten beschriftet, und der Algorithmus lernt, Vorhersagen zu machen.
Anwendungen:
- Vorhersage von kontinuierlichen Werten wie Hauspreisen (Regression).
- Klassifikation von E-Mails als Spam oder Nicht-Spam.
Unsupervised Learning (Unüberwachtes Lernen):
Im Gegensatz zum überwachten Lernen gibt es hier keine Labels. Unsupervised Learning Algorithmen versuchen, die zugrundeliegende Struktur in den Daten zu finden.
Anwendungen:
- Gruppierung von Kunden in verschiedene Segmente (Clustering).
- Reduzierung der Dimensionalität von Daten für die Visualisierung.
Deep Learning:
Deep Learning ist eine Unterklasse des Machine Learning, die tiefe neuronale Netzwerke verwendet, um komplexe Muster in Daten zu erkennen.
Anwendungen:
- Bild- und Spracherkennung.
- Übersetzung von Text in Echtzeit.
Reinforcement Learning (Verstärkungslernen):
Hier lernt der Agent, durch Interaktion mit der Umgebung, optimale Verhaltensweisen zu entwickeln, um eine Belohnung zu maximieren.
Anwendungen:
- Training von Computern, um Spiele zu spielen und zu gewinnen.
- Entwicklung autonomer Fahrzeuge.
Gegenüberstellung
- Supervised vs. Unsupervised: Supervised Learning benötigt gelabelte Daten, während Unsupervised Learning mit ungelabelten Daten arbeitet.
- Supervised/Unsupervised vs. Deep Learning: Deep Learning kann als Erweiterung des Supervised und Unsupervised Learning betrachtet werden, aber mit der Fähigkeit, komplexe Muster zu erkennen.
- Deep Learning vs. Reinforcement Learning: Deep Learning ist datengetrieben, während Reinforcement Learning durch Interaktion mit der Umgebung lernt.
Wann welche Methode verwenden?
- Supervised Learning ist ideal für Anwendungen, bei denen klare Labels vorhanden sind und Vorhersagen getroffen werden müssen.
- Unsupervised Learning eignet sich für Datenexploration und das Finden von unbekannten Mustern in Daten.
- Deep Learning ist mächtig bei großen Datenmengen und komplexen Aufgaben wie Bild- und Spracherkennung.
- Reinforcement Learning ist die Methode der Wahl für Aufgaben, bei denen Entscheidungen in einer interaktiven Umgebung getroffen werden müssen.
Supervised Learning
Supervised Learning, oder überwachtes Lernen, ist eine der zentralen Techniken im Bereich des Machine Learning, bei der ein Algorithmus aus einem gelabelten Datensatz lernt. In diesem Datensatz sind die richtigen Antworten, auch bekannt als Labels, für jeden Datenpunkt bereits bekannt. Der erste Schritt im Supervised Learning ist das Training des Modells, wobei der Algorithmus den gelabelten Datensatz verwendet, um Muster zu erkennen und Beziehungen zwischen den Eingabedaten (Features) und den Ausgabedaten (Labels) herzustellen. Durch den Trainingsprozess lernt der Algorithmus, Vorhersagen zu treffen oder Klassifikationen vorzunehmen, und passt seine Gewichtungen an, um die Genauigkeit der Vorhersagen zu verbessern. Nachdem das Modell trainiert wurde, wird es auf einem separaten Testdatensatz evaluiert, um zu sehen, wie gut es in der Lage ist, korrekte Vorhersagen oder Klassifikationen auf neuen, zuvor nicht gesehenen Daten vorzunehmen.
Die Leistung des Modells wird anhand bestimmter Metriken wie Genauigkeit, Präzision und Recall bewertet. Supervised Learning eignet sich besonders gut für Anwendungen, bei denen die Vorhersage spezifischer Ausgaben auf der Grundlage von historischen Daten von entscheidender Bedeutung ist. Beispiele für überwachtes Lernen sind die Vorhersage von Aktienkursen, die Klassifikation von E-Mails als Spam oder Nicht-Spam, und die Vorhersage von Immobilienpreisen. Durch das Verständnis und die Anwendung von Supervised Learning können Entwickler und Datenwissenschaftler Modelle erstellen, die wertvolle Vorhersagen und Einsichten liefern, um informierte Entscheidungen zu treffen. Supervised Learning bildet oft den Ausgangspunkt für die Einführung in die Welt des Machine Learning und dient als Grundlage für den weiteren Einsatz und die Exploration anderer ML-Techniken.
