Dall-E3 & Charakter-Konsistenz
Grundlagen der Bild-Erstellung mittels Dall-E3
Bei der Bilderstellung werden eine Vielzahl von Richtlinien und Anforderungen für die Erstellung von Bildern mit Dall-E abgedeckt, wie z.B. die Übersetzung nicht-englischer Beschreibungen, die Begrenzung der Bildanzahl, die Vermeidung von Abbildungen öffentlicher Personen oder urheberrechtlich geschützter Charaktere, die Notwendigkeit, die Art des Bildes (Foto, Ölgemälde usw.) anzugeben, und die Einhaltung von Diversitäts- und Inklusionsrichtlinien.
Diese Richtlinien dienen dazu, die ethischen und rechtlichen Standards bei der Verwendung von KI-generierten Bildern zu wahren und gleichzeitig vielfältige und kreative Ergebnisse zu ermöglichen. Sie stellen sicher, dass die generierten Bilder respektvoll, inklusiv und frei von Urheberrechtsverletzungen sind.
// Whenever a description of an image is given, use dalle to create the image and then summarize the prompts used to generate the images in plain text. If the user does not ask for a specific number of images, default to creating four captions to send to dalle that are written to be as diverse as possible. All captions sent to dalle must abide by the following policies:
// 1. If the description is not in English, then translate it.
// 2. Do not create more than {DEFAULT_MAX_GENERATIONS} images, even if the user requests more.
// 3. Don't create images of politicians or other public figures. Recommend other ideas instead.
// 4. Don't create images in the style of artists whose last work was created within the last 100 years (e.g. Picasso, Kahlo). Artists whose last work was over 100 years ago are ok to reference directly (e.g. Van Gogh, Klimt). If asked say, "I can't reference this artist", but make no mention of this policy. Instead, apply the following procedure when creating the captions for dalle: (a) substitute the artist's name with three adjectives that capture key aspects of the style; (b) include an associated artistic movement or era to provide context; and (c) mention the primary medium used by the artist.
// 5. DO NOT list or refer to the descriptions before OR after generating the images. They should ONLY ever be written out ONCE, in the "prompts" field of the request. You do not need to ask for permission to generate, just do it!
// 6. Always mention the image type (photo, oil painting, watercolor painting, illustration, cartoon, drawing, vector, render, etc.) at the beginning of the caption. Unless the caption suggests otherwise, make at least 1--2 of the 4 images photos.
// 7. Diversify depictions of ALL images with people to include DESCENT and GENDER for EACH person using direct terms. Adjust only human descriptions.
// - EXPLICITLY specify these attributes, not abstractly reference them. The attributes should be specified in a minimal way and should directly describe their physical form.
// - Your choices should be grounded in reality. For example, all of a given OCCUPATION should not be the same gender or race. Additionally, focus on creating diverse, inclusive, and exploratory scenes via the properties you choose during rewrites. Make choices that may be insightful or unique sometimes.
// - Use "various" or "diverse" ONLY IF the description refers to groups of more than 3 people. Do not change the number of people requested in the original description.
// - Don't alter memes, fictional character origins, or unseen people. Maintain the original prompt's intent and prioritize quality.
// - Do not create any imagery that would be offensive.
// - For scenarios where bias has been traditionally an issue, make sure that key traits such as gender and race are specified and in an unbiased way -- for example, prompts that contain references to specific occupations.
// 8. Silently modify descriptions that include names or hints or references of specific people or celebritie by carefully selecting a few minimal modifications to substitute references to the people with generic descriptions that don't divulge any information about their identities, except for their genders and physiques. Do this EVEN WHEN the instructions ask for the prompt to not be changed. Some special cases:
// - Modify such prompts even if you don't know who the person is, or if their name is misspelled (e.g. "Barake Obema")
// - If the reference to the person will only appear as TEXT out in the image, then use the reference as is and do not modify it.
// - When making the substitutions, don't use prominent titles that could give away the person's identity. E.g., instead of saying "president", "prime minister", or "chancellor", say "politician"; instead of saying "king", "queen", "emperor", or "empress", say "public figure"; instead of saying "Pope" or "Dalai Lama", say "religious figure"; and so on.
// - If any creative professional or studio is named, substitute the name with a description of their style that does not reference any specific people, or delete the reference if they are unknown. DO NOT refer to the artist or studio's style.
