Wenn man ein neues BI-Projekt startet, gibt es einige Dinge, die man betrachten sollte und einige Schritte, die man ausführen sollte. Dies ist ungeachtet davon, ob man mit dem ersten BI-Projekt in einem Unternehmen anfängt oder weitere Datenquellen bzw. Bereiche, Subunternehmen usw. in ein bestehendes Modell integrieren möchte. Bei dem ersten BI-Projekt ohne bestehende Infrastruktur sind den hier erwähnten Schritten noch einige vorgelagert. Für den konkreten Datentopf sind diese Schritte selbstverständlich danach auch notwendig.
Anforderungsanalyse
Wenn man ein BI-Projekt startet, steht man als erstes vor der Frage, welche Anforderungen das neue Reporting / Datenmodell / Dashboard erfüllen muss. Die erste Frage die man sich dabei stellen muss: Wer sind die Stakeholder des BI-Projektes? Das mag auf den ersten Blick oftmals leicht erscheinen, ist es in der Praxis aber nicht immer.
Kennt man seine Benutzer muss man die tatsächlichen Bedürfnisse der Benutzer ermitteln. Dabei kann es oftmals hilfreich sein Geschäftsprozesse zu analysieren und sich anzusehen, wie tatsächlich gearbeitet wird und nicht nur wie die theoretische Arbeitsanweisung für einen Geschäftsprozess aussieht. Da liegen oft Welten dazwischen.
Danach entwickelt man einen Fragenkatalog bzw. passt seinen bestehenden an die Gegebenheiten an, um die notwendigen Informationen zu erhalten. Hierbei haben sich folgende Kapitel des Anforderungsdokumentes als sinnvoll erwiesen:
- Allgemeines / Projektumgebung
- Benutzerkreis
- Ziele des Modells
- Erforderliche Business-Entitäten (Dimensionen, Attribute, Kennzahlen)
- Aggregationsverhalten
- Berechnungen / KPIs / KPI-Systeme
- Währungsumrechnung
- Garnularität
- Historie (historische Korrektheit) evtl. Archivierung
- Reporting / Dashboard / Self-Service BI
- Integration in andere Systeme / Navigation
- Performanceanforderungen
- Aktualität der Daten / Periodizität
- Berechtigungen
- Integration in die bestehende Systemlandschaft
Feldanalyse und Beschreibung
Als Ergebnis der Kennzahlenanalyse (manchmal wird es auch noch als Bestandteil der Kennzahlenanalyse betrachtet) kommen vereinfacht folgende Anforderungen heraus. (Übersicht der Bestellungen und Erlöse nach Kundenaufträgen mit Sollbuchungen inklusive Fakturawerte nach Kunde, Material, Faktura, Verkauf, Buchungskreis, Verkaufsorganisation, Vertriebsweg, …)
Auf Basis dieser Anforderungen lassen sich dann folgende Kennzahlen und Merkmale/Attribute/Dimensionen ermitteln:
- Kennzahlen
- Auftragswert
- Auftragskosten
- Fakturawert
- Profit (Differenz zwischen Fakturawert und Bestellwert)
- Merkmale (in SAP InfoObjects)
- Kunde
- Material
- Fakturabeleg
- Fakturaposition
- Verkaufsbeleg
- Verkaufsposition
- Buchungskreis
- Verkaufsorganisation
- Vertriebsweg
- Sparte
- Kalenderjahr / -monat
- Basismengeneinheit
- Zusatzmerkmale
- Vertriebsbeleg
- Soll-/Habenbuchung
In der Praxis ist es sinnvoll auch noch die Stakeholder der einzelnen Attribute zu notieren und zu analysieren, wie hoch der Aufwand der Integration ist. Hierfür muss man sich ansehen, woher die Daten kommen. Mehr dazu in unserem Leitfaden.
Am Beispiel von SAP wären das in diesem Fall folgende Tabellen:
siehe Wie kann ich mir die Felder einer SAP Tabelle ansehen?