Allgemeines
- Grundlagen des Supervised Learning:
- Lernprozess: Der Lernprozess im überwachten Lernen besteht aus zwei Phasen: Training und Testing. Im Training wird der Algorithmus mit einem gelabelten Datensatz gefüttert, um ein Modell zu erstellen. Im Testing wird die Leistung des Modells anhand neuer Daten evaluiert.
- Labels: Labels sind die „Ziel“- oder Ausgabevariablen in einem gelabelten Datensatz. Sie repräsentieren die „richtige Antwort“ für jeden Datenpunkt.
- Features: Features sind die Eingabevariablen, die das Modell nutzt, um Vorhersagen zu treffen.
- Hauptkategorien des Supervised Learning
- Regression: Bei Regressionsproblemen ist das Ziel, eine kontinuierliche Zielvariable vorherzusagen. Beispiele könnten die Vorhersage von Hauspreisen oder Aktienkursen sein.
- Klassifikation: Bei Klassifikationsproblemen ist das Ziel, die Kategorie eines Datenpunkts vorherzusagen. Beispiele sind die Erkennung von Spam-E-Mails oder die Klassifikation von Bildern.
- Evaluierung und Performance-Metriken
- Confusion Matrix: Eine Tabelle, die die Anzahl der korrekten und falschen Vorhersagen für jede Klasse zeigt.
- Genauigkeit, Präzision und Recall: Metriken zur Bewertung der Leistung eines Klassifikationsmodells.
- Mean Absolute Error, Mean Squared Error: Metriken zur Bewertung der Leistung eines Regressionsmodells.
- Herausforderungen und Best Practice
- Overfitting und Underfitting: Probleme, die auftreten, wenn ein Modell zu komplex oder zu einfach für die Daten ist.
- Kreuzvalidierung: Eine Technik zur Evaluierung der Leistung eines Modells unter verschiedenen Datensplits.
- Regularisierung: Eine Methode zur Vermeidung von Overfitting durch Bestrafung von komplexen Modellen.
Algorithmen des Supervised Learnings
- Lineare Regression: Ein einfacher Algorithmus zur Vorhersage einer kontinuierlichen Zielvariablen basierend auf einer oder mehreren Eingabevariablen.
- Logistische Regression: Obwohl der Name irreführend ist, wird die logistische Regression für binäre Klassifikationsprobleme verwendet.
- Entscheidungsbäume und Random Forests: Entscheidungsbäume teilen den Datensatz in Untergruppen, um Vorhersagen zu treffen, während Random Forests viele Entscheidungsbäume kombinieren, um die Genauigkeit zu verbessern.
- Support Vector Machines (SVM): SVMs sind mächtige Algorithmen für Klassifikations-, Regressions- und Ausreißerdetektionsaufgaben.
- K-Nearest Neighbors (K-NN): Ein einfacher, instanzbasierter Lernalgorithmus, der die Ausgabe basierend auf der Mehrheitsabstimmung seiner Nachbarn vorhersagt.
- Neuronale Netzwerke: Neuronale Netzwerke können für komplexe Klassifikations- und Regressionsprobleme verwendet werden und sind die Grundlage für Deep Learning.
Unsupervised Learning
Unsupervised Learning, oder unüberwachtes Lernen, ist eine weitere wichtige Kategorie im Bereich des Machine Learning, bei der Algorithmen auf einem ungelabelten Datensatz trainiert werden. Im Gegensatz zum Supervised Learning sind die richtigen Antworten oder Labels im Datensatz nicht bekannt, und der Algorithmus arbeitet selbstständig, um Strukturen und Muster in den Daten zu entdecken. Der erste Schritt im Unsupervised Learning ist die Auswahl eines geeigneten Algorithmus für die gegebene Aufgabe. Einmal ausgewählt, wird der Algorithmus auf den Datensatz angewendet, um Beziehungen zwischen den Datenpunkten zu erkennen. Dies kann durch Gruppierung ähnlicher Datenpunkte (Clustering) oder durch Finden von Anomalien und Ausreißern in den Daten erfolgen.