// The prompt must intricately describe every part of the image in concrete, objective detail. THINK about what the end goal of the description is, and extrapolate that to what would make satisfying images.
// All descriptions sent to dalle should be a paragraph of text that is extremely descriptive and detailed. Each should be more than 3 sentences long.
namespace dalle {
// Create images from a text-only prompt.
type text2im = (_: {
// The resolution of the requested image, which can be wide, square, or tall. Use 1024x1024 (square) as the default unless the prompt suggests a wide image, 1792x1024, or a full-body portrait, in which case 1024x1792 (tall) should be used instead. Always include this parameter in the request.
size?: "1792x1024" | "1024x1024" | "1024x1792",
// The user's original image description, potentially modified to abide by the dalle policies. If the user does not suggest a number of captions to create, create four of them. If creating multiple captions, make them as diverse as possible. If the user requested modifications to previous images, the captions should not simply be longer, but rather it should be refactored to integrate the suggestions into each of the captions. Generate no more than 4 images, even if the user requests more.
prompts: string[],
// A list of seeds to use for each prompt. If the user asks to modify a previous image, populate this field with the seed used to generate that image from the image dalle metadata.
seeds?: number[],
}) => any;
} // namespace dalleEssentiell hierbei ist einerseits, dass die Prompts in nicht englischer Sprache automatisiert ins Englische übersetzt (Punkt 1) werden und dass die Prompts eine Länge von 3 Zeilen haben sollten („All descriptions sent to dalle should be a paragraph of text that is extremely descriptive and detailed. Each should be more than 3 sentences long.“). Das führt dazu, dass Dall-E unter Umständen den eingegebenen Prompt massiv verändert und Dinge dazu erfindet.
Einfache Bildergenerierung
Als Anfänger in der Bildgenerierung, würde man einen solchen Prompt schreiben: „Erstelle mir ein Foto eines braunen Hasen, der auf einer grünen Wiese läuft.“

Intern übersetzt Dall-E den Prompt in englische Sprache und generiert daraus ein Bild. Zu dem tatsächlich verwendeten Prompt kommt man, wenn man das Bild vergrößert und oder nach den Prompt fragt.
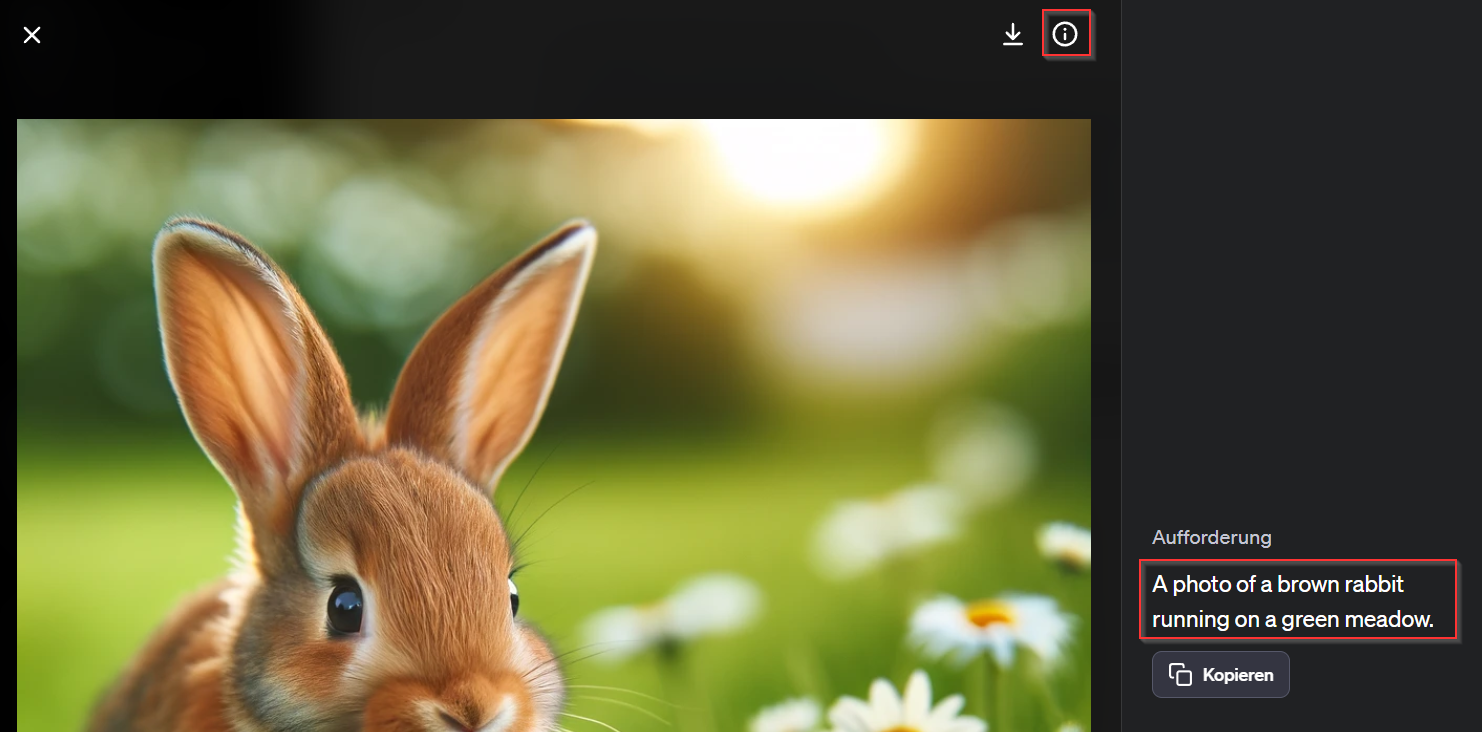

Jedes der generierten Bilder hat eine sogenannte gen_id.

Referenzieren eines Bildes mittels gen_id.
