Kyocera – Sharepoint – Power Automate
Wer einen mittelmäßigen Kyocera Drucker hat, wie beispielsweise den Kyocera Ecosys M6635cidn, den ich verwende, möchte vielleicht – wie ich – schon über das Scannen einen Workflow auslösen. So sollen beispielsweise alle Arztrechnungen automatisch bei der Zusatzversicherung eingereicht werden, die eingescannt werden. Bevor wir uns jetzt einem doch recht komplexen Workflow widmen, möchte ich das an einem einfacheren Beispiel demonstrieren.
In diesem etwas einfacheren Beispiel, soll nun über den Scanner (ohne weiteres Zutun) eine Datei am Sharepoint abgelegt werden und diese dann an eine bestimmte Person gesendet werden. In der Sharepoint Dokumentenbibliothek soll dann auch vermerkt werden, wann genau das Mail gesendet wurde, damit das später leichter nachvollziehbar ist.
Zuerst müssen wir die Sharepoint Bibliothek lokal syncronisieren. Dadurch wir eine lokale Kopie der Dokumentenbibliothek lokal angelegt.
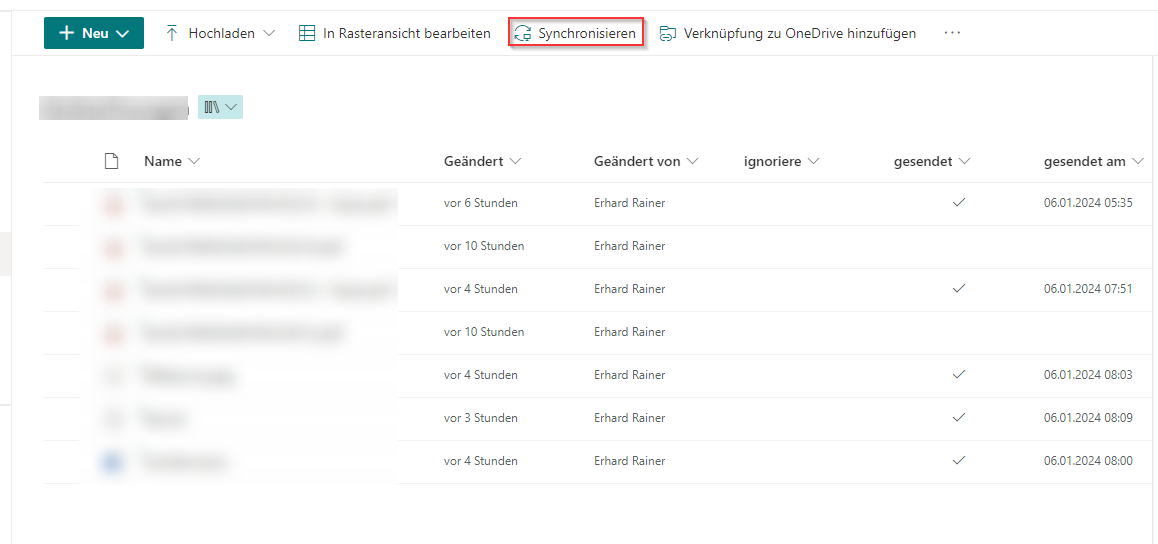
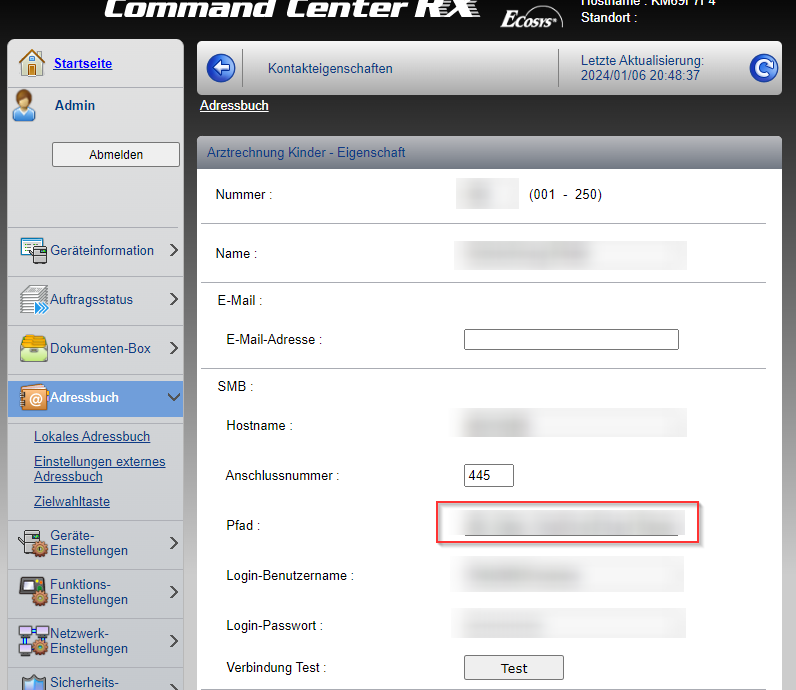
Diese lokale Kopie der Sharepoint-Bibliothek, kann man nun über das „Command Center RX“ ins Adressbuch einbinden, sei es über eine Freigabe oder über die //…/d$/…. (sog. Administrative Freigaben).