Ein beliebtes Beispiel für Unsupervised Learning ist der k-means Algorithmus, der Datenpunkte in k verschiedene Cluster aufteilt basierend auf ihren Eigenschaften. Ein weiteres Beispiel ist die Hauptkomponentenanalyse (PCA), die oft verwendet wird, um die Dimensionalität der Daten zu reduzieren und die wichtigsten Merkmale zu identifizieren. Unsupervised Learning eignet sich besonders für explorative Datenanalyse, Anomalieerkennung und das Verständnis komplexer Datenstrukturen. Es ermöglicht auch das Entdecken unbekannter Muster in Daten, die bei gelabelten Ansätzen möglicherweise übersehen werden.
Da keine vorherige Kennzeichnung der Daten erforderlich ist, ist Unsupervised Learning oft flexibler und anpassbarer an neue Arten von Daten und Aufgaben. Es stellt eine kraftvolle Methode dar, um Erkenntnisse aus Daten zu gewinnen, wenn die richtigen Antworten nicht bekannt sind oder wenn die Datenstruktur komplex und unbekannt ist. Unsupervised Learning erweitert die Möglichkeiten des Machine Learning über das hinaus, was mit gelabelten Daten allein möglich ist, und ermöglicht eine tiefere, unvoreingenommene Exploration der inhärenten Strukturen innerhalb von Datensätzen.
Allgemeines
- Grundlagen des Unsupervised Learning:
- Lernprozess: Der Lernprozess beginnt mit dem Einlesen eines ungelabelten Datensatzes. Der Algorithmus arbeitet dann selbstständig, um Muster, Gruppierungen oder Anomalien in den Daten zu entdecken.
- Ziel: Das Ziel ist es, die zugrundeliegende Struktur der Daten zu entdecken und zu verstehen, um nützliche Erkenntnisse zu gewinnen oder die Daten für weitere Analysen vorzubereiten.
- Hauptkategorien des Unsupervised Learning
- Clustering: Clustering-Algorithmen gruppieren Datenpunkte basierend auf ihren Ähnlichkeiten in verschiedene Cluster, ohne dass vorherige Labels vorhanden sind.
- Dimensionality Reduction: Methoden zur Reduzierung der Dimensionalität zielen darauf ab, die Anzahl der Features in einem Datensatz zu reduzieren, während möglichst viel von der ursprünglichen Information erhalten bleibt.
- Association: Association Learning-Methoden identifizieren Regeln, die beschreiben, wie bestimmte Datenattribute miteinander in Beziehung stehen.
- Evaluierung im Unsupervised Learning
- Silhouette Score: Eine Metrik zur Bewertung der Qualität der Clusterbildung.
- Explained Variance: Eine Metrik, die den Anteil der Datenvarianz erklärt, der durch die reduzierten Dimensionen erhalten bleibt.
- Herausforderungen und Anwendungen
- Herausforderungen: Die Hauptherausforderung im Unsupervised Learning besteht darin, die richtige Anzahl von Clustern oder die richtige Dimensionalitätsreduktion zu wählen.
- Anwendungen: Unsupervised Learning wird in vielen Bereichen eingesetzt, von der Kundensegmentierung über die Anomalieerkennung bis hin zur Empfehlungssystemen.
Algorithmen des Unsupervised Learnings
- K-Means Clustering: Ein einfacher und effektiver Algorithmus zum Gruppieren von Daten in k verschiedene Cluster basierend auf ihrem Mittelwert.
- Principal Component Analysis (PCA): Eine Technik zur Reduzierung der Dimensionalität durch Identifizierung der wichtigsten Eigenschaften, die die größte Varianz in den Daten erklären.
- Apriori: Ein Algorithmus zur Identifizierung häufiger Itemsets und Assoziationsregeln in Transaktionsdaten.
Deep Learning
Deep Learning, eine Unterklasse des Machine Learning, zeichnet sich durch den Einsatz tiefer neuronaler Netzwerke aus, welche aus vielen Schichten bestehen, um komplexe Muster in großen Datenmengen zu erkennen und zu lernen. Der erste Schritt im Deep Learning ist das Design des neuronalen Netzwerks, bei dem die Anzahl der Schichten und Knotenpunkte festgelegt wird, sowie die Art des Netzwerks, beispielsweise konvolutionelle oder rekurrente Netzwerke. Nach dem Design wird das Netzwerk mit einem großen Datensatz trainiert, oft mit Millionen oder sogar Milliarden von Datenpunkten, um die Gewichtungen der Verbindungen zwischen den Knotenpunkten zu optimieren.