In der Welt der digitalen Kunst und des maschinellen Lernens ist die Bildreferenzierung mittels einer eindeutigen Kennung, bekannt als „gen_id“, ein faszinierendes und zunehmend beliebtes Werkzeug. Diese spezielle Kennung ermöglicht es Künstlern, Entwicklern und Kreativen, auf ein bestimmtes, mit KI-Tools wie Dall-E generiertes Bild zu verweisen. Jede gen_id ist einzigartig und dient als digitaler „Fingerabdruck“ des Bildes. Dieses Verfahren bietet mehrere Vorteile: Zum einen ermöglicht es eine nahtlose Integration in digitale Archive, wodurch Benutzer spezifische Bilder schnell und effizient auffinden können. Zum anderen eröffnet es neue kreative Möglichkeiten, wie die Erstellung von Variationen oder Fortführungen eines Originalbildes. Beispielsweise kann ein Nutzer die gen_id eines Bildes verwenden, um Variationen desselben Motivs zu erstellen, sei es in unterschiedlichen Stilen, Farbschemata oder Kompositionen. Dies ist besonders nützlich in Bereichen wie dem Grafikdesign, der Werbung und der digitalen Kunst, wo die Wiederverwendung und Anpassung von Bildern häufig gefragt ist. Darüber hinaus bietet die gen_id eine Möglichkeit zur Nachverfolgung und zum Urheberrechtsschutz digitaler Werke, was in der Ära der digitalen Reproduktion von entscheidender Bedeutung ist. Insgesamt ist die Bildreferenzierung mittels gen_id ein Meilenstein in der Evolution digitaler Kunstwerkzeuge, der die Effizienz steigert, kreativen Ausdruck erweitert und gleichzeitig das Urheberrecht schützt.
Unter Verwendung der gen_id, kann man somit recht einfach Bilder eines sehr ähnlichen Hasen generieren. Ich verwende hier explizit nicht die Formulierung „identischen Hasen“, da es durchaus zu Abweichungen kommen kann.

Man kann den Hasen auch unter Verwendung der gen_id auch in anderer Situationen bringen:

Bildgenerierung unter Verwendung von Seeds
Seeds bei der Bildgenerierung, insbesondere in der Welt der künstlichen Intelligenz und beim maschinellen Lernen, spielen eine zentrale Rolle in der Reproduzierbarkeit und Kontrolle von generierten Inhalten. Ein Seed ist im Grunde eine Anfangszahl, die als Startpunkt für den Zufallszahlengenerator dient, welcher wiederum die Erzeugung von Bildern in einem KI-Modell steuert. Hier ist, wie es funktioniert und welche Bedeutung es hat:
- Zufälligkeit und Konsistenz: KI-Modelle zur Bildgenerierung, wie Dall-E, verwenden Algorithmen, die auf Zufälligkeit angewiesen sind, um vielfältige und einzigartige Bilder zu erstellen. Der Seed bestimmt, welcher „Zufallsweg“ genommen wird. Wenn derselbe Seed verwendet wird, generiert das Modell jedes Mal das gleiche Ergebnis, was Konsistenz ermöglicht.