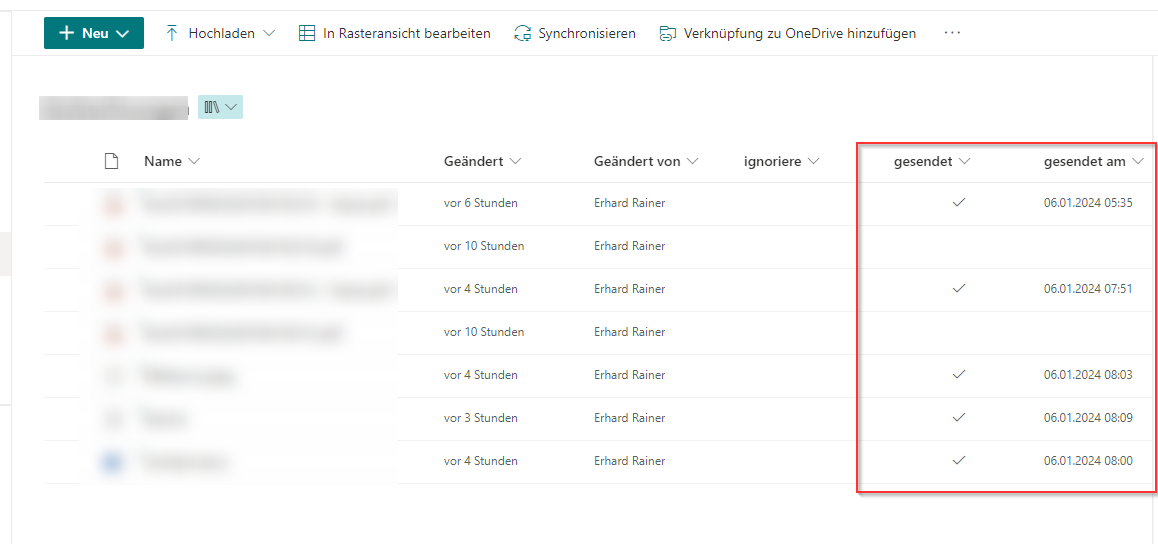
Jetzt kann man die Sharepoint Bibliothek noch um zusätzliche Spalten erweitern, wie beispielsweise gesendet (true/false) und gesendet am (Datum mit Uhrzeit)
Was wir jetzt noch brauchen ist Microsoft Flow / Power Automate, um die Datei beispielsweise zu versenden, oder noch komplexere Dinge damit anzustellen.
Ein solcher Power Automate Prozess könnte folgendermaßen aussehen:
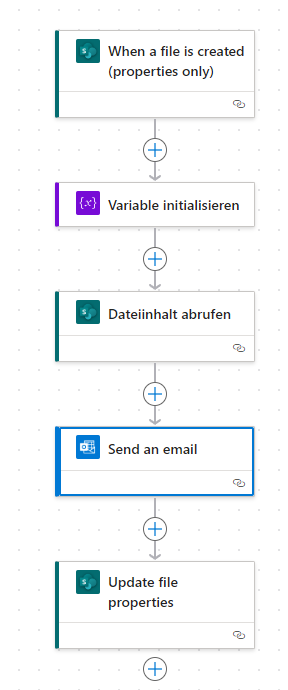
Der Teufel steckt in diesem Fall aber im Detail. Das Mail ist schnell erstellt, aber das Anhängen des Attachements hat sich als nicht ganz so einfach herausgestellt.
