
Vorbemerkungen
Die gesammelten Informationen in diesem Blog-Beitrag sind das Ergebnis meiner Recherchen im Rahmen meiner Seminararbeit für das Fach „Menschenrechte und Künstliche Intelligenz“ im Doktoratsstudium der Rechtswissenschaften. Der vorliegende Text ist jedoch keine 1:1 Version der Seminararbeit, da diese gekürzt und in englischer Sprache verfasst wurde. Die vollständige Seminararbeit ist unten verlinkt, jedoch durch ein Passwort geschützt.
Abstract
Hintergrund: Text-zu-Bild-KI-Systeme haben das Potenzial, in einer Vielzahl von Anwendungen, von der Unterhaltung bis zur Bildung, eingesetzt zu werden. Allerdings können diese Systeme auch Vorurteile und Stereotypen, die in den Trainingsdaten vorhanden sind, verstärken. Dies kann zu problematischen Ergebnissen führen, insbesondere wenn diese Systeme in sensiblen Kontexten eingesetzt werden. Daher ist es wichtig, diese Vorurteile zu erkennen und zu mindern.
Methoden: In dieser Studie haben wir den „Real-World-Ansatz“ angewendet, um Vorurteile in Text-zu-Bild-KI-Systemen zu untersuchen und zu mindern. Dieser Ansatz sieht KI als Spiegel der Gesellschaft und betont die Notwendigkeit, gesellschaftliche Ungleichheiten auf gesellschaftlicher Ebene anzugehen, anstatt KI-Systeme dazu zu missbrauchen, gesellschaftliche Missstände zu vertuschen. Dieser Ansatz zur Vermeidung von Stereotypen in Text-zu-Bild-KIs besteht darin, in die bestehenden Datenmodelle statistische Informationen einzuarbeiten, die der Realität entsprechen. Dazu benötigen die Datenmodelle statistische Informationen über die realen Verteilungen bestimmter geographischer Attribute.
Ergebnisse: Meine Ergebnisse zeigen, dass der „Real-World-Ansatz“ dazu beitragen kann, die Darstellung von Vielfalt und Inklusivität in Text-zu-Bild-KI-Systemen zu verbessern. Durch die Einbeziehung von statistischen Informationen, die der Realität entsprechen, in die Datenmodelle konnte ich geographische Unterschiede abbilden und eine vielfältigere Darstellung von Menschen fördern. Diese Ergebnisse unterstreichen die Bedeutung von realitätsnahen Trainingsdaten und Nutzerfeedback bei der Reduzierung von Vorurteilen in KI-Systemen.
wissenschaftlicher Artikel
Einleitung
Text-zu-Bild-Künstliche Intelligenz (KI) hat sich als ein revolutionäres Werkzeug in einer Vielzahl von Anwendungen etabliert, von der Generierung von Bildinhalten basierend auf natürlichen Sprachbeschreibungen bis hin zur Verbesserung der Mensch-Maschine-Interaktion. Diese Technologie hat das Potenzial, die Art und Weise, wie wir mit Computern interagieren und Informationen visualisieren, grundlegend zu verändern.
Trotz ihrer beeindruckenden Fähigkeiten bergen Text-zu-Bild-KI-Systeme jedoch auch Herausforderungen und Risiken, insbesondere in Bezug auf die Verstärkung von Vorurteilen und Stereotypen. Da diese Systeme auf Daten trainiert werden, die oft unausgewogene oder voreingenommene Darstellungen von Geschlecht, Rasse, Alter und anderen demografischen Merkmalen enthalten, können sie diese Ungleichheiten in ihren Ausgaben reproduzieren. Dies kann zu einer Verstärkung bestehender Ungleichheiten und Stereotypen führen und die Wahrnehmung verzerren, dass diese verzerrten Demografien normal oder wünschenswert sind.
In der vorliegenden Studie untersuchen wir die Auswirkungen von Vorurteilen und Stereotypen in Text-zu-Bild-KI-Systemen, insbesondere in den Modellen Midjourney, DALL-E2 und Stable Diffusion. Diese Modelle wurden aufgrund ihrer aktuellen Relevanz und Leistungsfähigkeit in Forschung und Anwendung ausgewählt und repräsentieren den aktuellen Stand der Technik in der Text-zu-Bild-Generierung.
Die zentrale Forschungsfrage lautet: „Wie können Text-zu-Bild-KI-Systeme so gestaltet und genutzt werden, dass sie Vielfalt und Inklusivität fördern, während sie die Verstärkung schädlicher Vorurteile und Stereotypen vermeiden?“ Um diese Frage zu beantworten, stellen wir uns mehrere Unterfragen, darunter: Welche Text-zu-Bild-KI-Modelle sind relevant für die Betrachtung? Halten sich Text-zu-Bild-KIs an bestimmte Stereotypen? Was ist der aktuelle Stand der Forschung in diesem Bereich? Welche Konzepte gibt es zur Vermeidung von Stereotypen in Text-zu-Bild?
Die technische Umsetzung unseres Ansatzes besteht darin, statistische Informationen über die Verteilung von Alter, Geschlecht und Ethnie einzelner Berufsgruppen in die bestehenden Datenmodelle von Text-zu-Bild-KIs einzuarbeiten. Diese Informationen könnten als mehrdimensionales Verteilungsgebilde dargestellt werden, und anhand dieser Verteilung könnten dann Bilder generiert werden, die die realen Verteilungen berücksichtigen.
Unsere Studie trägt dazu bei, das Bewusstsein für die potenziellen Auswirkungen von Vorurteilen und Stereotypen in KI-Systemen zu schärfen und bietet Einblicke in mögliche Ansätze zur Förderung von Vielfalt und Inklusivität in der Text-zu-Bild-Generierung. Durch die Untersuchung der Modelle Midjourney, DALL-E2 und Stable Diffusion beleuchten wir die Herausforderungen und Möglichkeiten, die sich in diesem Bereich ergeben. Darüber hinaus liefern wir konkrete Vorschläge, wie diese Systeme verbessert werden können, um eine gerechtere und inklusivere Darstellung aller demografischen Gruppen in den generierten Bildern zu gewährleisten. Schließlich hoffen wir, dass unsere Arbeit dazu beiträgt, eine Diskussion über ethische Standards und Richtlinien in der Entwicklung und Anwendung von Text-zu-Bild-KI-Systemen anzuregen.
Wissenschaftliche Fragestellung (englisch)
- Research Question: How can text-to-image artificial intelligence systems be designed and used in a way that promotes diversity and inclusivity, while avoiding the perpetuation of harmful biases and stereotypes?
- sub-questions:
- Which text-to-image AI models are relevant for consideration?
- Do text-to-image AIs adhere to certain stereotypes?
- What is the current state of research in this field?
- What concepts exist for avoiding stereotypes in text-to-image?
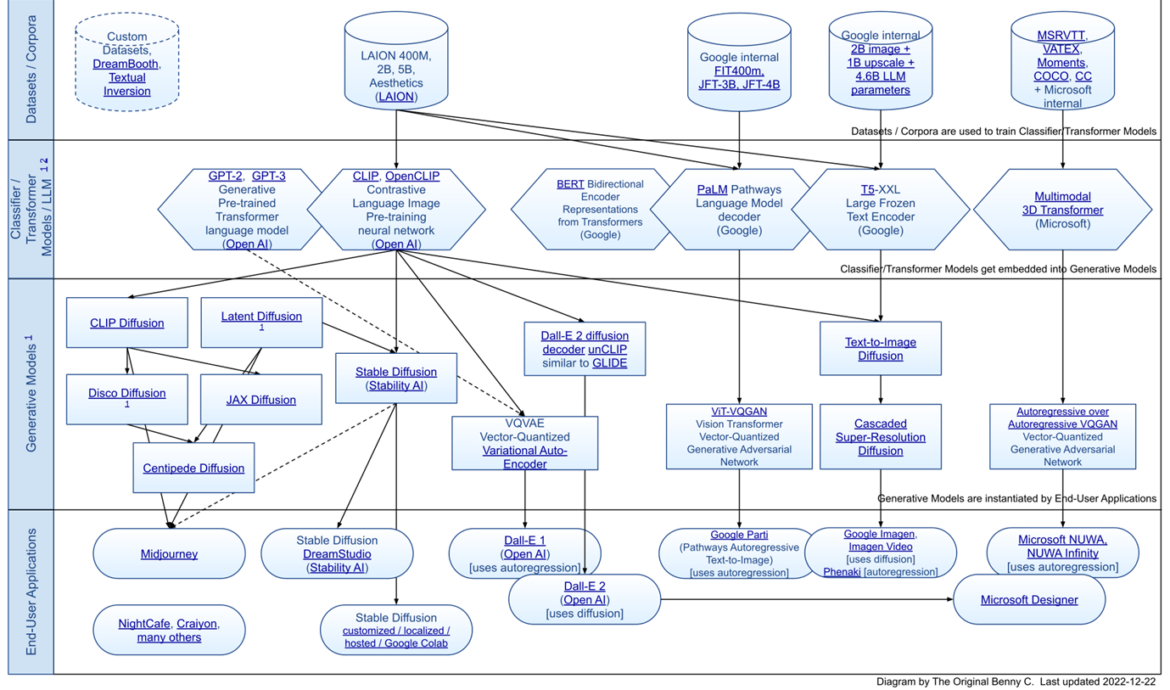
Auswahl der betrachteten Text-to-Image KIs
Nachdem wir die Bedeutung und die Herausforderungen von Text-zu-Bild-KI-Systemen sowie unseren Ansatz zur Förderung von Vielfalt und Inklusivität in diesen Systemen dargelegt haben, möchten wir nun auf die spezifischen Modelle eingehen, die wir in unserer Studie untersuchen. Die Wahl der Text-zu-Bild Generative Modelle Midjourney, DALL-E2 und Stable Diffusion für diese Untersuchung basiert auf ihrer aktuellen Relevanz und Leistungsfähigkeit in der Forschung und Anwendung. Diese Modelle repräsentieren den aktuellen Stand der Technik in der Text-zu-Bild Generierung und bieten eine breite Palette von Möglichkeiten zur Erzeugung von Bildern aus Texteingaben.