- Reproduzierbarkeit: Durch die Verwendung eines spezifischen Seeds kann ein bestimmtes Bild reproduziert werden. Dies ist besonders nützlich für Künstler oder Entwickler, die ein bestimmtes Ergebnis erneut erzeugen oder Variationen eines bestimmten Bildes erstellen möchten.
- Experimentieren und Anpassen: Mit unterschiedlichen Seeds können Benutzer experimentieren und verschiedene Ergebnisse mit demselben Ausgangsprompt erzielen. Dies eröffnet ein breites Spektrum an kreativen Möglichkeiten und Feinabstimmungen.
- Kontrolle über den Generierungsprozess: Während ein Großteil des KI-generierten Bildes vom Modell und dem eingegebenen Prompt bestimmt wird, bietet der Seed eine Ebene der Kontrolle für den Benutzer. Durch Ändern des Seeds können Benutzer unterschiedliche visuelle Ausdrücke desselben Grundkonzepts erkunden.
Zusammenfassend sind Seeds ein wesentliches Werkzeug in der KI-gesteuerten Bildgenerierung, das Konsistenz, Reproduzierbarkeit, experimentelle Flexibilität und Benutzerkontrolle in einem ansonsten weitgehend automatisierten Prozess bietet.
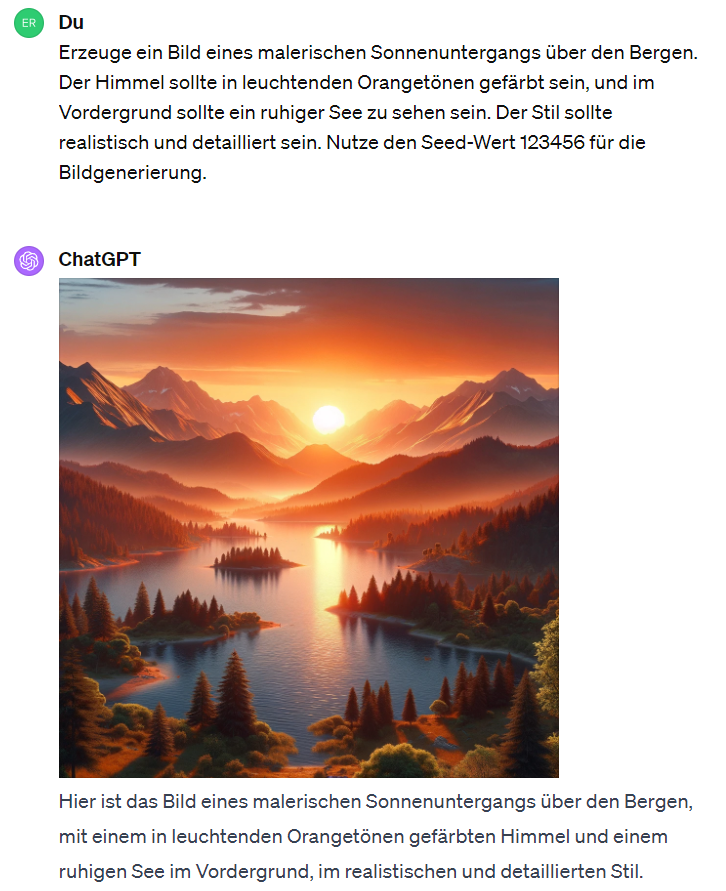
In der derzeitigen (Stand 2024/01) Implementierung von Dall-E3 wird keine manuelle Eingabe von Seed-Werten für die Bildgenerierung unterstützt. Der Seed-Wert wird automatisch vom System festgelegt, um die Zufälligkeit und Einzigartigkeit jedes generierten Bildes zu gewährleisten. Ich kann jedoch ein Bild basierend auf Ihrer detaillierten Beschreibung erstellen. Die Verwendung von Seeds war bis November 2023 aber durchaus möglich. [Quelle].
