
Im Umgang mit SQL-Tabellen gibt es zwei wesentliche Partitionierungen:
- vertikale Partitionierung
- horizontale Partitionierung
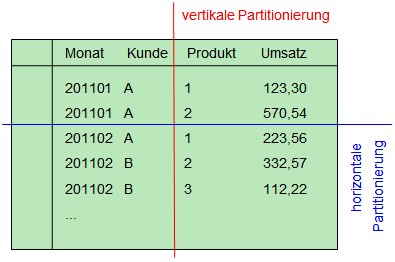
In diesem Artikel widme ich mich der horizontalen Partitionierung, da sie in meinen Augen die häufiger verwendete Partitionierung ist.
Ausgangssituation
Ausgang ist eine Tabelle mit 500 Millionen Elementen, auf die eine Abfrage mit einer Where Clause ausgeführt wird. Diese Abfrage dauert ohne besonderer Vorbereitung der Tabelle 2:41 min. Das ist wirklich lange.
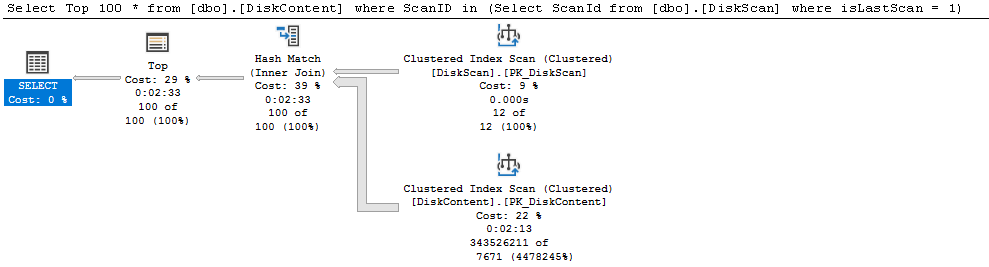
In der ersten Ausbaustufe der Performance-Erhöhung wird ein Non-Clustered Index auf die Spalte eingefügt, auf die mit der Where Clause gefiltert wird. Danach dauert die Abfrage nur mehr 1 min. Dh. die Zeit wurde mehr als halbiert.
Noch mehr kann man aber herausholen, wenn man die die Tabelle partitioniert.
Horizontale Partitionierung
In diesem Fall ist eine horizontale Partitionierung sinnvoll, weil die Anzahl der Spalten mehr aus überschaubar ist, aber die Anzahl der Zeilen ist sehr groß. Bei der horizontalen Partitionierung werden die Daten auf mehrere Partitionen aufgeteilt, die optimalerweise in unterschiedlichen File-Groups gespeichert werden. Um noch mehr an Performance herauszuholen, kann es darüber hinaus sinnvoll sein, die File-Groups auf unterschiedlichen Festplatten zu speichern.