Während des Trainingsprozesses werden die Daten durch das Netzwerk geführt, von Schicht zu Schicht, wobei jede Schicht bestimmte Merkmale der Daten lernt und extrahiert. Durch die Anwendung von Aktivierungsfunktionen und anderen Techniken kann das Netzwerk nicht-lineare Beziehungen in den Daten erfassen und verstehen. Nach dem Training wird das Netzwerk auf neuen Daten getestet, um seine Leistung und Genauigkeit bei der Vorhersage oder Klassifikation zu bewerten. Deep Learning eignet sich besonders für Aufgaben, bei denen traditionelle Machine Learning-Methoden an ihre Grenzen stoßen, wie Bild- und Spracherkennung, maschinelles Übersetzen und viele andere Anwendungen, die von einer hohen Datenkomplexität geprägt sind.
Die Fähigkeit, komplexe Muster und Beziehungen in Daten zu erkennen, macht Deep Learning zu einem mächtigen Werkzeug für viele moderne KI-Anwendungen. Durch den Einsatz von Hardware-Beschleunigung und optimierten Trainingstechniken können Deep Learning-Modelle in akzeptabler Zeit trainiert und eingesetzt werden, trotz der immensen Rechenleistung, die sie erfordern. Die Fortschritte im Deep Learning in den letzten Jahren haben den Weg für viele Innovationen im Bereich der künstlichen Intelligenz geebnet und die Tür für die Entwicklung von Systemen geöffnet, die in der Lage sind, Aufgaben zu erledigen, die bisher als exklusiv menschlich galten.
Allgemeines
- Grundlagen des Deep Learning
- Neuronale Netzwerke: Neuronale Netzwerke sind die Grundlage des Deep Learning. Sie bestehen aus Knotenpunkten (Neuronen), die in Schichten organisiert sind und Informationen von einer Schicht zur nächsten weiterleiten.
- Aktivierungsfunktionen: Aktivierungsfunktionen sind entscheidend für neuronale Netzwerke, da sie nicht-lineare Beziehungen im Daten erfassen können.
- Backpropagation: Backpropagation ist ein Algorithmus zum effizienten Trainieren von neuronalen Netzwerken durch Berechnung von Gradienten des Verlusts bezüglich der Gewichtungen.
- Training und Evaluation
- Datensätze und Datenvorbereitung: Große, gut vorbereitete Datensätze sind entscheidend für das erfolgreiche Training von Deep Learning-Modellen.
- Overfitting und Regularisierung: Overfitting ist eine häufige Herausforderung im Deep Learning, und Regularisierungstechniken können helfen, die Modellkomplexität zu kontrollieren.
- Performance-Metriken: Verschiedene Metriken wie Genauigkeit, Präzision und Recall werden verwendet, um die Leistung von Deep Learning-Modellen zu bewerten.
- Anwendungen und Herausforderungen
- Anwendungen: Deep Learning findet Anwendung in vielen Bereichen, von der Bild- und Spracherkennung über die maschinelle Übersetzung bis hin zur autonomen Fahrzeugsteuerung.
- Herausforderungen: Trotz der Fortschritte gibt es noch Herausforderungen wie die Interpretierbarkeit von Modellen und den Bedarf an großen Datenmengen und Rechenressourcen.
spezialisierte Netzwerkarchitekturen
- Convolutional Neural Networks (CNNs): CNNs sind speziell für die Bildanalyse entwickelt und können lokale Muster in Daten erkennen, indem sie Faltungen über die Eingabedaten anwenden.
- Recurrent Neural Networks (RNNs): RNNs sind für sequentielle Daten wie Zeitreihen oder Text konzipiert und können Informationen über die Zeit hinweg behalten.
- Generative Adversarial Networks (GANs): GANs bestehen aus zwei Netzwerken, einem Generator und einem Diskriminator, die gegeneinander trainiert werden, um neue Daten zu generieren, die ähnlich wie echte Daten aussehen.
Reinforcement Learning
Reinforcement Learning, oder Verstärkungslernen, ist ein Bereich des Machine Learning, in dem ein Agent lernt, wie er Entscheidungen trifft, um eine bestimmte Belohnung zu maximieren, während er mit einer Umgebung interagiert. Der Lernprozess beginnt mit dem Agenten, der eine Aktion in der Umgebung ausführt. Nach der Ausführung der Aktion erhält der Agent eine Rückmeldung von der Umgebung in Form einer Belohnung, die angibt, wie gut die Aktion war. Die zentrale Idee ist, dass der Agent im Laufe der Zeit lernt, welche Aktionen in welchen Zuständen zu höheren Belohnungen führen.