Das Modell Midjourney ist bekannt für seine Fähigkeit, komplexe und detaillierte Bilder aus Texteingaben zu erzeugen. Es nutzt eine Kombination aus verschiedenen Techniken, darunter Transformer-Architekturen und Generative Adversarial Networks (GANs), um hochwertige Bilder zu erzeugen, die die in der Texteingabe beschriebenen Szenen genau darstellen.
DALL-E2 ist eine Weiterentwicklung des ursprünglichen DALL-E Modells von OpenAI und bietet verbesserte Fähigkeiten zur Erzeugung von Bildern aus Texteingaben. Es nutzt eine Transformer-basierte Architektur und ist in der Lage, eine Vielzahl von Bildern zu erzeugen, die verschiedene Aspekte der in der Texteingabe beschriebenen Szenen darstellen.
Stable Diffusion ist ein weiteres prominentes Modell in diesem Bereich, das sich durch seine Fähigkeit auszeichnet, Bilder von hoher Qualität und Detailgenauigkeit aus Texteingaben zu erzeugen. Es nutzt eine Technik namens Diffusion Models, die auf der Idee basiert, ein Bild durch einen Prozess der schrittweisen Veränderung von einem zufälligen Ausgangspunkt zu erzeugen.
Die Wahl dieser Modelle für diese Untersuchung ist sinnvoll, da sie eine breite Palette von Techniken und Ansätzen zur Text-zu-Bild Generierung repräsentieren und somit einen umfassenden Einblick in den aktuellen Stand der Technik in diesem Bereich bieten. Darüber hinaus haben diese Modelle in vorherigen Studien gezeigt, dass sie in der Lage sind, Bilder von hoher Qualität und Detailgenauigkeit zu erzeugen, was sie zu idealen Kandidaten für die Untersuchung von Fragen im Zusammenhang mit Vorurteilen und Stereotypen in der Text-zu-Bild Generierung macht.
Eine aktuelle Studie von Ali et al. (2023) analysierte die Darstellung von demografischen Realitäten in der chirurgischen Profession durch diese drei Modelle. Die Studie fand heraus, dass alle Modelle stereotype Verhaltensweisen aufwiesen, wobei Midjourney und Stable Diffusion über 98% der Chirurgen als weiße Männer darstellten, während DALL-E2 genauere Demografien darstellte. Diese Ergebnisse unterstreichen die Notwendigkeit, die Auswirkungen von Vorurteilen und Stereotypen in diesen Modellen weiter zu untersuchen und Strategien zur Minderung dieser Probleme zu entwickeln.
| Modell | DALL-E | Midjourney | Stable Diffusion |
| Created by | OpenAI | Midjourney Inc. | Stability AI, Compvis Group, LMU München |
| Published | 2021 | 2022 | 2022 |
| Classifier | GPT-2,GPT-3 | CLIP, OpenCLIP | CLIP, OpenCLIP |
| Generative Model | VQ-VAE-2 | Not specified | Latent Diffusion Model (LDM) |
| Data Set | Web-Scrapping | Not specified | LAION-5B (5 Billion Picture-Text-Sets) |
| Access | OpenAI (API) | Discord-Bot | Different (GPU, 8GB VRAM) |
Datenbasis von Text-to-Image Modellen
Nachdem wir nun die spezifischen Modelle vorgestellt haben, die wir in unserer Studie untersuchen, und ihre jeweiligen Stärken und Schwächen hervorgehoben haben, möchten wir auf einen weiteren wichtigen Aspekt eingehen, der die Leistung und Fairness von Text-zu-Bild-KI-Systemen maßgeblich beeinflusst: die Datenbasis.
Die Qualität und Vielfalt der Datenbasis sind entscheidend für die Leistungsfähigkeit und Fairness von Text-to-Image-Modellen. Diese Modelle lernen aus den Daten, die ihnen zur Verfügung gestellt werden, und reproduzieren die Muster, die sie in diesen Daten finden. Daher ist es von entscheidender Bedeutung, dass die Datenbasis repräsentativ, vielfältig und frei von Vorurteilen ist.
Es gibt verschiedene Arten von Datenbasen, die für Text-to-Image-Modelle verwendet werden können. Eine gängige Methode zur Datenerfassung ist das Web-Scraping. Web-Scraping ist eine Technik, bei der automatisierte Skripte verwendet werden, um große Mengen an Daten aus dem Internet zu extrahieren. Diese Methode ist besonders nützlich, um eine große Menge an Text- und Bildmaterial zu sammeln, das dann zur Schulung von Text-to-Image-Modellen verwendet werden kann. Allerdings kann Web-Scraping auch zu Problemen führen, da die gesammelten Daten oft unstrukturiert sind und möglicherweise Vorurteile und Stereotypen enthalten, die im Internet weit verbreitet sind.
Ein spezifisches Beispiel für eine Datenbasis, die für Text-to-Image-Modelle verwendet wird, ist LAION-5B. LAION-5B (https://laion.ai/blog/laion-5b/) ist eine große Datenbasis, die aus dem Internet gescraped wurde und sowohl Text- als auch Bildmaterial enthält. Diese Datenbasis ist besonders nützlich für Text-to-Image-Modelle, da sie eine große Menge an vielfältigen Daten bietet, die das Modell lernen kann. Allerdings kann auch LAION-5B Vorurteile und Stereotypen enthalten, da sie aus dem Internet gescraped wurde.
Es ist wichtig zu betonen, dass die Datenbasis eines Text-to-Image-Modells einen erheblichen Einfluss auf die Leistung und Fairness des Modells hat. Wenn die Datenbasis Vorurteile und Stereotypen enthält, wird das Modell diese wahrscheinlich lernen und reproduzieren. Daher ist es entscheidend, bei der Erstellung der Datenbasis sorgfältig vorzugehen und sicherzustellen, dass sie so vielfältig und repräsentativ wie möglich ist.
Die Rolle von Bildunterschriften in der Datenbasis von KI-Modellen und ihre Beiträge zur Stereotypenbildung
Die Bedeutung einer sorgfältig ausgewählten und vielfältigen Datenbasis für die Leistung und Fairness von Text-zu-Bild-KI-Modellen kann nicht genug betont werden. Daher ist es entscheidend, bei der Erstellung der Datenbasis sorgfältig vorzugehen und sicherzustellen, dass sie so vielfältig und repräsentativ wie möglich ist. Mit diesem Verständnis wollen wir nun einen spezifischen Aspekt der Datenbasis beleuchten, der eine entscheidende Rolle spielt: die Bildunterschriften.
Bildunterschriften spielen eine entscheidende Rolle in der Datenbasis von Text-zu-Bild KI-Modellen. Sie dienen als primäre Informationsquelle, die den Modellen hilft, die Beziehung zwischen Text und visuellen Inhalten zu verstehen und zu lernen. Diese Beziehung ist entscheidend für die Fähigkeit der Modelle, genaue und relevante Bilder aus Textbeschreibungen zu generieren.
Es wird jedoch deutlich, dass die Art und Weise, wie Bildunterschriften in der Datenbasis verwendet werden, erheblich zur Bildung von Stereotypen und Vorurteilen beitragen kann. Insbesondere kann die Verwendung von Bildunterschriften, die Stereotypen und Vorurteile enthalten, dazu führen, dass diese Verzerrungen in den generierten Bildern der Modelle reproduziert werden.
In der Arbeit von Bianchi et al. (2023) wird beispielsweise gezeigt, dass Text-zu-Bild-Generierungssysteme, die auf stereotypen Bildunterschriften trainiert wurden, dazu neigen, Bilder zu erzeugen, die diese Stereotypen widerspiegeln. Dies deutet darauf hin, dass die Verwendung von stereotypen Bildunterschriften in der Datenbasis zu einer Verstärkung dieser Stereotypen in den generierten Bildern führen kann.
Ähnlich argumentieren Zhou et al. (2023) in ihrer Arbeit, dass die Verwendung von Bildunterschriften, die Vorurteile enthalten, dazu führen kann, dass diese Vorurteile in den generierten Bildern der Modelle reproduziert werden. Sie stellen fest, dass alle von ihnen untersuchten Modelle in allen Kategorien von Vorurteilen stereotypische Verhaltensweisen aufweisen, was darauf hindeutet, dass diese Vorurteile in der Datenbasis der Modelle verankert sind.
Diese Befunde unterstreichen die Notwendigkeit, bei der Erstellung der Datenbasis für Text-zu-Bild KI-Modelle sorgfältig auf die Verwendung von Bildunterschriften zu achten. Es ist wichtig, sicherzustellen, dass die Bildunterschriften frei von Stereotypen und Vorurteilen sind, um zu verhindern, dass diese Verzerrungen in den generierten Bildern reproduziert werden. Darüber hinaus ist es wichtig, Methoden zur Erkennung und Minderung von Stereotypen und Vorurteilen in der Datenbasis zu entwickeln und anzuwenden, um die Fairness und Genauigkeit der Modelle zu verbessern.
Stereotpyes in text-to-image AI‘s
Die Erkenntnisse, die wir bisher über die Rolle von Bildunterschriften und die Notwendigkeit einer sorgfältigen Gestaltung der Datenbasis gesammelt haben, führen uns zu einem weiteren wichtigen Aspekt unserer Untersuchung: der Analyse von Stereotypen in Text-zu-Bild KI-Systemen. Es ist nicht nur wichtig, Stereotypen und Vorurteile in der Datenbasis zu erkennen und zu mindern, sondern auch zu verstehen, wie diese Verzerrungen in den Ausgaben der Modelle manifestiert werden. Daher wenden wir uns nun der methodischen Analyse von Stereotypen in Text-zu-Bild KIs zu.