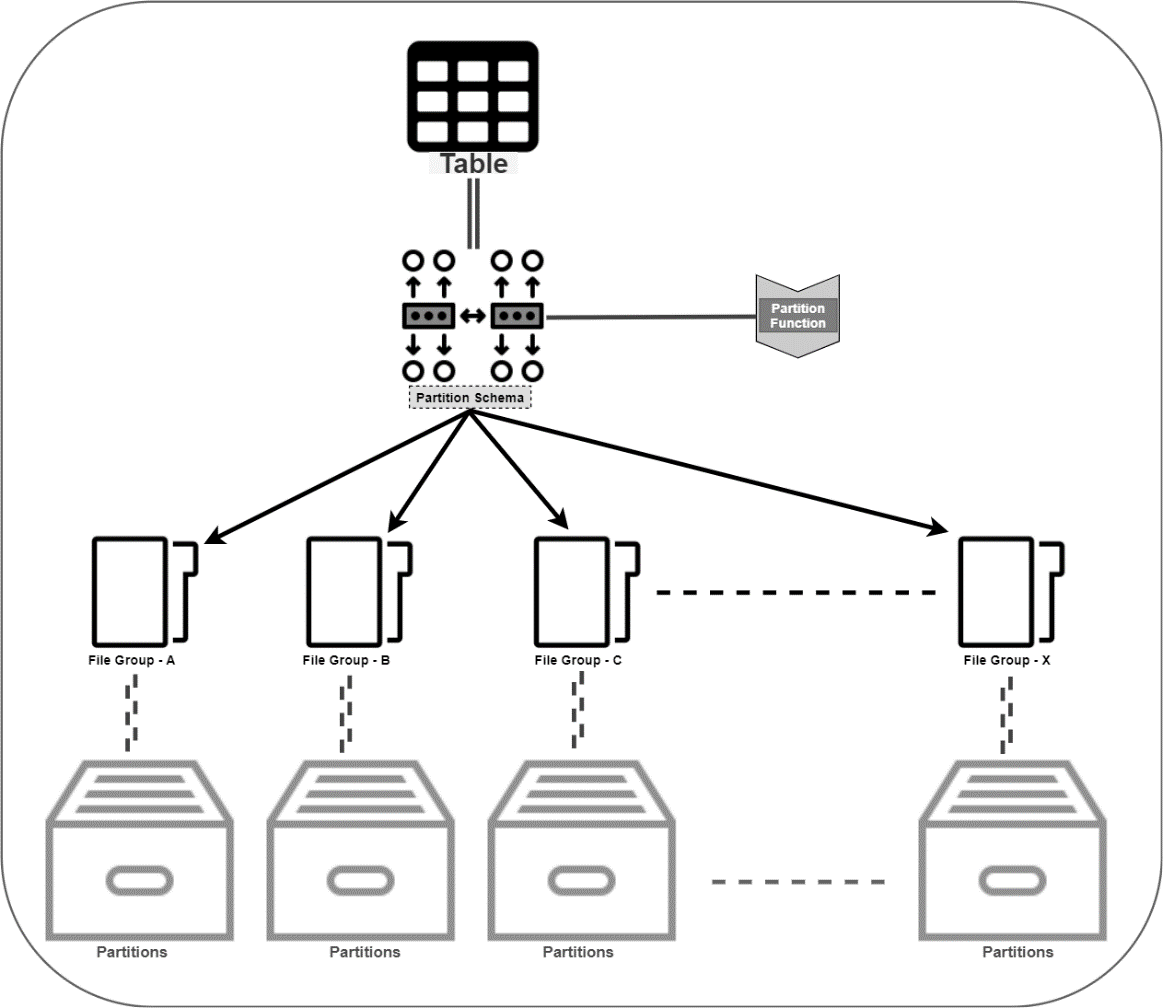
Eine horizontale Partitionierung besteht aus 2 Schritten:
- Erstellen einer PARTITION FUNCTION
- Erstellen eines PARTITION SCHEME
Bevor man sich jedoch an die Arbeit macht, dass man die Daten partitioniert, sollte man sich Gedanken machen, wie man die Daten aufteilt. Pauschale Antworten hier zu geben, ist gefährlich. Die Daten sollten aber jedenfalls so partitioniert werden, dass auf die einzelnen File-Groups gleichermaßen zugegriffen wird. Und diese auf unterschiedlichen Festplatten liegen. Ich spreche in dem Zusammenhang bewusst von Festplatten (oder SSDs) und nicht von Partitionen, da auf einer Festplatte auch mehrere Partitionen liegen können. Handelt es sich um Einzelplatten sollte man berücksichtigen, dass die Last auf die Platten gleichermaßen verteilt wird. zB Gibt es 6 DB-Partitionen und 3 liegen auf Festplatte 1 und 3 liegen auf Festplatte 2, dann sollte sichergestellt werden, dass die Last auf die 2 Platten gleichermaßen aussieht. Grundsätzlich gilt das selbe für RAID-Systeme, wenngleich man in der Regel nicht mehrere RAID-Arrays in einem Rechner hat. Durch die Performancesteigerungen von RAIDs ist das aber unter Umständen zu vernachlässigen.