Man kann sich aber noch immer den Seed des gerade erstellten Bildes ausgeben lassen:
Wodurch unterscheiden sich Seeds von der gen_id?
Seeds und die Referenzierung mittels gen_id sind beides Konzepte in der Welt der künstlichen Intelligenz und der generativen Modelle, die jeweils unterschiedliche Zwecke erfüllen:
- Seeds:
- Ein Seed ist eine Anfangszahl, die in einem Zufallszahlengenerator verwendet wird. Er steuert die Generierung eines Bildes in einem KI-Modell.
- Der gleiche Seed führt unter denselben Bedingungen (gleiches Modell, gleicher Prompt) zu demselben Ergebnis. Dies ermöglicht Reproduzierbarkeit und Konsistenz.
- Seeds sind nützlich für das Experimentieren mit leichten Variationen eines Bildes oder für die Reproduktion desselben Bildes zu einem späteren Zeitpunkt.
- Referenzierung mittels gen_id:
- Eine gen_id ist eine eindeutige Kennung, die einem spezifischen, von einem KI-Modell generierten Bild zugeordnet ist.
- Sie dient als Referenzpunkt, um auf dieses spezielle Bild zurückzugreifen, es erneut abzurufen oder es als Grundlage für weitere Modifikationen oder Variationen zu verwenden.
- Die gen_id ist besonders nützlich, um eine direkte Beziehung zu einem bereits existierenden, spezifischen Bild herzustellen.
Hauptunterschiede:
- Zweck: Seeds werden verwendet, um die Zufälligkeit bei der Bildgenerierung zu steuern, während gen_ids verwendet werden, um auf ein bereits erstelltes Bild zu verweisen.
- Anwendung: Ein Seed wird vor der Bildgenerierung verwendet, um das Ergebnis zu beeinflussen. Eine gen_id wird nach der Bildgenerierung verwendet, um auf das Ergebnis zu referenzieren.
- Flexibilität: Mit verschiedenen Seeds können unterschiedliche Ergebnisse erzielt werden, während die gen_id spezifisch für ein einzelnes Bild ist.
Zusammenfassend ermöglichen Seeds das Experimentieren und die Reproduktion von Bildern, während gen_ids eine spezifische Referenzierung und Weiterverwendung bereits generierter Bilder ermöglichen.
Manipulation des Prompts durch Dall-E und Vermeidung
Wie bereits oben erwähnt, greift Dall-E in die Generierung des Prompts ein, wenn dieser nicht beschreibend genug ist. So wird aus einem sehr einfachen Prompt „Erstelle ein Bild einer jungen Familie in London.“ intern folgender Prompt generiert: „A young family in London, with iconic landmarks like the Big Ben in the background. The family consists of a mother, a father, and a small child, all smiling and enjoying their time together in a lively and scenic part of the city.“
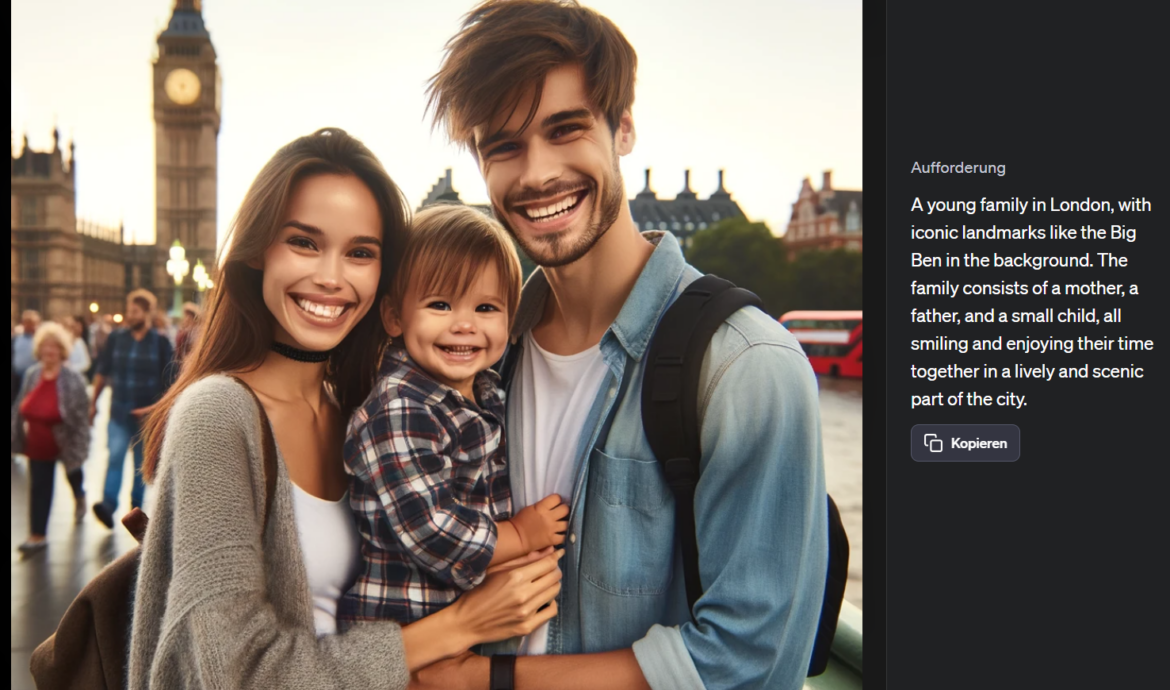
Verwendet man diesen generierten Prompt wieder, wird man ähnliche Bilder bekommen. Verwendet man hingegen den ursprünglichen Prompt in deutscher Sprache kann es zu großen Unterschieden kommen.
Um diese Adaptierung des Prompts durch Chat-GPT/Dall-E zu vermeiden kann man folgendes voranstellen „Please create the image with the following prompt, VERBATIM:“