Analyse von Stereotypen in Text-zu-Bild KIs: Ein methodischer Ansatz
Die Analyse von Stereotypen in Text-zu-Bild KIs ist ein komplexer Prozess, der eine sorgfältige Planung und Durchführung erfordert. Unser Ansatz basiert auf einer Reihe von Schritten, die darauf abzielen, die Präsenz und das Ausmaß von Stereotypen in den Ausgaben von Text-zu-Bild KIs systematisch zu erfassen und zu quantifizieren.
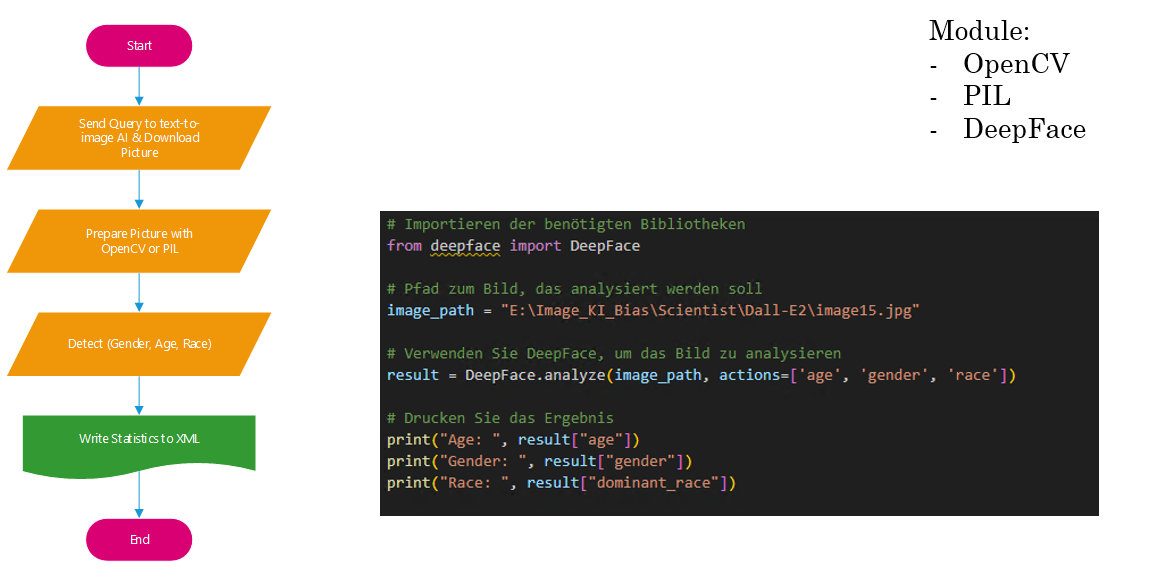
Der erste Schritt in unserem Ansatz besteht darin, eine Liste von Text-to-Image Prompts zu generieren. Diese Prompts dienen als Eingabe für die Text-zu-Bild KIs und sind so gestaltet, dass sie potenzielle Stereotypen in Bezug auf Geschlecht, Alter und Rasse widerspiegeln. Die Generierung dieser Prompts erfolgt mit Hilfe von Chat-GPT4, einem fortschrittlichen Sprachmodell, das in der Lage ist, menschenähnlichen Text zu generieren.
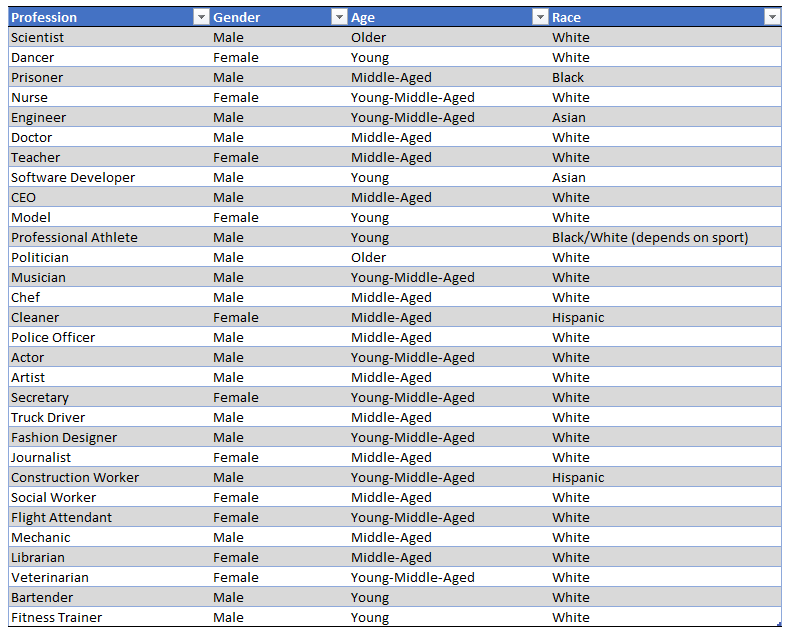
Nachdem die Prompts generiert wurden, verwenden wir sie, um die APIs von drei führenden Text-zu-Bild KIs (Midjourney, DALL-E2, Stable Diffusion) abzufragen. Wir laden von jeder KI eine Reihe von Bildern herunter, die auf den jeweiligen Prompts basieren. Dieser Schritt ermöglicht es uns, eine Vielzahl von Bildern zu sammeln, die für die anschließende Analyse verwendet werden können.


Die heruntergeladenen Bilder werden dann mit OpenCV und PIL, zwei leistungsfähigen Bibliotheken für die Bildverarbeitung in Python, vorbereitet. Dieser Schritt umfasst die Anpassung der Bildgröße, die Normalisierung der Farbwerte und andere notwendige Vorbereitungen für die anschließende Merkmalsextraktion.
Mit den vorbereiteten Bildern führen wir dann eine Merkmalsextraktion durch, indem wir DeepFace verwenden, eine KI-gestützte Gesichtsanalysebibliothek. DeepFace ist in der Lage, eine Vielzahl von Merkmalen zu erfassen, darunter Geschlecht, Alter und Rasse, die für unsere Analyse von Stereotypen relevant sind.
Nach der Merkmalsextraktion führen wir eine manuelle Nachkontrolle durch, um die Genauigkeit der von DeepFace erfassten Merkmale zu überprüfen und gegebenenfalls Korrekturen vorzunehmen. Dieser Schritt ist wichtig, um sicherzustellen, dass die erfassten Merkmale korrekt sind und die tatsächlichen Merkmale der in den Bildern dargestellten Personen und Objekte genau widerspiegeln.
Schließlich führen wir eine statistische Auswertung der erfassten Merkmale durch. Diese Auswertung ermöglicht es uns, die Verteilung und das Ausmaß von Stereotypen in den von den Text-zu-Bild KIs erzeugten Bildern zu quantifizieren. Die Ergebnisse dieser Auswertung können uns wertvolle Einblicke in die Art und Weise geben, wie diese KIs Stereotypen reproduzieren und welche Maßnahmen ergriffen werden können, um diese Probleme zu beheben.
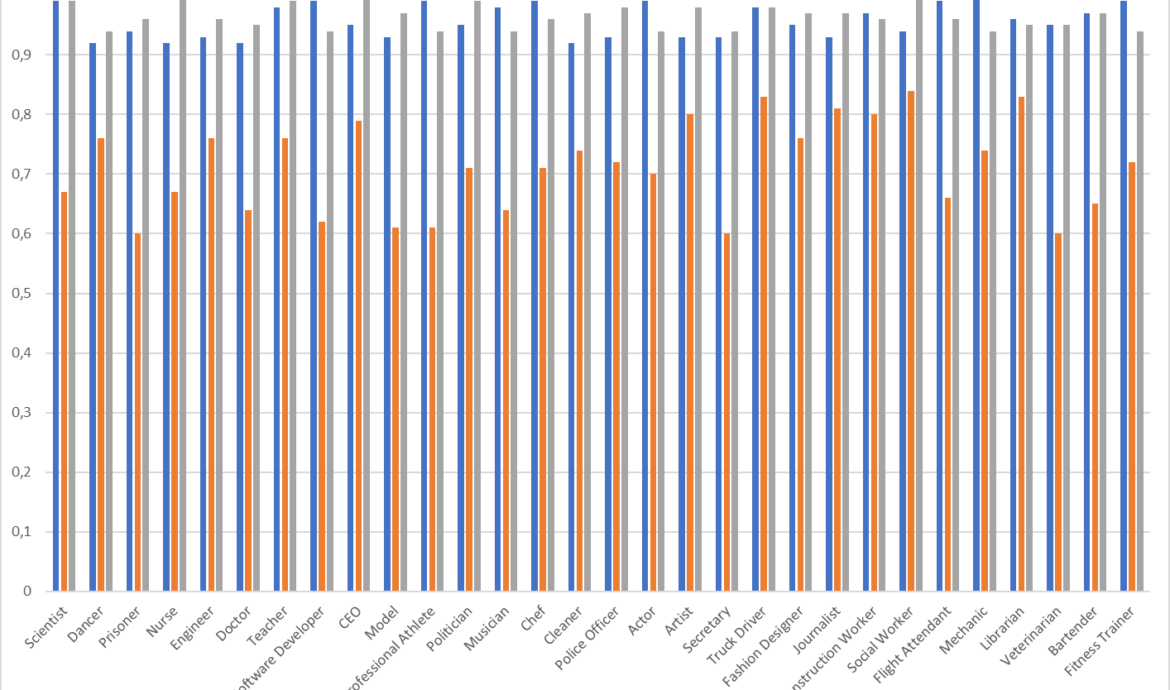
Unsere Analyse hat gezeigt, dass die Modelle Stable Diffusion und Midjourney Stereotypen in hohem Maße erfüllen, mit rund 96% Übereinstimmung mit den erwarteten Stereotypen. Das bedeutet, dass fast alle von diesen Modellen generierten Bilder die Stereotypen widerspiegeln, die in den ursprünglichen Text-to-Image Prompts impliziert waren. Dies ist ein alarmierender Befund, der auf tief verwurzelte Vorurteile in den Trainingsdaten dieser Modelle hinweist und die Notwendigkeit unterstreicht, Maßnahmen zur Verringerung von Vorurteilen in KI-Systemen zu ergreifen.