Bevor wir uns der Umsetzung widmen, möchte ich noch ein paar von meinen Studenten regelmäßig gestellten Fragen nachgehen:
- Kann man Partitionen über mehrere Spalten erstellen? In MS SQL ist die partition function auf eine Spalte limitert. Aber man kann sich mit mit sog. persisted computed colums behelfen. (das sind Spalten, die aus mehreren Spalten bestehen – zB mittels CONCAT). Eine weitere Möglichkeit wäre eine Checksum Spalte (Checksum oder besser Hashbytes, da es bei CRC32 zu Hash Collisionen kommen kann) – näheres dazu hier: Checksumen (Hash) Berechnungen in SQL
- Braucht man bei der Partitionierung einen Primary Key? Grundsätzlich sind SQL-Tabellen ohne Primärschlüssel gültig und man kann auch Tabellen ohne PK partitionieren. Wenn man einen PK hat, muss eine der im PK verwendeten Spalten die Partitions-Spalte sein. In der Theorie zu relationalen Datenbanken benötigt eine Tabelle per Definition einen Primärschlüssel
- Ist Partitionierung Bestandteil der ANSI/ISO Standards? Nein und das wird es in meinem Verständnis auch nie sein. Es handelt sich dabei um eine physische Speichermethode die von Hersteller zu Hersteller unterschiedlich umgesetzt ist oder gar nicht existiert.
Bei der horizontalen Partitionierung wird eine Tabelle zeilenweise aufgeteilt. Das bedeutet: Anstatt alle Daten in einer einzigen großen Tabelle zu speichern, wird der Datenbestand in mehrere Teilmengen (Partitionen) zerlegt – basierend auf dem Wert einer oder mehrerer Spalten, typischerweise einer Zeit- oder Bereichsspalte.
Bei der horizontalen Partitionierung wird eine große Tabelle in Zeilenbereiche unterteilt, wobei alle Daten physisch in einer einzigen Tabelle bleiben – jedoch intern über sogenannte Partitionen verwaltet werden. Diese Technik ist besonders nützlich bei großen Tabellen mit Milliarden von Datensätzen, bei denen typischerweise nur ein Teil abgefragt wird.
SQL Server bietet dafür ein mächtiges Feature: Partitioned Tables, welche über eine Kombination aus Partition Function, Partition Scheme und einem geeigneten Partition Key realisiert werden.
Beispiel 1: Zeitbasierte Partitionierung – korrekt in SQL Server umgesetzt
Ziel: Aufteilen einer Sales-Tabelle nach Verkaufsdatum (SaleDate), sodass z. B. nur das aktuelle Jahr gelesen wird.
Partition Function
-- Partition nach Jahr (Ende jedes Jahres als Grenze)
CREATE PARTITION FUNCTION pf_SalesByYear (DATE)
AS RANGE LEFT FOR VALUES ('2022-12-31', '2023-12-31', '2024-12-31');Partition Scheme
-- Alle Partitionen auf derselben Filegroup
CREATE PARTITION SCHEME ps_SalesByYear
AS PARTITION pf_SalesByYear
ALL TO ([PRIMARY]);Partitionierte Tabelle erstellen
CREATE TABLE Sales (
SaleID INT IDENTITY(1,1),
SaleDate DATE NOT NULL,
Amount DECIMAL(10,2),
CustomerID INT
)
ON ps_SalesByYear (SaleDate);Ab jetzt landen Datensätze automatisch in der passenden Partition, abhängig vom SaleDate.
Beispiel 2: Partitionierung nach Regionen mit Lookup-Spalte
Nehmen wir an, es gibt eine Spalte RegionCode (z. B. 1 = EU, 2 = US, 3 = Asia) – auch das kann für echte horizontale Partitionierung verwendet werden.