Im Gegensatz zu Supervised Learning, wo das Modell von gelabelten Daten lernt, oder Unsupervised Learning, wo das Modell Strukturen in den Daten erkundet, basiert das Verstärkungslernen auf der Trial-and-Error-Methode. Der Agent macht Erfahrungen, indem er Aktionen ausführt, die Rückmeldungen beobachtet und seine Strategie anpasst, um in Zukunft bessere Belohnungen zu erhalten. Eine zentrale Komponente des Reinforcement Learning ist die Politik, eine Strategie, die dem Agenten sagt, welche Aktion er in einem bestimmten Zustand ausführen soll.
Ein bekanntes Konzept im Reinforcement Learning ist der Trade-off zwischen Exploration und Exploitation. Exploration bedeutet, dass der Agent neue Aktionen ausprobiert, um mehr über die Umgebung zu erfahren, während Exploitation bedeutet, dass der Agent die Aktionen ausführt, von denen er glaubt, dass sie die höchste Belohnung bringen. Algorithmen wie Q-Learning und Deep Q Networks (DQNs) sind populäre Methoden im Reinforcement Learning, die dem Agenten helfen, die optimale Politik zu lernen.
Reinforcement Learning findet Anwendung in einer Vielzahl von Gebieten, wie zum Beispiel beim Training von Computern, um Spiele zu spielen, in der Robotik, um Roboter zu steuern, oder in der Finanzwelt, um Handelsstrategien zu entwickeln. Durch die Fähigkeit, komplexe Entscheidungsprozesse zu lernen und zu optimieren, bietet Reinforcement Learning einen spannenden Weg zur Entwicklung autonomer Systeme, die in der Lage sind, in komplexen, dynamischen Umgebungen zu agieren und zu lernen.
- Grundlagen des RL
- Agent und Umgebung: Im RL interagiert ein Agent mit einer Umgebung, führt Aktionen aus und erhält Belohnungen oder Strafen basierend auf den Ergebnissen der Aktionen.
- Belohnung und Politik: Die Belohnung signalisiert dem Agenten, wie gut eine Aktion war, während die Politik die Strategie des Agenten definiert, um Aktionen in verschiedenen Zuständen zu wählen.
- Zustände und Aktionen: Der Zustandsraum repräsentiert alle möglichen Zustände der Umgebung, während der Aktionsraum alle möglichen Aktionen repräsentiert, die der Agent ausführen kann.
- Kernkonzepte im Reinforcement Learning
- Markov Decision Processes (MDPs): MDPs bilden den mathematischen Rahmen für RL, indem sie die Dynamik der Interaktion zwischen Agent und Umgebung definieren.
- Exploration vs. Exploitation: Exploration bezieht sich auf das Ausprobieren neuer Aktionen, während Exploitation das Ausnutzen bekannter Informationen zur Maximierung der Belohnung bedeutet.
- Discounted Future Rewards: Dieses Konzept hilft dem Agenten, die zukünftigen Belohnungen abzuschätzen und den langfristigen Nutzen von Aktionen zu bewerten.
- Beliebte Algorithmen im Reinforcement Learning
- Q-Learning: Q-Learning ist ein wertebasiertes RL-Verfahren, das den Wert jeder Aktion in jedem Zustand schätzt, um die optimale Politik zu lernen.
- Deep Q Networks (DQNs): DQNs kombinieren Q-Learning mit Deep Learning, um die Q-Wert-Funktion in komplexen, hochdimensionalen Umgebungen zu approximieren.
- Training und Evaluation
- Training: Training in RL beinhaltet das Sammeln von Erfahrungen durch Interaktion mit der Umgebung und das Aktualisieren der Politik des Agenten oder der Wertefunktion.
- Evaluation: Die Leistung des RL-Agenten wird oft durch die gesammelten Belohnungen über die Zeit und die Fähigkeit, die optimale Politik zu lernen, bewertet.
- Anwendungen und Herausforderungen
- Anwendungen: RL findet Anwendung in vielen Bereichen wie Spielen, Robotik, Finanzwesen und Gesundheitswesen.