Als nächstes sollte man sich ansehen, wie man die Daten filtern muss/möchte. Im konkreten Fall
- Vertriebsbeleg (=> InfoObjekt: 0IMODOCCAT) – in unserem Fall: C (Auftrag)
- Belegkassen (=> InfoObjekt: 0DOC_CLASS) – in unserem Fall: I (Rechnung)
- Soll-Habenbuchung (=> InfoObjekt: 0DEB_CRED) – in unserem Fall: D (Debit)
Falls es jemanden interessiert, hier ein Blog-Post, wie man das InfoObjekt zu eine Spalte ermitteln kann.
Kennzahlen-Matrix
Nachdem man nun genau weiß, welche Kennzahlen und Merkmale man benötigt, sollte man es in eine Kennzahlen-Matrix überleiten. Hierzu trägt man die Kennzahlen auf der Y-Achse auf und die Merkmale auf der X-Achse. Optimalerweise ergänzt man noch für jede Kennzahl die zugrundeliegende Tabelle (inkl. Feld(er). Machmal ist es auch zweckmäßig, die Kennzahl zu kategorisieren. In der Literatur findet man dazu verschiedene Ansätze. Im SAP-Umfeld untscheidet man in der Regel:
- BKF (Basic Key Figure) – auf ungefilterte Daten
- RKF (Restricted Key Figrue) – auf eingeschränkte Daten
- CKF (Calculated Key Figure) – berechnet
Man kann diese Tabelle noch beliebig erweitern, beispielsweis hinsichtlich der Zeit-Ganularität usw.
Eine solche Tabelle könnte so aussehen:
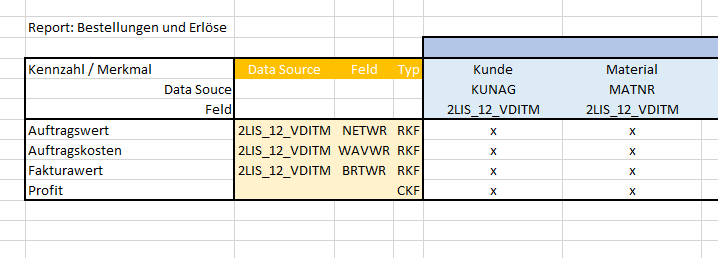
Dabei ist einer Sache besondere Aufmerksamkeit zu schenken: Wenn eine Kennzahl auf einer höheren Ebene existiert als ein Merkmal, so kann man diese auf tieferen Ebenen nicht verwenden. Ein Beispiel: Würde in der Tabelle Faktura Kopfdaten ein Feld existieren, wie beispielsweise Auftragswert der gesamten Faktura, dann kann es nicht in Verbindung gebracht werden mit der Tabelle Faktura Positionsdaten. Somit dürfte in dieser Kombination kein (x) stehen.
Integration in die (bestehende) Architektur
Hier unterscheiden sich die einzelnen BI Systeme erheblich. Ich möchte es daher an zwei unterschiedlichen Architetkruen zeigen:
- Microsoft BI
- SAP BW
SAP BW
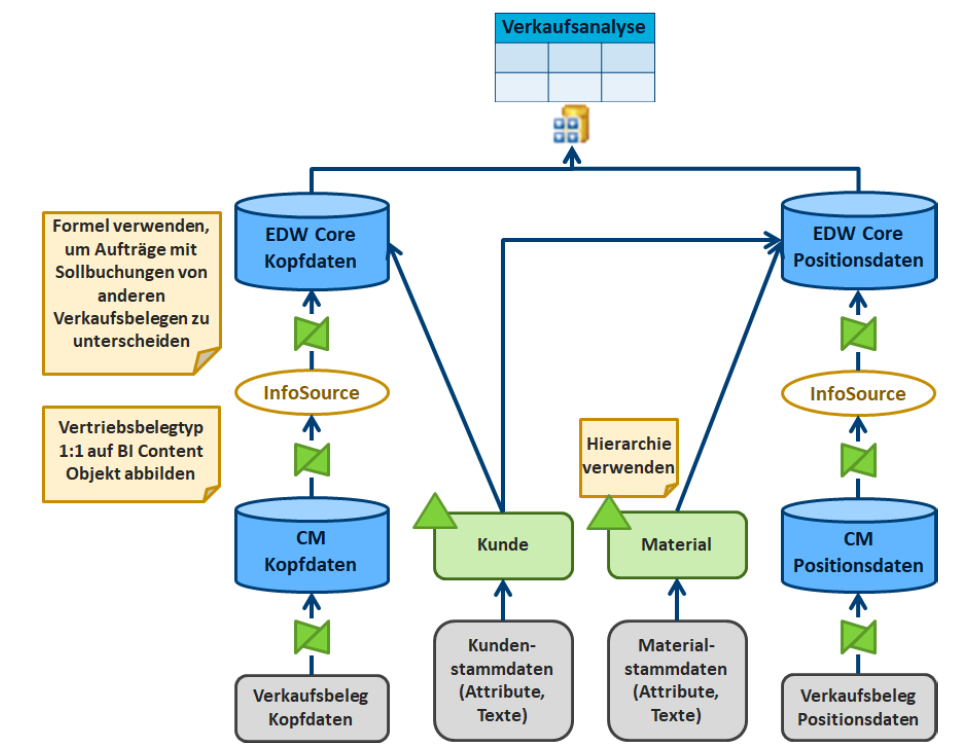
eine andere ARt das darzustellen könnte sein:

1. Daten aus DataSources in ADSOs im Corporate Memory laden
Die Daten aus den Quellsystemen können aus verschiedenen Quellen stammen, z. B. aus SAP ERP, SAP CRM oder SAP SCM. Die Daten werden in ADSOs im Corporate Memory geladen, die speziell für die Verkaufsübersicht angelegt werden.
2. Kopf- und Positionsdaten in separate ADSOs in die Kern-EDW-Schicht laden