CREATE PARTITION FUNCTION pf_SalesByRegion (INT)
AS RANGE LEFT FOR VALUES (1, 2); -- ergibt 3 Partitionen: <=1, 2, >2
CREATE PARTITION SCHEME ps_SalesByRegion
AS PARTITION pf_SalesByRegion
ALL TO ([PRIMARY]);
CREATE TABLE SalesByRegion (
SaleID INT IDENTITY(1,1),
RegionCode INT NOT NULL, -- 1=EU, 2=US, 3=Asia
SaleDate DATE NOT NULL,
Amount DECIMAL(10,2)
)
ON ps_SalesByRegion (RegionCode);Somit bleibt alles in einer Tabelle, aber physisch optimiert nach Region.
Beispiel 3: konkretes Beispiel inkl. Erstellung und Pflege
In großen Data-Warehouse-Szenarien mit SQL Server ist die Partitionierung von Tabellen ein wichtiges Werkzeug, um Performance zu verbessern und die Wartbarkeit großer Datenmengen zu gewährleisten. In diesem Artikel betrachten wir die Erstellung und Erweiterung von Partitionen, insbesondere mit Fokus auf das Szenario der Partitionierung nach FiscalID (Jahr + Monat).
Wann lohn sich Partitionierung?
- Faustregel: ab 1 Million Zeilen pro Partition (idealerweise)
- ab 100.000 Zeilen kann es sich bei gezieltem Zugriff lohnen
- Besonders sinnvoll bei:
- Zeitbasierter Analyse (z. B. per
PostingDate,FiscalID) - Wiederkehrender Archivierung / Reindizierung nach Zeiträumen
- Zeitbasierter Analyse (z. B. per
Möglichkeiten der Partitionserstellung
Option A: Partitionen auf Vorrat erstellen
Die beste Praxis für viele BI-/Finanzsysteme ist das vorausschauende Erstellen von Partitionen, z. B. für ein komplettes Folgejahr. Dadurch:
- Müssen im laufenden Betrieb keine neuen Partitionen angelegt werden
- Ladeprozesse laufen schneller, da kein Repartitionieren nötig ist
- Neue Perioden werden einfach befüllt
Empfehlung: Immer Partitionen für das aktuelle Jahr + 1 Folgejahr vorbereiten
Beispiel: Am 01.05.2025 sollten Partitionen bis 31.12.2026 vorhanden sein (FiscalID = 2026012)
Option B: Automatisiertes Erweitern bei Bedarf
Alternativ lässt sich prüfen, ob eine neue FiscalID in den Daten auftaucht, die noch nicht partitioniert ist – und automatisch eine neue Partition anlegen. Das lässt sich z. B. per SQL-Agent-Job einmal täglich realisieren.
Diese Variante ist flexibel, erfordert aber gute Kontrolle über Berechtigungen und Monitoring.
Skript zur jährlichen Erweiterung der Partitionen auf Vorrat
Folgendes Skript prüft, wie weit die Partitionierung aktuell reicht und fügt neue Partitionen bis zum 31.12. des Folgejahres hinzu:
DECLARE @Boundary INT;
DECLARE @Target INT;
-- Bestimme aktuell höchste Partitionierungsgrenze (FiscalID z. B. 202512)
SELECT @Boundary = MAX(value)
FROM sys.partition_range_values
WHERE function_id = OBJECT_ID('pf_FiscalRange');
-- Zielgrenze z. B. bis zum Dezember des Folgejahres
DECLARE @YearNow INT = YEAR(GETDATE());
SET @Target = (@YearNow + 1) * 100 + 12; -- z. B. 202612
WHILE @Boundary < @Target
BEGIN
SET @Boundary += 1;
EXEC ('ALTER PARTITION FUNCTION pf_FiscalRange() SPLIT RANGE (' + CAST(@Boundary AS NVARCHAR) + ')');
END;Dieses Skript kannst du z. B. am 1. Januar jeden Jahres automatisch ausführen lassen (per SQL Agent).
Vorteile der echten horizontalen Partitionierung in SQL Server
- Partition Elimination: SQL Server erkennt anhand des Partition Keys, welche Partitionen abgefragt werden müssen.
- Maintenance-Vorteile: Alte Partitionen können effizient archiviert oder gelöscht werden.