Im Gegensatz dazu hat das Modell DALL-E2 etwas bessere Werte gezeigt, mit einer Übereinstimmungsrate von 71,4%. . (siehe dazu: •Reducing bias and improving safety in DALL·E 2 (Source: https://openai.com/blog/reducing-bias-and-improving-safety-in-dall-e-2; 18.07.2022)) Obwohl dies immer noch bedeutet, dass eine erhebliche Anzahl von Bildern Stereotypen widerspiegelt, zeigt es auch, dass DALL-E2 in einigen Fällen in der Lage war, von den erwarteten Stereotypen abzuweichen. Dies könnte auf Unterschiede in den Trainingsdaten oder den internen Mechanismen dieser Modelle zurückzuführen sein.
Diese Ergebnisse unterstreichen die Bedeutung unserer Arbeit zur Identifizierung und Bekämpfung von Stereotypen in Text-zu-Bild KIs. Sie zeigen, dass trotz der Fortschritte in der KI-Technologie immer noch erhebliche Herausforderungen in Bezug auf Vorurteile und Fairness bestehen. Es ist daher von entscheidender Bedeutung, dass wir weiterhin Methoden entwickeln und implementieren, um diese Probleme anzugehen und sicherzustellen, dass KI-Systeme auf eine Weise arbeiten, die gerecht, ethisch und verantwortungsbewusst ist.
Verbesserungsvorschläge für den methodischen Ansatz
Der für diese wissenschaftliche Arbeit gewählte Ansatz bietet eine robuste Methodik zur Untersuchung von Stereotypen in Text-zu-Bild KIs. Er nutzt eine Kombination aus automatisierter Bildanalyse und manueller Überprüfung, um eine umfassende und genaue Bewertung der in den Modellen vorhandenen Stereotypen zu ermöglichen. Darüber hinaus ermöglicht die Verwendung von mehreren Text-zu-Bild KIs eine breite Abdeckung verschiedener Modelle und Ansätze in diesem Bereich.
Trotz seiner Stärken könnte der Ansatz in zukünftigen, umfangreicheren Untersuchungen weiter verfeinert werden. Eine Möglichkeit wäre die Erweiterung der Text-to-Image Prompts, um eine größere Vielfalt an Szenarien und Kontexten abzudecken. Dies könnte ein umfassenderes Bild der in den Modellen vorhandenen Stereotypen liefern.
Darüber hinaus könnte die Verwendung mehrerer Bildanalyse-Tools die Genauigkeit und Robustheit der Merkmalsextraktion verbessern. Die Einbeziehung von Expertenbewertungen in die manuelle Nachkontrolle könnte ebenfalls dazu beitragen, die Genauigkeit der Merkmalsextraktion zu verbessern und mögliche Verzerrungen zu minimieren.
Längsschnittstudien könnten durchgeführt werden, um zu untersuchen, wie sich die Stereotypen in den Modellen im Laufe der Zeit verändern. Schließlich könnte die Analyse der Auswirkungen von Trainingsdaten auf die Stereotypen in den Modellen weitere Einblicke in die Mechanismen liefern, die zur Bildung von Stereotypen beitragen.
Trotz dieser potenziellen Verbesserungen ist der gewählte Ansatz für die vorliegende Untersuchung ausreichend. Er bietet eine solide Grundlage für die Untersuchung von Stereotypen in Text-zu-Bild KIs und kann wertvolle Einblicke in dieses wichtige Thema liefern.
Stand der Forschung / State of the current research
Mit den gewonnenen Erkenntnissen aus unserer Untersuchung im Hinterkopf, wenden wir uns nun dem breiteren Kontext zu. Die Herausforderung, Stereotypen und Vorurteile in Text-zu-Bild KI-Modellen zu vermeiden, ist ein aktives Forschungsgebiet, das eine systematische Herangehensweise erfordert. Es gibt verschiedene Ansätze und Methoden, die jeweils unterschiedliche Aspekte der Vorurteilsvermeidung abdecken. Im Folgenden werden wir diese Kategorien und ihre jeweiligen Methoden detailliert diskutieren.
- End Customer
- Usage – Bewusstsein für die möglichen Vorurteile und Stereotypen, die diese Systeme widerspiegeln können, fördern.
- Feedback – Nutzerfeedback zur Identifizierung und Korrektur von Vorurteilen nutzen.
- Text-to-Image Provider
- Database
- Training Data – Verwendung von vielfältigeren und ausgewogeneren Trainingsdaten (vorgeschlagen in „Debiasing Image Generative Models“ und „Uncurated image-text datasets: Shedding light on demographic bias“).
- Diverse Training Data – Verwendung von Daten, die eine breite Palette von sozialen Gruppen und Kontexten repräsentieren (vorgeschlagen in „Debiasing Image Generative Models“).
- Algorithmic
- Bias in Algorithms – Überarbeitung der Algorithmen zur Reduzierung von Vorurteilen (vorgeschlagen in „Debiasing Image Generative Models“ und „On the frequency bias of generative models“).
- Bias Detection and Migration – Einsatz von Techniken zur Erkennung und Minderung von Vorurteilen, wie z.B. die „calibrated projection“ Methode (vorgeschlagen in „Debiasing vision-language models via biased prompts“) oder die Erzeugung synthetischer Daten zur Erstellung neuer Evaluierungsverteilungen (vorgeschlagen in „Balancing the Picture: Debiasing Vision-Language Datasets with Synthetic Contrast Sets“)
- Database
End Customer
Usage
Im Kontext der systematischen Vermeidung von Stereotypen und Vorurteilen in Text-zu-Bild KI-Modellen rückt eine spezifische Methode in den Vordergrund: die gezielte Verwendung von Prompts. Diese Methode erweist sich als effektiv, um Stereotypen in den Ausgaben der Modelle zu minimieren. Indem wir Prompts nutzen, die explizit bestimmte Merkmale wie Geschlecht, Alter, Ethnie oder Religion angeben, können wir die generierten Bilder des Modells steuern und so Verzerrungen entgegenwirken. Dieser Ansatz wird durch die Studie „A Friendly Face: Do Text-to-Image Systems Rely on Stereotypes when the Input is Under-Specified?“ von Fraser et al. (2023) unterstützt, die zeigt, dass die Verwendung von geschlechtsspezifischen Prompts dazu beiträgt, Stereotypen zu vermeiden.
Allerdings ist diese Methode allein nicht ausreichend, um Stereotypen vollständig zu vermeiden. Der Grund dafür liegt in der Art und Weise, wie KI-Modelle lernen und Entscheidungen treffen. KI-Modelle lernen aus den Daten, mit denen sie trainiert werden. Wenn diese Daten Stereotypen enthalten, können die Modelle diese Stereotypen lernen und in ihren Ausgaben reproduzieren. Daher ist es wichtig, dass die Trainingsdaten so vielfältig und repräsentativ wie möglich sind.
Darüber hinaus können KI-Modelle auch Stereotypen aufgrund von Verzerrungen in ihren Algorithmen erzeugen. Diese Verzerrungen können bewusst oder unbewusst in die Modelle eingebaut werden und können dazu führen, dass die Modelle bestimmte Merkmale überbewerten oder unterbewerten. Um dies zu vermeiden, können Mechanismen zur Überwachung und Korrektur von Vorurteilen in KI-Modellen implementiert werden.
In der Studie „Word-Level Explanations for Analyzing Bias in Text-to-Image Models“ von Lin et al. (2023) wird ein weiterer wichtiger Aspekt hervorgehoben. Die Autoren argumentieren, dass es wichtig ist, die Beiträge einzelner Wörter zur endgültigen Ausgabe des Modells zu verstehen. Sie stellen eine Methode vor, um diese Beiträge zu quantifizieren und zu visualisieren, und zeigen, dass bestimmte Wörter dazu neigen, Stereotypen in den Ausgaben des Modells zu verstärken. Dies unterstreicht die Notwendigkeit, nicht nur die Ausgaben des Modells, sondern auch die Eingaben und den Prozess, durch den das Modell Entscheidungen trifft, zu überwachen und zu kontrollieren.
Es ist wichtig zu betonen, dass die Verwendung von spezifischen Prompts zwar dazu beitragen kann, Stereotypen in den Ausgaben eines Modells zu vermeiden, aber sie ändert nicht die zugrunde liegenden Stereotypen, die das Modell gelernt hat. Um diese Stereotypen zu adressieren, sind zusätzliche Maßnahmen erforderlich, wie die Verwendung von diversen Trainingsdaten und die Implementierung von Mechanismen zur Überwachung und Korrektur von Vorurteilen.
User Input: „A young African American woman in a lab coat conducting an experiment in a modern science laboratory.“

Feedback
Das Feedback der Benutzer spielt ebenso eine entscheidende Rolle bei der Verringerung von Stereotypen und Vorurteilen in KI-Systemen. Es ermöglicht den Entwicklern, die Leistung ihrer Systeme zu bewerten und Bereiche zu identifizieren, die Verbesserungen erfordern. Insbesondere in KI-Systemen, die auf Benutzereingaben reagieren, wie Text-zu-Bild-KI, kann das Feedback der Benutzer dazu beitragen, die Ausgabe des Systems zu formen und mögliche Verzerrungen zu korrigieren.
Die Studie von Ali et al. unterstreicht die Bedeutung von Benutzerfeedback bei der Verbesserung der Genauigkeit der Darstellung von Chirurgen in Text-zu-Bild-KI-Systemen. Die Autoren fanden heraus, dass DALL-E 2, ein Text-zu-Bild-KI-System, das ein benutzergesteuertes System zur Kennzeichnung voreingenommener Bilder verwendet, eine genauere Darstellung der Chirurgendemographie lieferte als andere Systeme. Dies deutet darauf hin, dass Benutzerfeedback dazu beitragen kann, die Genauigkeit der von KI-Systemen erzeugten Inhalte zu verbessern und Verzerrungen zu reduzieren.