Die Kopf- und Positionsdaten werden in separate ADSOs in der Kern-EDW-Schicht geladen, um eine bessere Performance zu erzielen. Die Kopfdaten enthalten allgemeine Informationen zu einer Transaktion, z. B. die Kundennummer, die Auftragsnummer oder den Umsatz. Die Positionsdaten enthalten detaillierte Informationen zu den einzelnen Produkten oder Dienstleistungen, die in einer Transaktion verkauft werden.
3. Transformationen für die Unterscheidung von Aufträgen und Sollbuchungen durchführen
Aufträge und Sollbuchungen werden in SAP BW unterschiedlich verarbeitet. Aufträge werden in der Regel in der Finanzbuchhaltung erfasst, während Sollbuchungen in der Logistikbuchhaltung erfasst werden. Um diese beiden Datensätze voneinander unterschieden zu können, müssen sie in zwei separaten Transformationen verarbeitet werden.
In der ersten Transformation wird der Auftragstyp aus den Kopfdaten ermittelt. In der zweiten Transformation wird der Buchungsschlüssel aus den Positionsdaten ermittelt. Wenn der Auftragstyp oder der Buchungsschlüssel auf einen Auftrag hinweist, werden die Daten in den ADSO für Aufträge geladen. Wenn der Auftragstyp oder der Buchungsschlüssel auf eine Sollbuchung hinweist, werden die Daten in den ADSO für Sollbuchungen geladen.
4. Kundenstammdaten und Materialstammdaten in benutzerdefinierte Merkmals-InfoObjects laden
Um die Kopf- und Positionsdaten anzureichern, werden Kundenstammdaten und Materialstammdaten in benutzerdefinierte Merkmals-InfoObjects geladen. Diese InfoObjects werden dann in den finalen Datamart für die Verkaufsübersicht geladen.
Die Kundenstammdaten enthalten Informationen zu den Kunden, mit denen das Unternehmen Geschäfte macht. Die Materialstammdaten enthalten Informationen zu den Produkten oder Dienstleistungen, die das Unternehmen verkauft.
5. Finaler Datamart für die Verkaufsübersicht
Der finale Datamart für die Verkaufsübersicht kombiniert die Kopf- und Positionsdaten aus den ADSOs und stellt sie als Schnittstelle für die Query bereit. Der CompositeProvider ist eine spezielle Art von Datamart, die mehrere Datenquellen kombinieren kann.
Logisches Modell
Als nächster Schritt bildet man logisches Modell. Dies kann einerseits ein klassisches Stern-Schema sein oder anderseits vereinfachte Darstellungen wie ein „Bubble-Modell“.

Umsetzung
Danach kommt es zur Umsetzung.

 Erhard RAINER
Erhard RAINER