- Bessere Query Performance: Besonders bei Range-Queries (z. B.
WHERE SaleDate >= '2023-01-01') kann massiv beschleunigt werden.
Wie erfolgt der Zugriff auf Partitionen – und warum ist das performant?
Die horizontale Partitionierung von Tabellen ist weit mehr als nur ein Performance-Optimierungswerkzeug – sie bringt auch klare Vorteile bei Wartung, Datenmanagement und Compliance. Der Schlüssel zur Effizienz liegt im strukturierten Zugriff auf Partitionen, der sich in zwei Hauptmechanismen unterteilt: Partition Elimination und Parallelisierung. Darüber hinaus ergeben sich zahlreiche betriebspraktische Vorteile, die den Einsatz von Partitionierung in produktiven Datenbanksystemen besonders attraktiv machen.
Performance-Optimierung durch Partition Elimination
Ein besonders wirkungsvoller Performance-Vorteil entsteht durch die sogenannte Partition Elimination. Dabei erkennt der SQL Server anhand eines geeigneten Filters in der Abfrage – z. B. WHERE SaleDate BETWEEN '2023-01-01' AND '2023-12-31' – welche Partition(en) relevant sind, und liest ausschließlich diese. Der Rest der Daten bleibt unangetastet. So lassen sich riesige Datenmengen effizient einschränken.
Das Prinzip funktioniert wie eine Postsortierung: Wenn ein Brief nach 1010 Wien geht, greift man direkt ins passende Fach – anstatt alle Briefe durchzublättern.
Konkret profitieren solche Abfragen durch:
- Weniger I/O-Zugriffe: Nur relevante Datenblöcke müssen gelesen werden – Festplattenzugriffe und RAM-Belastung werden reduziert.
- Schnellere Ausführungspläne: Der Optimizer kann gezielt kleinere Datenmengen verarbeiten.
- Effiziente Indexnutzung: Indizes können partitioniert gepflegt und genutzt werden – ganz ohne globale Sperren.
Wichtig: Partition Elimination funktioniert nur, wenn der Partition Key direkt in der WHERE-Klausel verwendet wird. Funktionen wie YEAR(SaleDate) = 2023 verhindern die Optimierung, weil der Optimizer den Zielbereich nicht mehr eindeutig zuordnen kann.
Performance-Optimierung durch Parallelisierung
Selbst wenn Partition Elimination nicht greift – etwa bei SELECT * FROM Sales – ermöglicht die Partitionierung eine parallele Verarbeitung von Daten:
- SQL Server kann Partitionen gleichzeitig mit mehreren Threads abarbeiten,
- was besonders bei großen Datenmengen oder Aggregationen die Performance deutlich steigert.
Der Effekt wird maximiert, wenn die Partitionen auf unterschiedliche Filegroups verteilt sind, die ihrerseits auf separaten physischen Festplatten liegen. In diesem Fall erfolgt der Zugriff nicht nur parallel auf CPU-Ebene, sondern auch auf Storage-Ebene – mit voller I/O-Bandbreite.
Aber auch wenn alle Partitionen auf derselben Festplatte liegen, ergibt sich ein Vorteil:
- SQL Server kann Partitionen logisch aufteilen und intern auf mehrere Ausführungspfade verteilen,
- wodurch sich mehrere CPU-Kerne effizient auslasten lassen,
- und komplexe Abfragen (z. B. mit GROUP BY oder Window Functions) deutlich beschleunigt werden.
Weitere Vorteile der Partitionierung in der Praxis
Neben den Performance-Gewinnen bietet die horizontale Partitionierung zahlreiche betriebspraktische Vorteile, die sie zu einem zentralen Element moderner Datenarchitekturen machen:
🔧 Wartbarkeit
- Indizes, Statistiken und Checks lassen sich gezielt partitioniert ausführen – das spart Zeit und Ressourcen.
- Alte Daten können partitioniert gelöscht oder archiviert werden – z. B. mit
SWITCHoderTRUNCATE PARTITION.