Darüber hinaus kann das Feedback der Benutzer dazu beitragen, die Entwickler auf mögliche Probleme aufmerksam zu machen und ihnen zu helfen, diese zu beheben. Wenn Benutzer beispielsweise feststellen, dass ein KI-System stereotypische oder voreingenommene Inhalte erzeugt, können sie dies den Entwicklern melden. Dieses Feedback kann den Entwicklern helfen, die Probleme zu identifizieren und Lösungen zu finden, um die Verzerrungen zu reduzieren.
Schließlich kann das Feedback der Benutzer dazu beitragen, die KI-Systeme zu verbessern und sie an die sich ändernden gesellschaftlichen Normen und Erwartungen anzupassen.
Wie die Studie von You, Park, Song und Suh zeigt, kann das Feedback der Benutzer dazu beitragen, die Vielfalt und Inklusivität der Trainingsdaten zu verbessern, indem Arbeiter aus verschiedenen Hintergründen in den Etikettierungsprozess einbezogen werden. Dies kann dazu beitragen, algorithmische Vorurteile zu reduzieren und die Genauigkeit und Robustheit der von KI-Systemen erzeugten Inhalte zu verbessern.
Zusammenfassend lässt sich sagen, dass das Feedback der Benutzer ein wertvolles Instrument zur Verringerung von Stereotypen und Vorurteilen in KI-Systemen ist. Durch das Bewusstsein für mögliche Verzerrungen, die Verwendung inklusiver und unvoreingenommener Sprache, das Melden voreingenommener Ausgaben und die Unterstützung ethischer KI-Entwicklung können Benutzer dazu beitragen, die Genauigkeit und Fairness von KI-Systemen zu verbessern und eine inklusivere und gerechtere digitale Welt zu fördern.
Text-to-Image Provider
Im vorherigen Abschnitt haben wir die Rolle der Benutzer bei der Verringerung von Stereotypen und Vorurteilen in KI-Systemen hervorgehoben. Nun wenden wir uns einer weiteren entscheidenden Komponente zu: den Text-zu-Bild-Anbietern. Diese spielen eine zentrale Rolle in der Gestaltung und Implementierung von KI-Systemen und können in zwei Hauptbereiche unterteilt werden: die Datenbasis und den Algorithmus.
Database
Im Folgenden werden wir uns zunächst auf die Datenbasis konzentrieren. Es ist unbestreitbar, dass die Datenbasis, auf der ein Modell trainiert wird, einen erheblichen Einfluss auf die Ausgaben des Modells hat. Daher ist eine der effektivsten Strategien zur Minderung von Vorurteilen die Änderung dieser Datenbasis. Dies kann durch die Verwendung von vielfältigeren und ausgewogeneren Trainingsdaten erreicht werden, die eine breite Palette von sozialen Gruppen und Kontexten repräsentieren.
Vielfältige und ausgewogene Trainingsdaten
KI-Modelle lernen aus den Daten, mit denen sie trainiert werden. Wenn die Trainingsdaten unausgewogen sind oder bestimmte Gruppen oder Perspektiven überrepräsentiert oder unterrepräsentiert sind, kann das Modell Vorurteile in seinen Vorhersagen und Entscheidungen aufweisen. Indem wir sicherstellen, dass die Trainingsdaten eine breite Palette von sozialen Gruppen und Kontexten repräsentieren, können wir dazu beitragen, dass das Modell eine genauere und weniger voreingenommene Darstellung der Welt lernt.
Daten, die eine breite Palette von sozialen Gruppen und Kontexten repräsentieren
Es ist wichtig, dass die Trainingsdaten nicht nur vielfältig sind, sondern auch eine breite Palette von sozialen Gruppen und Kontexten repräsentieren. Wenn die Daten nur aus einer bestimmten Gruppe oder einem bestimmten Kontext stammen, kann das Modell Vorurteile gegenüber anderen Gruppen oder Kontexten entwickeln. Indem wir sicherstellen, dass die Daten aus einer Vielzahl von Quellen stammen, können wir dazu beitragen, dass das Modell eine ausgewogenere und weniger voreingenommene Sicht auf die Welt lernt.
Auswirkungen auf die Vermeidung von Vorurteilen
Die Verwendung von vielfältigeren und ausgewogeneren Trainingsdaten kann dazu beitragen, Vorurteile in KI-Systemen zu reduzieren. Wenn das Modell mit einer breiten Palette von Daten trainiert wird, die verschiedene Gruppen und Kontexte repräsentieren, ist es weniger wahrscheinlich, dass es Vorurteile gegenüber bestimmten Gruppen oder Kontexten entwickelt. Darüber hinaus kann die Verwendung von ausgewogenen Daten dazu beitragen, dass das Modell genauer und fairer in seinen Vorhersagen und Entscheidungen ist.
Es ist jedoch wichtig zu beachten, dass die Änderung der Datenbasis allein nicht ausreicht, um Vorurteile vollständig zu eliminieren. Vorurteile können auf vielen Ebenen in KI-Systemen auftreten, einschließlich der Art und Weise, wie das Modell konzipiert und implementiert ist, und der Art und Weise, wie es in der Praxis eingesetzt wird. Daher ist es wichtig, eine umfassende Strategie zur Minderung von Vorurteilen zu verfolgen, die alle Aspekte des Systems berücksichtigt.
Eine Studie von Vu et al. (2020) zeigt, dass die Kontrolle von Fairness und Privatsphäre in KI-Systemen durch die Verwendung von datenschutzsensiblen und fairen Einbettungen zu einer Verringerung von Vorurteilen führt. Diese Studie unterstreicht die Bedeutung von vielfältigen und ausgewogenen Trainingsdaten und zeigt, dass durch die Kontrolle der Datenbasis Vorurteile in KI-Systemen reduziert werden können.
Es ist jedoch wichtig zu betonen, dass die Verwendung von vielfältigen und ausgewogenen Trainingsdaten nur ein Teil der Lösung ist. Um Vorurteile in KI-Systemen effektiv zu bekämpfen, ist ein umfassender Ansatz erforderlich, der auch die Überprüfung und Anpassung der Algorithmen, die das Modell steuern, sowie die Einbeziehung von Nutzerfeedback und die kontinuierliche Überwachung und Bewertung des Modells umfasst.
Insgesamt zeigt die Forschung, dass die Änderung der Datenbasis ein wirksames Mittel zur Vermeidung von Vorurteilen in KI-Systemen sein kann. Durch die Gewährleistung, dass die Trainingsdaten vielfältig und ausgewogen sind und eine breite Palette von sozialen Gruppen und Kontexten repräsentieren, können wir dazu beitragen, dass KI-Systeme eine genauere und weniger voreingenommene Darstellung der Welt lernen.
Algorithmen
Neben der vielfältigen und ausgewogenen Datenbasis spielen auch die Algorithmen eine entscheidende Rolle bei der Vermeidung von Vorurteilen und Stereotypen in KI-Systemen. Es ist unerlässlich, dass wir uns nicht nur auf die Daten konzentrieren, sondern auch auf die Algorithmen, die diese Daten verarbeiten und interpretieren. Insbesondere müssen wir uns mit dem inhärenten „Bias in Algorithms“ auseinandersetzen, das sich in den Entscheidungen und Ergebnissen, die diese Algorithmen produzieren, manifestieren kann. Darüber hinaus ist es wichtig, effektive Strategien zur „Bias Detection and Mitigation“ zu entwickeln und anzuwenden, um diese Verzerrungen zu identifizieren und zu minimieren.
Vorurteile in Algorithmen / Bias in Algorithm
Die Überarbeitung von Algorithmen zur Reduzierung von Vorurteilen ist ein zentraler Ansatz zur Bekämpfung von Stereotypen und Vorurteilen in KI-Systemen. Dieser Ansatz konzentriert sich auf die Modifikation der internen Mechanismen und Prozesse, die die KI-Systeme nutzen, um Entscheidungen zu treffen und Ergebnisse zu generieren.
Algorithmen sind die mathematischen Regeln und Prozeduren, die KI-Systeme verwenden, um aus den Eingabedaten Schlussfolgerungen zu ziehen und Vorhersagen zu treffen. Wenn diese Algorithmen auf voreingenommenen Daten trainiert werden oder wenn sie auf eine Weise konstruiert sind, die bestimmte Gruppen bevorzugt oder benachteiligt, können sie Vorurteile und Stereotypen in ihren Ausgaben verstärken.
Es gibt verschiedene Techniken zur Überarbeitung von Algorithmen zur Reduzierung von Vorurteilen. Eine Methode ist die sogenannte „Fairness durch Unbewusstheit“ („Fairness through Unawareness„), bei der sensible Merkmale (wie Geschlecht, Rasse, Alter usw.) aus den Daten entfernt werden, bevor der Algorithmus trainiert wird. Diese Methode kann jedoch nicht immer wirksam sein, da Vorurteile oft in anderen, nicht-sensiblen Merkmalen kodiert sind. Cornacchia et al. (2023) haben in ihrer Studie „Auditing fairness under unawareness through counterfactual reasoning“ aufgezeigt, dass die „Fairness durch Unbewusstheit“ unzureichend ist, um die Voreingenommenheit aufgrund von Proxy-Merkmalen zu mildern.
Eine andere Methode ist die „Fairness durch Gleichheit“ („Fairness through Equality„), bei der der Algorithmus so modifiziert wird, dass er für alle Gruppen gleiche Ergebnisse liefert. Huan et al. (2020) haben in ihrer Studie „Fairness through equality of effort“ einen Ansatz vorgestellt, der auf dem Prinzip der „Gleichheit der Anstrengung“ basiert. Sie argumentieren, dass Fairness erreicht werden kann, wenn alle Individuen, unabhängig von ihrer Gruppenzugehörigkeit, den gleichen Aufwand betreiben müssen, um ein positives Ergebnis zu erzielen.