So kommt beispielweise bei einer Text-Datei am Sharepoint mit dem Inhalt „test“ der Inhalt „dGVzdC50eHQ=“ an:
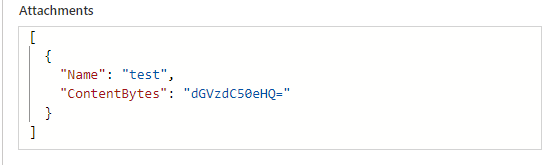
Mit „base64ToBinary(base64(body(‚Dateiinhalt_abrufen‘)))“ konnte ich es zwar bewerkstelligen, dass die Text-Datei leserlich ankam, aber nicht Bilder und auch keine PDF-Dateien. Aus 2.325KB wurden so auch 3.009KB. Und wenn man sich den Inhalt genauer ansieht, dann ist der Unterschied schnell ersichtlich:
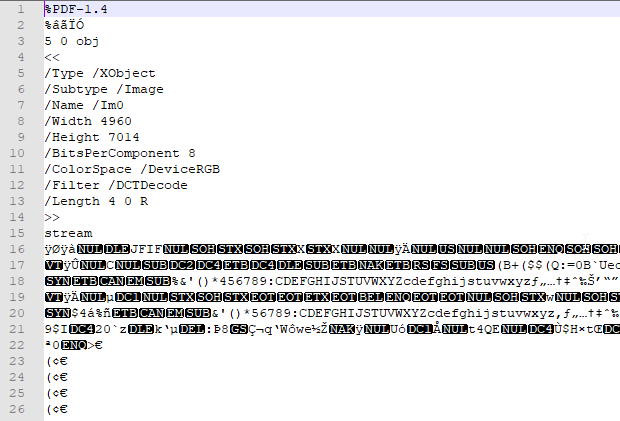
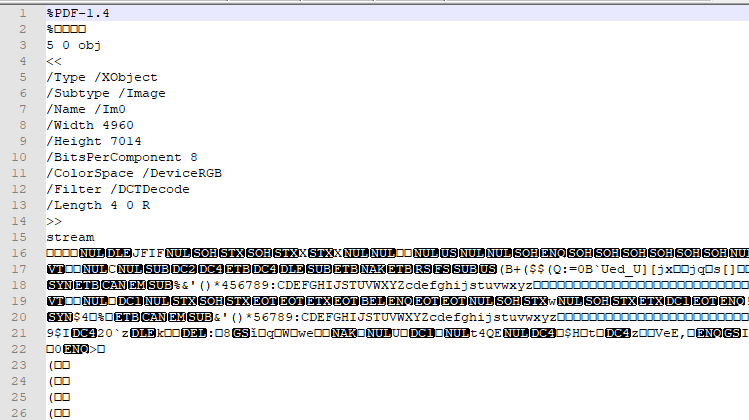
Nach einigen Versuchen habe ich festgestellt, dass ich da ohne systematische Herangehensweise nicht zu einer Lösung kommen werde. Schauen wir uns mal an, wo wir überhaupt Einstellungen vornehmen können. Einerseits bei „Get file Content“ – hier kann man „Infer Content Type“ einstellen – und anderseits beim Anhängen der Datei – hierbei kann man bezüglich der Codierung des Contents Einstellungen vornehmen.
| Infer Content Type | Content | funktioniert? |
| false | „emailMessage/Attachments“: [ { „Name“: „@{variables(‚Dateinamen‘)}“, „ContentBytes“: „@{base64(body(‚Get_file_content‘))}“ } ] | geht gar nicht |
| false | „emailMessage/Attachments“: [ { „Name“: „@{variables(‚Dateinamen‘)}“, „ContentBytes“: „@{base64ToBinary(base64(body(‚Get_file_content‘)))}“ } ] | geht nicht |
| false | „emailMessage/Attachments“: [ { „Name“: „@{variables(‚Dateinamen‘)}“, „ContentBytes“: „@{decodeBase64(base64(body(‚Get_file_content‘)))}“ } ] | geht nicht |
| false | „emailMessage/Attachments“: [ { „Name“: „@{variables(‚Dateinamen‘)}“, „ContentBytes“: „@{base64ToString(base64(body(‚Get_file_content‘)))}“ } ] | geht nicht |
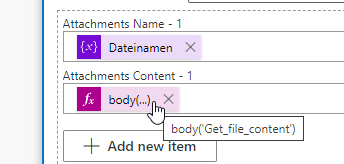
| false | „emailMessage/Attachments“: [ { „Name“: „@variables(‚Dateinamen‘)“, „ContentBytes“: „@body(‚Get_file_content‘)“ } ] | geht |
geht gar nicht = Header stimmt nicht, PDF öffnet sich gar nicht
geht nicht = öffnet ein leeres PDF-Dokument
Wie sich nach vielen Recherchen herausgestellt hat, ist das Problem im neuen Designer gelegen. Im neunen Designer konvertiert er @body(‚Get_file_content‘) immer in @{base64(body(‚Get_file_content‘))}. Und hier ist das Problem. Beim alten Designer funktioniert dies tadellos.
weiterführende Links:
- PDF attachment corrupt
- Debajit Dutta – Binary to Base64 in Microsoft Power Automate/ Microsoft Flow
- Linn Zwa Win – HANDLE BASE64 AND BINARY FILE CONTENT TYPES IN POWER AUTOMATE
- How to avoid corrupt email attachment in Power Automate
- Add multiple attachments to an approval email with Power Automate
- Content vs ContentBytes




 Erhard RAINER
Erhard RAINER