📦 Datenarchivierung und Lifecycle Management
- Aktuelle Daten können auf schnellem Storage, historische auf günstigem Langzeitstorage gehalten werden.
- Partitionen lassen sich in Archivtabellen verschieben – ohne Kopieren, rein per Metadatenmanipulation.
🔄 Effiziente ETL- und Ladeprozesse
- Neue Daten können in Staging-Tabellen geladen und anschließend per
SWITCHeingehängt werden – effizient und ohne Log-Overhead. - Ideal für Data Warehouses mit nächtlichen Ladeprozessen.
🧪 Testbarkeit & Flexibilität
- Partitionen erlauben es, gezielt mit Teilmengen der Daten zu arbeiten – ideal für Entwicklungs- und QS-Umgebungen.
🛡️ Compliance & Sicherheit
- Zugriff, Verschlüsselung und Archivierung können auf Partitionsebene gesteuert werden.
- Löschprozesse nach DSGVO-Richtlinien lassen sich effizienter umsetzen.
Horizontale Partitionierung ist nicht nur ein Performance-Booster – sie ist ein strategisches Werkzeug für skalierbares Datenbankdesign, strukturierte Wartung und regulatorisch sicheres Datenmanagement. Durch gezielte Abfragen (Partition Elimination) und parallele Verarbeitung (Parallelisierung) lässt sich selbst aus großen Datenmengen maximale Effizienz herausholen.
Fazit
Partition Switching – blitzschnelles Ein- und Auslagern von Daten
Ein besonders mächtiges Feature der horizontalen Partitionierung in SQL Server ist das sogenannte Partition Switching. Dabei werden ganze Partitionen zwischen zwei Tabellen verschoben – ohne Daten tatsächlich zu kopieren, sondern durch eine reine Metadatenoperation. Das macht den Vorgang extrem schnell und ressourcenschonend.
Was ist Partition Switching?
Beim Partition Switching nutzt man zwei Tabellen:
- eine partitionierte Zieltabelle, z. B.
Sales - und eine nicht partitionierte oder gleich partitionierte Staging-Tabelle, z. B.
Sales_2023_Import
Durch einen einfachen ALTER TABLE … SWITCH PARTITION-Befehl kann man:
- neue Daten in die partitionierte Haupttabelle „einhängen“, oder
- alte Daten gezielt auslagern, z. B. zur Archivierung.
Typische Einsatzszenarien
1. Daten einfügen („Load by Switch“)
Daten für z. B. einen Monat oder ein Jahr werden in eine separate Staging-Tabelle geladen, dort geprüft und bereinigt – und danach blitzschnell in die Haupttabelle überführt:
-- Beispiel: Partition 3 (z. B. Jahr 2023) wird aus Staging übernommen
ALTER TABLE Sales_2023_Import
SWITCH TO Sales PARTITION 3;2. Archivierung alter Partitionen
Wenn z. B. die Daten aus 2022 archiviert werden sollen, kann man die entsprechende Partition elegant in eine separate Tabelle auslagern:
-- Beispiel: Partition 2 (z. B. Jahr 2022) wird ausgelagert
ALTER TABLE Sales
SWITCH PARTITION 2 TO Sales_2022_Archive;Vorteile des Switching-Verfahrens
✅ Extrem schnell: Da keine Daten verschoben werden, sondern nur Metadaten aktualisiert werden, ist Switching in Sekundenbruchteilen erledigt – auch bei Millionen von Zeilen.
✅ Keine Transaktionslast: Kein Logging, keine lange Sperrung, kein Rollback erforderlich – ideal für große Datenmengen.
✅ Sicherer Datenfluss: Daten lassen sich vor dem Switching komplett prüfen – z. B. im ETL-Prozess.
✅ Regulatorische Trennung: Daten, die archiviert oder DSGVO-konform gelöscht werden müssen, können gezielt „ausgehängt“ werden.
✅ Saubere Trennung von Verantwortung: Fachbereiche arbeiten mit klar definierten Datenbereichen, z. B. pro Jahr oder Monat.