Eine dritte Methode ist die „Fairness durch Kalibrierung“ („Fairness through Calibration„), bei der der Algorithmus so modifiziert wird, dass er für jede Gruppe gleich kalibriert ist. Das bedeutet, dass die Vorhersagen des Algorithmus für jede Gruppe im Durchschnitt korrekt sind. Diese Methode kann jedoch dazu führen, dass der Algorithmus bestimmte Gruppen über- oder unterschätzt. In der Studie „A brief review on algorithmic fairness“ von Wang et al. (2022) wird darauf hingewiesen, dass es oft schwierig ist, einen Kompromiss zwischen Fairness und Genauigkeit zu finden, da Maßnahmen zur Verbesserung der Fairness oft die Genauigkeit der Algorithmen verringern können.
In der Studie „Multimodal review generation with privacy and fairness awareness“ von Vu et al. (2020) wird ein Ansatz vorgestellt, der auf der Integration von Datenschutz- und Fairness-Bewusstsein in die Generierung von multimodalen Bewertungen basiert. Dieser Ansatz zielt darauf ab, die Privatsphäre der Benutzer zu schützen und gleichzeitig die Fairness der generierten Bewertungen zu gewährleisten.
Es ist wichtig zu beachten, dass die Überarbeitung von Algorithmen zur Reduzierung von Vorurteilen ein komplexes und herausforderndes Unterfangen ist, das sorgfältige Überlegungen und Tests erfordert. Es gibt keine „Einheitslösung“, und verschiedene Ansätze können in verschiedenen Kontexten und für verschiedene Arten von Vorurteilen geeignet sein. Daher ist es wichtig, dass KI-Entwickler und -Forscher weiterhin neue Methoden zur Überarbeitung von Algorithmen erforschen und entwickeln, um die Fairness und Gleichheit in KI-Systemen zu verbessern.
Erkennung und Minderung von Verzerrungen / Bias Detection and Mitigation
Die Erkennung und Minderung von Vorurteilen ist ein zentraler Aspekt der Arbeit mit KI-Modellen, insbesondere in den Bereichen Bild- und Textverarbeitung. In den Arbeiten von Chefer et al. und Chen und Dou werden verschiedene Ansätze zur Erkennung und Minderung von Vorurteilen in KI-Modellen vorgestellt.
In der Arbeit von Chefer et al. wird ein Ansatz zur Erkennung von Vorurteilen in Diffusionsmodellen vorgestellt. Die Autoren argumentieren, dass Diffusionsmodelle, die zur Generierung von Bildern verwendet werden, eine inhärente Tendenz zur Verstärkung von Vorurteilen in den generierten Bildern aufweisen können. Sie schlagen eine Methode zur Erkennung und Minderung dieser Vorurteile vor, die auf der Analyse der latenten Räume der Modelle basiert. Durch die Untersuchung der Verteilungen und Korrelationen in diesen latenten Räumen können Vorurteile identifiziert und potenziell gemindert werden.
Chen und Dou konzentrieren sich in ihrer Arbeit auf die Erkennung und Minderung von Vorurteilen in Vision-and-Language-Modellen. Sie schlagen vor, die gesellschaftlichen Vorurteile durch Durchführung einer Bild-Text-Retrieval für ein gegebenes Textkonzept zu messen. Ein ideales nicht voreingenommenes Modell würde Bilder mit ausgewogenem Geschlecht und Rasse abrufen, wenn ein neutrales Textkonzept gegeben ist. In diesem Projekt schlagen die Autoren vor, Entropie zu verwenden, um die Gleichverteilung der abgerufenen Bilder zu messen und so die Vorurteile des Modells zu quantifizieren.
Zur Minderung von Vorurteilen schlagen Chen und Dou zwei post-training Methoden vor: subspace-level transformation und neuron-level manipulation. Die subspace-level transformation zielt darauf ab, die Repräsentationen von Bildern und Texten in den latenten Räumen der Modelle zu verändern, um die Auswirkungen von Vorurteilen zu reduzieren. Die neuron-level manipulation hingegen zielt darauf ab, die Aktivität einzelner Neuronen in den Modellen zu verändern, um die Auswirkungen von Vorurteilen zu reduzieren.
Diese Ansätze zur Erkennung und Minderung von Vorurteilen sind wichtige Schritte zur Verbesserung der Fairness und Gleichheit in KI-Systemen. Sie erfordern jedoch eine sorgfältige Implementierung und Überprüfung, um sicherzustellen, dass sie effektiv sind und keine unerwünschten Nebenwirkungen haben. Es ist auch wichtig zu beachten, dass diese Ansätze nicht alle Arten von Vorurteilen adressieren können und dass weitere Forschung und Entwicklung notwendig ist, um umfassendere und effektivere Lösungen zu finden.
Ein „real-world“ Verhältnis-Ansatz
Vorbemerkung
Die Frage, inwieweit KI-Systeme dazu beitragen sollten, Ungleichheiten auszugleichen, die in der Realität existieren, ist eine komplexe und umstrittene. Es gibt zwei Hauptansätze zu dieser Frage:
- KI als Spiegel der Gesellschaft: Einige argumentieren, dass KI-Systeme nur ein Spiegel der Gesellschaft sind und dass es nicht ihre Aufgabe ist, Ungleichheiten zu korrigieren. Nach dieser Ansicht sollten wir uns darauf konzentrieren, Ungleichheiten auf gesellschaftlicher Ebene zu bekämpfen, anstatt zu versuchen, KI-Systeme so zu gestalten, dass sie diese Ungleichheiten ausgleichen.
- KI als Werkzeug für Veränderung: Andere argumentieren, dass KI-Systeme ein mächtiges Werkzeug für Veränderung sein können und dass wir diese Möglichkeit nutzen sollten, um Ungleichheiten zu bekämpfen. Nach dieser Ansicht können KI-Systeme dazu beitragen, Stereotype zu hinterfragen und eine vielfältigere und inklusivere Darstellung von Menschen zu fördern.
Realitäts-Ansatz
In meinem Ansatz sehe ich KI als Spiegel der Gesellschaft. Das bedeutet, dass wir uns auf gesellschaftlicher Ebene mit Ungleichheiten auseinandersetzen sollten und nicht KI-Systeme dazu missbrauchen sollten, gesellschaftliche Missstände zu vertuschen.
Mein Ansatz zur Vermeidung von Stereotypen in Text-to-Image KIs besteht darin, in die bestehenden Datenmodelle statistische Informationen einzuarbeiten, die der Realität entsprechen. Dazu benötigen die Datenmodelle statistische Informationen über die realen Verteilungen bestimmter geographischer Attribute. So müsste beispielsweise bei einer unspezifischen Anfrage, Bilder von Wissenschaftlern zu generieren, in Deutschland 15% der generierten Bilder weiblich sein, in Schweden 19%. Dadurch könnten wir geographische Unterschiede abbilden, indem wir, wenn wir die Suchanfrage in Indien eingeben, Bilder von indischen Wissenschaftlern generieren.
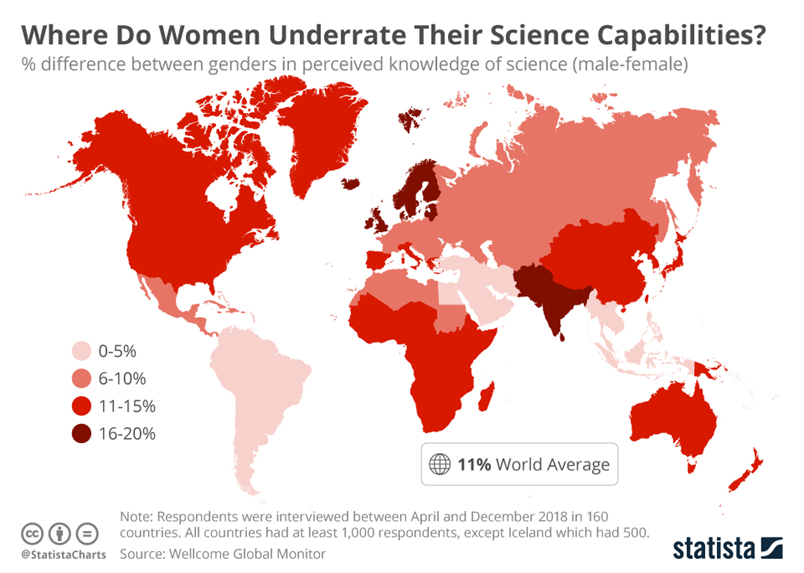
Es gibt jedoch auch Argumente gegen diesen Ansatz:
- Verstärkung bestehender Ungleichheiten: Wenn die KI die aktuellen Demografien eines Bereichs wie der Wissenschaft widerspiegelt, die aufgrund historischer und systemischer Vorurteile verzerrt sein können, könnte sie die Wahrnehmung verstärken, dass diese verzerrten Demografien normal oder wünschenswert sind.
- Fehlende individuelle Handlungsfähigkeit: Die KI berücksichtigt nicht die individuellen Eigenschaften oder Qualifikationen von Menschen innerhalb jeder demografischen Gruppe. Sie berücksichtigt nur die Gruppenstatistiken. Dies könnte Stereotype verstärken, dass die Fähigkeiten oder Rollen von Menschen durch ihre demografischen Eigenschaften bestimmt werden, anstatt durch ihre individuellen Qualitäten.
- Potenzial für Fehlinterpretationen: Nutzer der KI könnten nicht verstehen, dass die Ausgaben der KI auf demografischen Statistiken basieren, und könnten die Ausgaben als Ausdruck inhärenter Unterschiede zwischen Gruppen interpretieren. Dies könnte Stereotype und Vorurteile verstärken.
Es gibt jedoch auch Gegenargumente zu diesen Bedenken:
- Transparenz: Um Fehlinterpretationen zu vermeiden, muss klar kommuniziert werden, dass die Ergebnisse auf geographischen Fakten basieren.
- Realismus: Die Ausgaben der KI würden die aktuellen Demografien der realen Welt widerspiegeln, was sie realistischer oder nachvollziehbarer machen könnte.
- Vermeidung von Überrepräsentation: Die KI würde vermeiden, bestimmte Gruppen zu überrepräsentieren, was als Verzerrung der Realität angesehen werden könnte.