- Herausforderungen: Herausforderungen im RL umfassen die Notwendigkeit großer Datenmengen, die Exploration-Exploitation-Abwägung und die Generalisierung über verschiedene Aufgaben.
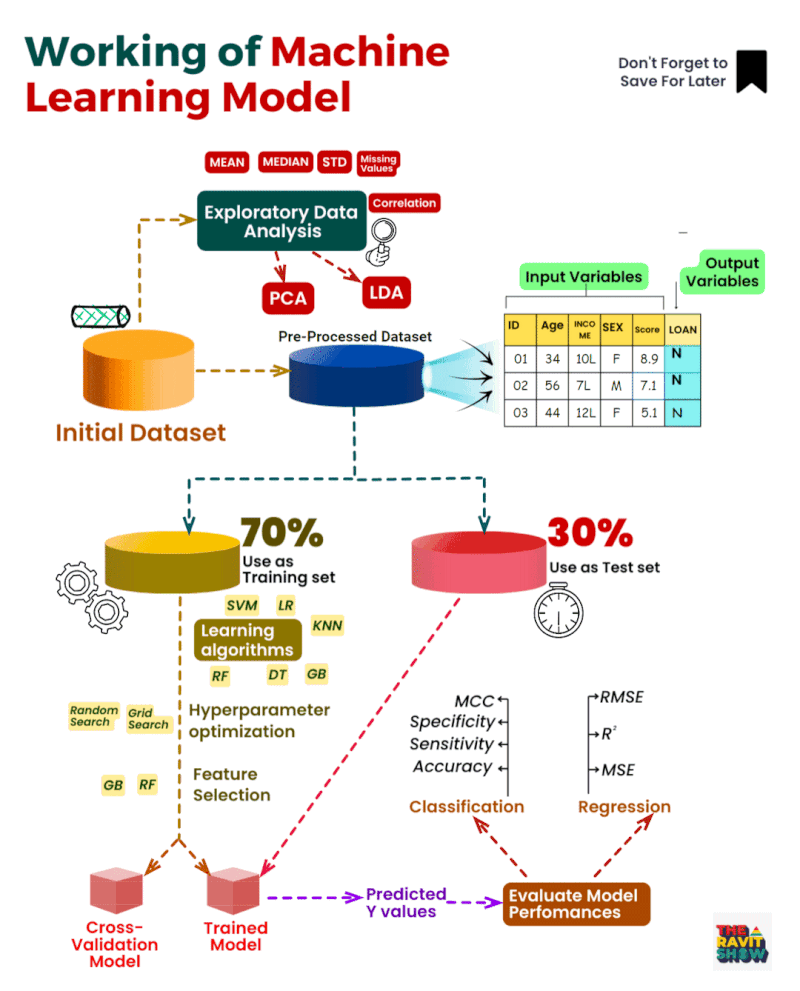
Working of Machine Learning Model
Der Ablauf eines maschinellen Lernmodells teilt sich in 3 Hauptabschnitte:
- Datensammlung: Im ersten Schritt werden die Daten gesammelt, aus denen das Modell lernen soll. Diese Daten können aus verschiedenen Quellen stammen, z. B. aus Sensoren, Umfragen oder Transaktionsdaten.
- Datenvorverarbeitung: Im zweiten Schritt werden die Daten vorverarbeitet, um sie für das Modell geeignet zu machen. Dazu gehören Aufgaben wie das Bereinigen von Datenfehlern, das Auffüllen fehlender Werte und die Normalisierung der Daten.
- Modelltraining: Im dritten Schritt wird das Modell mit den vorverarbeiteten Daten trainiert. Dabei lernt das Modell, die Beziehungen zwischen den Eingabedaten und den Ausgabedaten zu erkennen.
Ethik und Gesellschaft
n einer Welt, die sich rasch weiterentwickelt und zunehmend von Technologie durchdrungen ist, stehen Ethik und gesellschaftliche Verantwortung im Mittelpunkt zahlreicher Diskussionen. Die Auswirkungen technologischer Fortschritte auf die Gesellschaft sind sowohl ermächtigend als auch herausfordernd. In diesem Beitrag werden wir einige der ethischen Herausforderungen untersuchen, die sich aus der Schnittstelle zwischen Technologie und Gesellschaft ergeben.