Voraussetzungen für Partition Switching
Damit Switching funktioniert, müssen folgende Voraussetzungen erfüllt sein:
- Beide Tabellen müssen exakt gleiche Struktur haben (Spalten, Datentypen, NULL-Werte, Constraints).
- Die Daten in der Staging-Tabelle müssen vollständig in den Wertebereich der Zielpartition passen.
- Es darf kein aktivierter Trigger auf der Ziel- oder Quelltabelle vorhanden sein.
- Indizes (auch der Clustered Index!) müssen auf beiden Tabellen identisch sein.
weiterführende Links
vertikale Partitionierung
Während bei der horizontalen Partitionierung eine Tabelle zeilenweise aufgeteilt wird, erfolgt bei der vertikalen Partitionierung eine Spaltung auf Spaltenebene. Ziel ist es, Spalten mit unterschiedlichen Nutzungshäufigkeiten oder Speicheranforderungen in getrennten physischen Tabellen abzulegen.
Ein klassisches Anwendungsbeispiel ist eine Tabelle, die sowohl häufig abgefragte Geschäftsdaten als auch selten genutzte Zusatzinformationen enthält. Statt alle Spalten gemeinsam vorzuhalten, kann man die Tabelle aufteilen – beispielsweise in:
Customer_Coremit den wichtigsten Informationen wieCustomerID,Name,CountryCustomer_Extrasmit selten benötigten Spalten wieNewsletterOptInDate,LastContactNote,MarketingSegments
Beide Tabellen würden über die Primärschlüssel-Spalte (CustomerID) logisch miteinander verbunden bleiben. In der Praxis wird oft ein JOIN eingesetzt, wenn Zusatzinformationen tatsächlich benötigt werden.
Vorteile der vertikalen Partitionierung
- Performancegewinn bei Abfragen: Da in vielen Fällen nur ein Teil der Spalten abgefragt wird, reduziert sich die Menge der eingelesenen Daten signifikant.
- Reduzierter Speicherbedarf im Arbeitsspeicher: Bei In-Memory-Technologien (wie z. B. SQL Server Columnstore-Indexes) profitiert man stark von kleineren Datenseiten.
- Optimierte Indexnutzung: Indizes können gezielter und effizienter auf kleineren, fokussierten Tabellen eingesetzt werden.
Mögliche Herausforderungen
- Komplexere Abfragen: Muss auf alle Daten zugegriffen werden, sind zusätzliche
JOIN-Operationen nötig. - Datenkonsistenz sicherstellen: Änderungen müssen ggf. auf mehreren Tabellen erfolgen, was die Transaktionslogik beeinflusst.
- Wartbarkeit: Die Logik der Datenverteilung muss dokumentiert und in ETL-Prozesse integriert werden.
Wann ist vertikale Partitionierung sinnvoll?
Die vertikale Partitionierung eignet sich besonders in Fällen, in denen:
- es eine klare Trennung zwischen häufig und selten genutzten Spalten gibt,
- die Tabelle viele Spalten enthält und dadurch unhandlich wird,
- In-Memory-Technologien oder spaltenorientierte Datenhaltung verwendet werden.
Links:
- Horizontale, vertikale und funktionale Datenpartitionierung
- Special Guide for Partitioned Indexes
- Kimberly L. Tripp – Partitionierte Tabellen und Indizes in SQL Server 2005 | Powerpoint
- Kate Loguteva – SQL Server Table Paritioning: Divide and Rule
- Partitionierte Tabellen – Faktenladen mit „Fast = TRUE“ [Teil 1 | Teil 2]
- CREATE PARTITION FUNCTION (Transact-SQL)
- CREATE PARTITION SCHEME (Transact-SQL)
- Jignesh Raiyani – How to automate Table Partitioning in SQL Server
- Kendra Little – How To Decide if You Should Use Table Partitioning
- Milica Medic – Database table partitioning in SQL Server
- Partitioned Tables and Indexes



 Erhard RAINER
Erhard RAINER