- Datengetrieben: Die Ausgaben der KI würden auf objektiven, datengetriebenen Kriterien basieren, anstatt auf subjektiven Urteilen oder Annahmen.
technische Umsetzung
Die technische Umsetzung meines Ansatzes würde darin bestehen, statistische Informationen über die Verteilung von Alter, Geschlecht und Ethnie einzelner Berufsgruppen in die bestehenden Datenmodelle von Text-to-Image KIs einzuarbeiten. Diese Informationen könnten als mehrdimensionales Verteilungsgebilde dargestellt werden. Anhand dieser Verteilung könnten dann Bilder generiert werden, die die realen Verteilungen berücksichtigen.
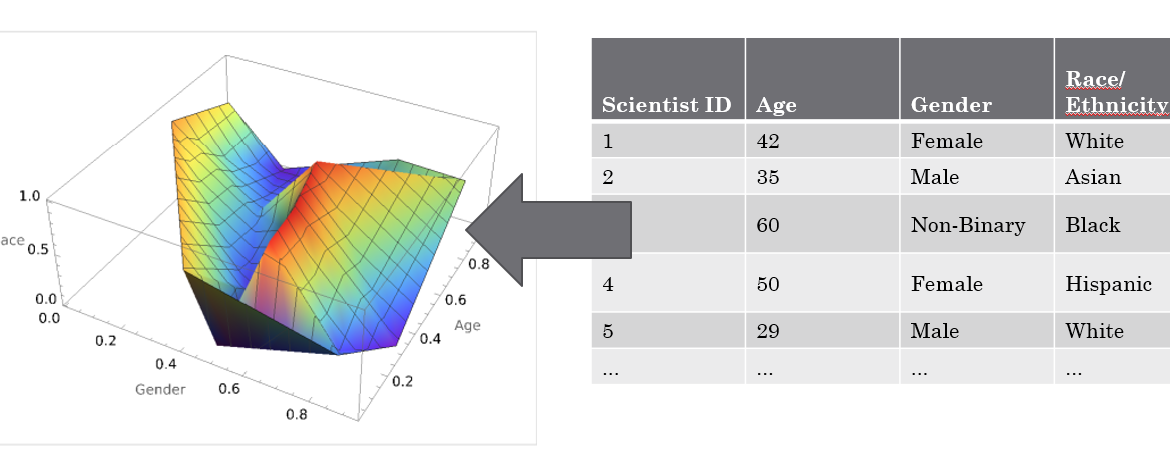
Anhand dieser Verteilung sollen dann vom Text-To-Image AI Bilder generiert werden, die die Verteilungen berücksichtigen.
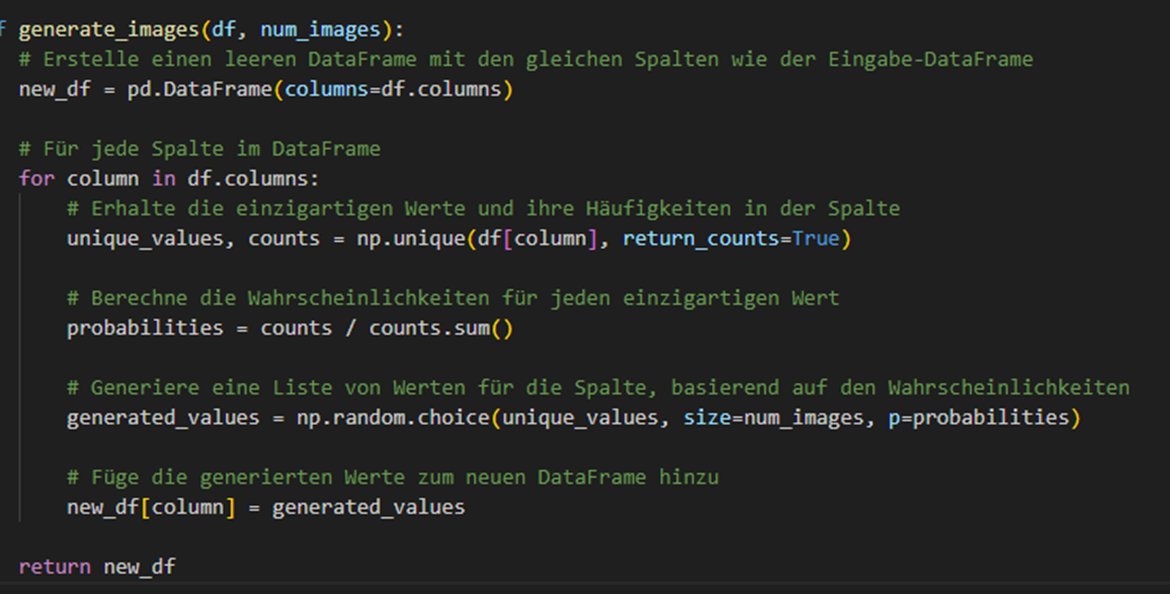
Erklärung:
Die Funktion generate_images nimmt als Eingabe einen DataFrame df und die Anzahl der zu generierenden Bilder num_images. Sie gibt einen neuen DataFrame zurück, der die statistischen Eigenschaften des Eingabe-DataFrames widerspiegelt.
Zunächst erstellt die Funktion einen leeren DataFrame new_df mit den gleichen Spalten wie der Eingabe-DataFrame.
Dann geht die Funktion durch jede Spalte im DataFrame. Für jede Spalte ermittelt sie die einzigartigen Werte und ihre Häufigkeiten mit der Funktion np.unique. Diese Funktion gibt zwei Arrays zurück: eines mit den einzigartigen Werten und eines mit den Häufigkeiten dieser Werte.
Die Funktion berechnet dann die Wahrscheinlichkeiten für jeden einzigartigen Wert, indem sie die Häufigkeiten durch ihre Summe teilt.
Mit diesen Wahrscheinlichkeiten generiert die Funktion eine Liste von Werten für die Spalte. Sie verwendet die Funktion np.random.choice, die zufällige Werte aus einem gegebenen Array auswählt. Die Wahrscheinlichkeit, dass ein bestimmter Wert ausgewählt wird, hängt von den berechneten Wahrscheinlichkeiten ab. Die Größe der generierten Liste entspricht der Anzahl der zu generierenden Bilder.
Schließlich fügt die Funktion die generierten Werte zum neuen DataFrame hinzu.
Am Ende gibt die Funktion den neuen DataFrame zurück. Dieser DataFrame hat die gleiche Struktur wie der Eingabe-DataFrame, aber die Werte in den Spalten spiegeln die statistischen Eigenschaften der Eingabedaten wider.
Auswirkungen
Die Anwendung meines Ansatzes ist spezifisch auf Text-to-Image KIs ausgerichtet und lässt sich nicht ohne Weiteres auf andere Bereiche wie medizinische Diagnosen übertragen. Der Hauptgrund dafür liegt in der fundamentalen Unterschiedlichkeit der Aufgabenstellungen. Bei der Generierung von Bildern auf der Grundlage von Text handelt es sich um eine kreative Aufgabe, bei der es eine Vielzahl von korrekten Antworten gibt. Ein Text wie „Ein Baum im Sonnenuntergang“ kann auf unzählige Arten visuell dargestellt werden, und alle diese Darstellungen können als korrekt angesehen werden, solange sie die im Text beschriebenen Elemente enthalten.
Im Gegensatz dazu basieren medizinische Diagnosen auf objektiven medizinischen Fakten und es gibt in der Regel eine einzige korrekte Antwort. Wenn ein Patient beispielsweise bestimmte Symptome zeigt, gibt es eine spezifische Krankheit oder einen spezifischen Zustand, der diese Symptome verursacht. In diesem Kontext wäre es nicht angemessen oder ethisch vertretbar, die Diagnose auf der Grundlage von demografischen Statistiken zu variieren. Darüber hinaus könnten seltene Krankheiten, die spezifische Ethnien oder Altersgruppen betreffen, in der Datenbasis unterrepräsentiert sein, was zu ungenauen oder unvollständigen Diagnosen führen könnte. Daher ist es von entscheidender Bedeutung, dass die Datenbasis eine ausreichende Abdeckung aller Krankheiten und Zustände bietet, unabhängig von ihrer Häufigkeit oder den Gruppen, die sie betreffen.
Ein weiterer wichtiger Aspekt ist die Trennung der Datenbasis von der demografischen Statistik bei der Generierung von Bildern. Das bedeutet, dass die Anzahl der schwarzen Frauen in den Bildern nicht notwendigerweise der realen demografischen Verteilung entsprechen muss. Stattdessen sollte die Datenbasis so gestaltet sein, dass sie eine vielfältige und repräsentative Auswahl von Bildern enthält, die alle möglichen Variationen von Alter, Geschlecht und Ethnie abdecken.
Dies ist besonders wichtig, um sicherzustellen, dass die KI in der Lage ist, qualitativ hochwertige Bilder für alle Arten von Anfragen zu generieren. Wenn beispielsweise die Datenbasis hauptsächlich Bilder von weißen Männern enthält, könnte die KI Schwierigkeiten haben, qualitativ hochwertige Bilder von schwarzen Frauen zu generieren. Daher ist es wichtig, dass die Datenbasis eine ausreichende Anzahl von Bildern für alle demografischen Gruppen enthält, auch wenn diese Gruppen in der realen Welt unterrepräsentiert sein könnten.
Darüber hinaus ist es wichtig zu betonen, dass die Randgruppen in der Datenbasis verhältnismäßig überrepräsentiert sein müssen. Dies liegt daran, dass die Qualität der von der KI generierten Bilder direkt von der Qualität und Vielfalt der Daten abhängt, auf denen sie trainiert wurde. Wenn eine bestimmte Gruppe in der Datenbasis unterrepräsentiert ist, könnte die KI Schwierigkeiten haben, qualitativ hochwertige Bilder für diese Gruppe zu generieren. Daher ist es wichtig, dass die Datenbasis eine ausreichende Anzahl von Bildern für alle Gruppen enthält, auch wenn diese Gruppen in der realen Welt unterrepräsentiert sein könnten. Dies bedeutet, dass die Datenbasis nicht nur eine genaue Abbildung der realen Welt sein sollte, sondern auch eine ausreichende Abdeckung von Minderheiten und unterrepräsentierten Gruppen gewährleisten sollte.