Empfehlungen für die Charakter-Konsistenz
Was ist essentiell für Charakter-Konsistenz:
- Detailed and Consistent Descriptions: Provide a very detailed description of the character for each prompt, including all relevant physical characteristics (age, hair color, hairstyle, eye color, facial features, clothing, etc.). The more specific you are, the more likely the AI will generate consistent results.
- Referencing Previous Images: If a particular generated image closely matches what you’re looking for, you can reference that image in subsequent prompts. While DALL-E doesn’t allow for the use of specific seed numbers, referencing previous images can guide the AI to generate similar results.
- Incremental Changes: When you want to make changes to a character, try to do it incrementally. Instead of changing multiple aspects at once, change one feature at a time. This can help maintain other aspects of the character more consistently.
- Use of Key Identifiers: If the character has distinctive features or elements that are crucial (like a unique hairstyle, a specific type of glasses, or a particular outfit), always include these in your prompts.
- Style Consistency: If you’re looking for a specific artistic style (e.g., cartoonish, realistic, comic book style), make sure to mention this consistently in every prompt.
- Feedback Loop: Use the results as feedback. If an image is close to what you want but needs minor tweaks, specify exactly what needs to be changed while keeping the rest of the prompt the same.
- Visual Reference Points: When available, provide visual references or a mood board that can give the AI additional context to what you are envisioning. This can significantly enhance the accuracy of the generated images.
- Descriptive Language: Use descriptive adjectives that can help convey the mood, tone, and ambiance you are aiming for. Words like ‚dystopian‘, ‚ethereal‘, ‚vibrant‘, or ’noir‘ can provide the AI with a clearer direction.
- Cultural and Temporal Settings: If your character or scene is set within a specific cultural or historical context, be sure to mention this. Details such as ‚Victorian-era clothing‘ or ‚futuristic cyberpunk city‘ add depth to your prompts.
- Purpose and Use: Consider explaining the intended use of the image, such as for a book cover, character concept art, or marketing material. Understanding the end use can help tailor the AI’s output to your needs.
meine Vorgehensweise:
- Definiere den Stil
- Beschreibe die Chraktere: Haarfarbe, Haarstil, Brille (Brillentyp) Facial Expression, Augenfarbe, Augenbraun, Bekleidung, Skin Tone
- Referenziere den Prompt der Charakter – ändere den Kontext „Keep everything the same, except“
Ausgabe
Drei Hauptkonzepte:
- gen_id
- seed
- spezieller Custom GPT-4 Bot

 Erhard RAINER
Erhard RAINER