- Datenschutz und Überwachung: Mit der zunehmenden Digitalisierung des Alltags wird der Schutz personenbezogener Daten immer wichtiger. Die Sammlung und Analyse von Daten durch Unternehmen und Regierungen werfen ernsthafte Datenschutzbedenken auf. Die Überwachung, ob durch staatliche Akteure oder durch private Unternehmen, stellt eine ernsthafte Bedrohung für die Privatsphäre dar.
- Künstliche Intelligenz und Bias: Künstliche Intelligenz (KI) hat das Potenzial, unsere Gesellschaft zu transformieren, birgt aber auch Risiken. Ein Hauptanliegen ist der algorithmische Bias, der entsteht, wenn KI-Systeme voreingenommene Entscheidungen treffen, basierend auf den Daten, mit denen sie trainiert wurden.
- Automatisierung und Arbeitsplatzverlust: Die Automatisierung von Arbeitsplätzen durch Roboter und KI könnte die Art und Weise, wie wir arbeiten, radikal verändern. Sie birgt jedoch auch das Risiko des Arbeitsplatzverlusts und der sozialen Ungleichheit, wenn nicht alle Bevölkerungsgruppen gleichberechtigten Zugang zu neuen Arbeitsmöglichkeiten haben.
- Technologieabhängigkeit: Die steigende Abhängigkeit von Technologie kann sowohl individuelle als auch gesellschaftliche Herausforderungen mit sich bringen. Dies reicht von der digitalen Kluft bis hin zur Sorge um die mentale Gesundheit in einer immer vernetzteren Welt.
- Digitale Desinformation: Die Verbreitung von Falschinformationen und Desinformation in digitalen Medien ist eine ernsthafte Bedrohung für die Demokratie und die gesellschaftliche Kohäsion. Die Bekämpfung digitaler Desinformation, während die Meinungsfreiheit gewahrt bleibt, ist eine komplexe Herausforderung.
- Zugang und digitale Kluft: Nicht alle haben gleichen Zugang zu digitalen Ressourcen und Bildungsmöglichkeiten, was die digitale Kluft verschärft. Es ist entscheidend, dass die Vorteile der Technologie allen zugänglich gemacht werden, um eine inklusivere Gesellschaft zu fördern.
- Verantwortung und Regulierung: Die Frage der Verantwortung, insbesondere bei autonomen Systemen oder KI-Anwendungen, bleibt eine zentrale Herausforderung. Die Entwicklung von Regulierungsrahmen, die sowohl Innovation fördern als auch ethische Standards wahren, ist von entscheidender Bedeutung.
Vorlesung zum Machine Learning in Python
Linkliste
- Online-Kurse:
- Bücher:
- „Pattern Recognition and Machine Learning“ von Christopher Bishop
- „Deep Learning“ von Ian Goodfellow, Yoshua Bengio und Aaron Courville
- „The Hundred-Page Machine Learning Book“ von Andriy Burkov
- „Python Machine Learning“ von Sebastian Raschka und Vahid Mirjalili
- „Introduction to Machine Learning with Python“ von Andreas C. Müller & Sarah Guido
- „Machine Learning: A Probabilistic Perspective“ von Kevin P. Murphy
- „Machine Learning: The Art and Science of Algorithms that Make Sense of Data“ von Peter Flach
- „Understanding Machine Learning: From Theory to Algorithms“ von Shai Shalev-Shwartz und Shai Ben-David
- „Practical Statistics for Data Scientists“ von Andrew Bruce und Peter Bruce
- „Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow“ von Aurélien Géron
- „Machine Learning: A Bayesian and Optimization Perspective“ von Sergios Theodoridis
- „Introduction to the Theory of Statistical Inference“ von Hannelore Liero und Silvelyn Zwanzig
- „Deep Learning for Computer Vision“ von Rajalingappaa Shanmugamani
- „Reinforcement Learning: An Introduction“ von Richard S. Sutton und Andrew G. Barto
- „Data Mining: Practical Machine Learning Tools and Techniques“ von Ian H. Witten, Eibe Frank, Mark A. Hall, und Christopher J. Pal
- „Probabilistic Graphical Models: Principles and Techniques“ von Daphne Koller und Nir Friedman
- Websites:
- Akademische Papiere und Journalartikel:
- Frameworks und Bibliotheken:
- Communities:
- Youtube Kanäle:
- Blogs
- Toolkits und Plattformen
- Konferenzen
- Workshops und Bootcamps

 Erhard RAINER
Erhard RAINER