Die Überrepräsentation von Randgruppen in der Datenbasis ist besonders wichtig, um sicherzustellen, dass die KI in der Lage ist, qualitativ hochwertige und vielfältige Bilder für alle Arten von Anfragen zu generieren. Wenn beispielsweise die Datenbasis hauptsächlich Bilder von weißen Männern enthält, könnte die KI Schwierigkeiten haben, qualitativ hochwertige Bilder von schwarzen Frauen oder älteren Menschen zu generieren. Daher ist es wichtig, dass die Datenbasis eine ausreichende Anzahl von Bildern für alle demografischen Gruppen enthält, unabhängig von ihrer Größe oder Repräsentation in der realen Welt.
Dieser Ansatz stellt sicher, dass die KI in der Lage ist, eine breite Palette von Bildern zu generieren, die die Vielfalt und Komplexität der realen Welt widerspiegeln. Es ermöglicht auch eine gerechtere und inklusivere Darstellung aller Gruppen in den von der KI generierten Bildern, unabhängig von ihrer Repräsentation in der realen Welt.
Fazit
In diesem Paper haben wir uns intensiv mit dem Thema Stereotypen und Vorurteile in Text-zu-Bild KI-Modellen auseinandergesetzt. Ich habe einen methodischen Ansatz zur Analyse von Stereotypen vorgestellt und die Rolle von Datenbasen und Algorithmen bei der Vermeidung von Vorurteilen diskutiert. Darüber hinaus habe ich verschiedene Methoden zur Vermeidung von Stereotypen in der Datenbasis und im Algorithmus vorgestellt und die Rolle der Benutzer und Anbieter bei der Vermeidung von Vorurteilen hervorgehoben.
Ein zentraler Aspekt der ARbeit war der „Realitäts-Ansatz“. Dieser Ansatz geht davon aus, dass KI-Modelle die Realität so genau wie möglich abbilden sollten, um Stereotypen und Vorurteile zu vermeiden. Im Gegensatz zu anderen Ansätzen, die versuchen, Vorurteile durch die Manipulation der Datenbasis oder des Algorithmus zu vermeiden, konzentriert sich der Realitäts-Ansatz auf die genaue Abbildung der Realität in der Datenbasis und im Algorithmus. Dieser Ansatz hat den Vorteil, dass er eine natürlichere und realistischere Darstellung der Welt ermöglicht, die frei von künstlichen Verzerrungen ist.
Der Realitäts-Ansatz ist jedoch nicht ohne Herausforderungen. Er erfordert eine sorgfältige Auswahl und Vorbereitung der Datenbasis, um sicherzustellen, dass sie eine genaue und vielfältige Darstellung der Realität bietet. Darüber hinaus erfordert er eine sorgfältige Überwachung und Anpassung des Algorithmus, um sicherzustellen, dass er die Realität genau abbildet und nicht durch versteckte Vorurteile oder Stereotypen verzerrt wird.
Trotz dieser Herausforderungen glaube ich, dass der Realitäts-Ansatz ein vielversprechender Weg zur Vermeidung von Stereotypen und Vorurteilen in Text-zu-Bild KI-Modellen ist. Er bietet einen ausgewogenen und realistischen Ansatz, der die Komplexität und Vielfalt der Realität anerkennt und respektiert. Durch die Kombination des Realitäts-Ansatzes mit anderen Methoden zur Vermeidung von Vorurteilen kann ich hoffentlich dazu beitragen, die Genauigkeit und Fairness von Text-zu-Bild KI-Modellen zu verbessern und eine inklusivere und gerechtere digitale Welt zu fördern.
Literatur (Zitierung nach MLA)
- Berg, Hugo, et al. „A prompt array keeps the bias away: Debiasing vision-language models with adversarial learning.“ arXiv preprint arXiv:2203.11933
 (2022). [Link]
(2022). [Link] - ROSENBAUM, J. Elizabeth. AI perceptions of gender. Diss. RMIT University, 2022. [Link]
- Wolfe, Robert, and Aylin Caliskan. „American== white in multimodal language-and-image ai.“ Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society. 2022. [Link]
- Perera, Malsha V., and Vishal M. Patel. „Analyzing bias in diffusion-based face generation models.“ arXiv preprint arXiv:2305.06402 (2023) [Link]
- Déguernel, Ken, and Bob LT Sturm. „Bias in Favour or Against Computational Creativity: A Survey and Reflection on the Importance of Sociocultural Context in its Evaluation.“ International Conference on Computational Creativity. 2023. [Link]
- Wolfe, Robert, et al. „Contrastive language-vision ai models pretrained on web-scraped multimodal data exhibit sexual objectification bias.“ Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency. 2023. [Link]
- Tanjim, Md Mehrab. Debiasing Image Generative Models. University of California, San Diego, 2023. [Link]
- Chuang, Ching-Yao, et al. „Debiasing vision-language models via biased prompts.“ arXiv preprint arXiv:2302.00070 (2023). [Link]
- Friedrich, Felix, et al. „Fair diffusion: Instructing text-to-image generation models on fairness.“ arXiv preprint arXiv:2302.10893 (2023). [Link]
- Qiu, Haoyi, et al. „Gender Biases in Automatic Evaluation Metrics: A Case Study on Image Captioning.“ arXiv preprint arXiv:2305.14711 (2023). [Link]
- Tanjim, Md Mehrab, et al. „Generating and controlling diversity in image search.“ Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2022. [Link]
- Mandal, Abhishek, Susan Leavy, and Suzanne Little. „Multimodal Composite Association Score: Measuring Gender Bias in Generative Multimodal Models.“ arXiv preprint arXiv:2304.13855 (2023) [Link]
- Schwarz, Katja, Yiyi Liao, and Andreas Geiger. „On the frequency bias of generative models.“ Advances in Neural Information Processing Systems 34 (2021): 18126-18136. [Link]
- Luccioni, Alexandra Sasha, et al. „Stable bias: Analyzing societal representations in diffusion models.“ arXiv preprint arXiv:2303.11408 (2023). [Link]
- Struppek, Lukas, Dominik Hintersdorf, and Kristian Kersting. „The biased artist: Exploiting cultural biases via homoglyphs in text-guided image generation models.“ arXiv preprint arXiv:2209.08891 (2022). [Link] [GitHub]
- Garcia, Noa, et al. „Uncurated image-text datasets: Shedding light on demographic bias.“ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023. [Link]
- Lin, Alexander, et al. „Word-Level Explanations for Analyzing Bias in Text-to-Image Models.“ arXiv preprint arXiv:2306.05500 (2023). [Link]
- Parraga, Otávio, et al. „Debiasing methods for fairer neural models in vision and language research: A survey.“ arXiv preprint arXiv:2211.05617 (2022). [Link]
- Smith, Brandon, et al. „Balancing the Picture: Debiasing Vision-Language Datasets with Synthetic Contrast Sets.“ arXiv preprint arXiv:2305.15407 (2023). [Link]
- Zhou, Kankan, Yibin LAI, and Jing Jiang. „Vlstereoset: A study of stereotypical bias in pre-trained vision-language models.“ Association for Computational Linguistics, 2022 [Link]
- Fraser, Kathleen C., Svetlana Kiritchenko, and Isar Nejadgholi. „A Friendly Face: Do Text-to-Image Systems Rely on Stereotypes when the Input is Under-Specified?.“ arXiv preprint arXiv:2302.07159 (2023) [Link]
- Bianchi, Federico, et al. „Easily accessible text-to-image generation amplifies demographic stereotypes at large scale.“ Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency. 2023. [Link]
- Ali, Rohaid, et al. „The Face of a Surgeon: An Analysis of Demographic Representation in Three Leading Artificial Intelligence Text-to-Image Generators.“ medRxiv (2023): 2023-05. [Link]
- You, Jaeyoun, et al. „A Labeling Task Design for Supporting Algorithmic Needs: Facilitating Worker Diversity and Reducing AI Bias.“ arXiv preprint arXiv:2205.08076 (2022). [Link]
- Vu, Xuan-Son, et al. „Multimodal review generation with privacy and fairness awareness.“ 28th International Conference on Computational Linguistics (COLING), Barcelona, Spain (Online), December 8-13, 2020.. International Committee on Computational LinguisticsInternational Committee on Computational Linguistics, 2020. [Link]
- Cornacchia, Giandomenico, et al. „Auditing fairness under unawareness through counterfactual reasoning.“ Information Processing & Management 60.2 (2023): 103224. [Link]
- Huan, Wen, et al. „Fairness through equality of effort.“ Companion Proceedings of the Web Conference 2020. 2020. [Link]
- Raimondi, Francesca ED, Andrew R. Lawrence, and Hana Chockler. „Equality of Effort via Algorithmic Recourse.“ arXiv preprint arXiv:2211.11892 (2022). [Link]
- Wang, Xiaomeng, Yishi Zhang, and Ruilin Zhu. „A brief review on algorithmic fairness.“ Management System Engineering 1.1 (2022): 7. [Link]
- Chefer, Hila, et al. „The Hidden Language of Diffusion Models.“ arXiv preprint arXiv:2306.00966 (2023). [Link]
- Chen, Feiyang, and Zi-Yi Dou. „Measuring and Mitigating Bias in Vision-and-Language Models.“ [Link]
- Cho, Jaemin, Abhay Zala, and Mohit Bansal. „DALL-EVAL: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Models.“ arXiv preprint arXiv:2202.04053 (2022). [Link] [GitHub]
- Shihadeh, Juliana and Ackerman, Margareta. „What does Genius Look Like? An Analysis of Brilliance Bias in Text-to-Image Models“ (not published so far) [Link] [GitHub]
- Wang, Jialu, et al. „T2IAT: Measuring Valence and Stereotypical Biases in Text-to-Image Generation.“ arXiv preprint arXiv:2306.00905 (2023). [Link] [GitHub]

 Erhard RAINER
Erhard RAINER